
博弈论的认识论基础 epistemic foundations of (Eric Pacuit and Olivier Roy)
首次发布于 2015 年 3 月 13 日
博弈论的基础工作旨在明确阐明该学科基本概念所依据的假设。非合作博弈论是研究在战略互动情境中的个体、理性决策行为的学科。本条目介绍了非合作博弈论的认知基础(这个研究领域被称为_认知博弈论_)。
认知博弈论将博弈中的理性决策视为与在不确定性下的理性决策本质上没有不同。正如决策理论(Peterson 2009)中所述,在博弈中做出理性选择就是根据自己的信念或信息选择“最佳”行动。在决策问题中,决策者的信念是关于一种被动的自然状态,这种状态决定了她的行动的后果。在博弈中,一个人的决策后果取决于_其他_参与情况的代理人的选择(可能还取决于自然状态)。意识到这一点——即,自己正在与试图根据自己的信念选择最佳行动的其他代理人进行互动——将_高阶信息_纳入了考虑范围。玩家的信念不再仅仅是关于被动的或外部环境。它们涉及到其他玩家的选择_和信息_。一个人对对手的期望取决于她认为其他人对她的期望,而其他人对一个给定玩家的期望取决于他们认为她对他们的期望是什么。 本条目概述了在广义决策理论视角下涉及理性决策的游戏中出现的问题。在对游戏中的信息进行一些一般性评论之后,我们介绍了在认识论博弈论和认识论逻辑中发展的形式工具,这些工具已被用于理解互动决策中高阶信息的作用。然后,我们展示了这些工具如何用于表征已知的游戏“解概念”,以便在特定信息背景下进行理性决策。在此过程中,我们强调了该领域出现的一些哲学问题。
1. 游戏的认识论视角
1.1 经典博弈论
博弈是指涉及一组自利的代理人或玩家的任何互动情况。博弈的定义特征是玩家参与了“相互依赖的决策问题”(Schelling 1960)。在经典博弈论中,博弈的数学描述包括以下组成部分:
玩家。在本条目中,我们只考虑具有有限玩家集合的博弈。我们使用 N 来表示博弈中的玩家集合,使用 i,j,...来表示其元素。
每个玩家的可行选择(通常称为行动或策略)。再次强调,我们只考虑每个玩家有有限多可行选择的游戏。
玩家对可能结果的偏好。我们将它们表示为冯·诺依曼-摩根斯坦效用函数 ui,为游戏的每个结果分配实值效用。
一个游戏可能具有许多其他结构特性。它可以被表示为单次或多阶段决策问题,也可以包括同时或随机的移动。我们从没有随机移动的战略形式游戏开始,并将在本条目中逐步介绍更复杂的游戏。在战略游戏中,每个玩家 i 可以从一组 Si(有限)的选项中进行选择,也称为行动或策略。所有玩家的选择组合,记为 s,称为策略配置或游戏结果。我们用 si 表示 s 中 i 的分量,用 s−i 表示除 i 之外的所有代理的策略配置。最后,我们用 Πi∈NSi 表示给定游戏的所有策略配置集合。将所有内容放在一起,战略游戏是一个元组 ⟨N,{Si,ui}i∈N⟩,其中 N 是一组有限的玩家,对于每个 i∈N,Si 是一组有限的行动,ui:Πi∈NSi→R 是玩家 i 的效用函数。
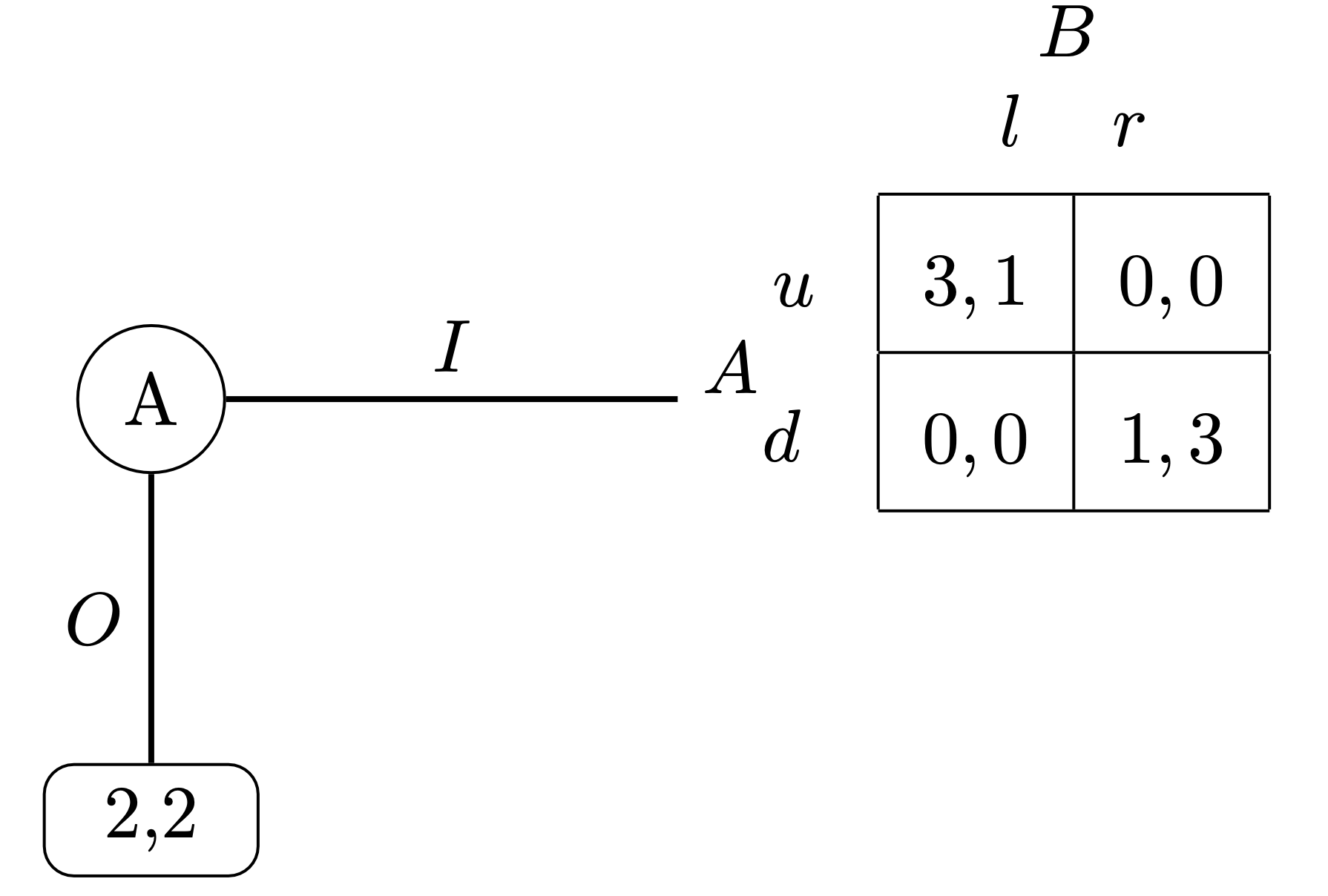
图 1 中的游戏是一个战略形式的游戏示例。有两名玩家,Ann 和 Bob,每个人都必须在两个选项之间进行选择:N={Ann,Bob},SAnn={u,d}和 SBob={l,r}。uAnn 和 uBob 的值代表他们对游戏可能结果的偏好,显示在矩阵的单元格中。例如,如果 Bob 选择 l,Ann 更喜欢通过选择 u 获得的结果,而不是选择 d 获得的结果,但是如果 Bob 选择 r,她的偏好会发生变化。这个游戏在文献中被称为“纯协调游戏”,因为玩家明确地希望协调他们的选择,即(u,l)或(d,r),但他们对于如何协调他们的选择方式却持无所谓的态度。
BobAnn
图 1:协调博弈
在一场游戏中,没有单个玩家能够完全控制最终互动结果的实现。这取决于所有玩家的决策。这种抽象的相互依赖决策模型能够代表一系列社会情境,从严格竞争到合作情境。有关古典博弈论和主要参考资料的详细信息,请参阅 Ross(2010)。
古典博弈论的中心分析工具是解概念。它们提供了一种自上而下的视角,指定了哪些游戏结果被认为是“理性的”。这可以有规范性解读或预测性解读。纳什均衡是最著名的解概念之一,但我们将在下文中遇到其他解概念。例如,在上述游戏中,有两个所谓“纯策略”纳什均衡[ 1]。这两个协调配置分别是:(u,l)和(d,r)。
从规范的角度来看,解决方案概念是一组实际建议,即关于玩家在游戏中应该做什么的建议。从预测的角度来看,解决方案概念描述了玩家在某种互动情况下实际会做什么。再次考虑上述示例中的纯策略纳什均衡。在规范解释下,它确定了玩家在游戏中应该做什么。也就是说,安和鲍勃应该选择玩他们的组件(u,l)或(d,r)。在预测解释下,这些配置文件是我们在实际游戏中预期观察到的配置文件。
对于这种以解决方案概念为驱动的游戏观点,面临着许多基础性的困难,我们在这里不进行调查。有兴趣的读者可以参考 Ross(2010)、Bruin(2010)和 Kadane&Larkey(1983)进行讨论。
1.2 认识论博弈论
认识论博弈论是一个广泛的研究领域,涵盖了许多不同的数学框架,用于分析博弈。这些框架的细节不同,但它们共享一个共同的视角。在本节中,我们讨论了这个共同视角的两个关键特点。
(1)认识论博弈论在战略情境下的决策制定中采用了广义贝叶斯观点。
这一观点由罗伯特·斯塔尔纳克(Robert Stalnaker)很好地解释了:
在多个代理人的行动决定结果的情况下,决策理性没有特殊概念。其他代理人的行为就像机会事件、自然灾害和上帝的行为一样,只是关于不确定世界的事实,代理人对此持有信念和信念程度。其他代理人的效用只有作为信息对一个代理人才相关,这些信息连同对这些代理人理性的信念一起有助于预测他们的行为。(Stalnaker 1996: 136)
换句话说,认识论博弈论可以被视为试图将博弈中的决策理论根源重新引入。
在决策理论中,决策单位是对其行动可能结果具有偏好的个体。由于给定行动的结果取决于环境的状态,决策者对环境状态的信念对评估特定决策的理性至关重要。因此,决策问题的形式描述包括可能的结果和环境状态、决策者对这些结果的偏好,以及对自然状态的信念的描述(即,决策者的信念状态)。决策理论选择规则可用于向决策者推荐她应该选择什么(或预测决策者将选择什么)。一个选择规则的标准示例是(主观)期望效用最大化,这是贝叶斯理性观的基础。它预设决策者的偏好和信念可以分别用数值效用和概率表示。[ 2](我们将推迟对此的形式表示,以及其他选择规则,如弱支配和严格支配,直到我们在第 2 节中介绍了博弈中信念的形式模型。)
从认识论的角度来看,一个游戏的经典要素(玩家、行动、结果和偏好)并不足以制定关于玩家应该或将会如何选择的建议或预测。需要明确指定玩家所处的(互动)决策问题,即玩家对彼此可能行动(和信念)的信念。在认识论博弈论中,有一个越来越流行的术语,即游戏在特定的背景下进行(Friedenberg & Meier 2010,其他互联网资源),在这个背景下,玩家对彼此具有特定的知识和/或信念。适用于一个背景的建议和/或预测可能无法转移到另一个背景,即使基本情况可能完全对应于相同的战略游戏。
(2)在认识论博弈论中,对于对手策略的不确定性成为核心。
在游戏情境中,玩家可以获得各种类型的信息。例如,玩家可能拥有关于游戏情境的特定知识。
关于游戏的玩法的不完全信息(哪些步骤已经执行?);
关于游戏结构的不完全信息(有哪些行动/回报?);
关于策略的信息(其他玩家会做什么?);
高阶信息(其他玩家在想什么?)。
尽管各种不确定性可能在认识论分析中发挥作用,认识论博弈论的一个区别特征是坚持在评估理性决策时要考虑玩家对对手行为的偏好和信念。再次,我们引用斯塔尔纳克来总结这个观点:
…在没有关于对手选择的信念程度的情况下,没有特殊的理性规则告诉你该做什么,除了这个:确定你的信念,然后最大化预期效用。(斯塔尔纳克 1996: 136)
以上介绍的游戏中的四种不确定性类型在概念上很重要,但不一定是穷尽的,也不一定是相互排斥的。例如,约翰·哈萨尼(Harsanyi 1967–68)认为,关于游戏结构的所有不确定性,即所有可能的信息不完整性,都可以归结为对收益的不确定性。类似地,卡丹和拉基(Kadane & Larkey 1982)认为,只有战略不确定性对于评估游戏情境中的决策是相关的。当代认识论博弈论认为,尽管最终可能可以归结为战略不确定性,但明确表达高阶不确定性可以澄清互动或战略理性的很多内容。
与对游戏的经典“解决方案概念”分析的关键区别在于认识论博弈论采取了自下而上的视角。一旦确定了游戏的背景,就可以根据关于玩家如何做出选择以及他们对其他人的选择了解和相信的假设,推导出理性的结果。在本节的其余部分,我们简要讨论了采用认识论视角对游戏产生的一些一般性问题。我们将高阶和战略不确定性的讨论推迟到第 3、4 和 5 节。
1.3 决策制定阶段
博弈论文献通常将决策过程分为三个阶段:ex ante、ex interim 和 ex post。一个极端是 ex ante 阶段,此时尚未做出任何决定。另一个极端是 ex post 阶段,在这个阶段,所有玩家的选择都是公开的。在这两个极端之间是 ex interim 阶段,在这个阶段,玩家已经做出了决定,但他们仍然不知道其他玩家的决定和意图。
这些区分并不是要求严格划分的。相反,它们描述了决策过程中信息披露的各个阶段。在 ex-ante 阶段,除了游戏的结构、参与者以及可能(但不一定)一些代理人的特征之外,几乎什么都不知道。在 ex-post 阶段,游戏基本上已经结束:所有玩家都已经做出了决定,这些决定现在都是不可撤销的。这并不意味着所有的不确定性都消失了,因为一个代理人可能仍然不确定其他人究竟对她期望什么。在这两个极端阶段之间有着一系列信息披露状态,我们称之为“ex-interim”阶段。这些阶段的共同之处在于代理人已经做出了_一个_决定,尽管不一定是不可撤销的。
在本条目中,我们关注决策过程的 ex interim 阶段。这与很多关于博弈论认知基础的文献一致,因为它允许直接评估代理人对对手选择的期望的理性性。关注 ex interim 阶段确实引发了一些有趣的问题,比如关于玩家的策略选择、Stalnaker(1999)所称的“主动知识”以及玩家对其他人的选择的“被动知识”之间可能存在的_相关性_。关于一个玩家在得知自己没有“理性”选择后应该如何反应、最终修改自己的决定,这是一个有趣而重要的问题,但我们在本条目中没有讨论。需要注意的是,这个问题与一个玩家在得知_其他人_没有选择理性时应该如何修正他们的信念的问题是不同的。在依次选择的游戏中,这第二个问题是非常相关的,将在 第 4.2.3 节 中讨论。
1.4 不完全信息
关于_任何_博弈情境的数学模型,一个自然的问题是_如果玩家对模型的某些参数存在不确定性,分析将如何变化?_ 这激发了 Harsanyi 在 1967-68 年引入了博弈论 类型 概念并定义了 贝叶斯博弈 的基础性工作。利用这些思想,已经发展出了广泛的文献,分析了玩家对游戏的某些方面存在不确定性的情况。(请参阅 Leyton-Brown & Shoham(2008:ch.7)对当前情况的简明总结以及相关文献的指引。)人们自然会想知道这些文献与我们在本条目中讨论的关于博弈论认知基础的文献之间的确切关系。事实上,我们在此讨论的基础性文献主要集中在对 Harsanyi 对建模高阶信念的方法(我们将在 2.3 节 中讨论)。
关于贝叶斯博弈的文献和我们在本条目中讨论的文献之间有两个关键区别(参见 Brandenburger 2010:sec.4 和 5 中的讨论)。
在贝叶斯博弈中,玩家对游戏的收益不确定,对其他玩家认为正确的收益不确定,对其他玩家认为其他玩家对收益的看法不确定,依此类推,这是唯一的不确定性来源。也就是说,玩家对游戏中收益的(高阶)信念完全决定了对游戏其他方面的(高阶)信念。特别是,如果一个玩家了解其他玩家的收益,那么该玩家对其他玩家可能的(理性)选择是确定的(并且正确的)。
假设所有玩家在给定信息的情况下都会选择最优策略。也就是说,所有玩家选择的策略会最大化他们对游戏的预期效用,考虑到他们对游戏的信念,对其他玩家对游戏的信念,依此类推。这意味着,特别是玩家不会考虑到他们的对手可能会“非理性”地选择。
请注意,这些假设并不是哈尔萨尼在不完全信息博弈中用来表示玩家信念的形式化的固有特征。相反,更好地描述它们是哈尔萨尼和随后研究贝叶斯博弈的研究人员遵循的惯例。
1.5 不完全信息和完美回忆
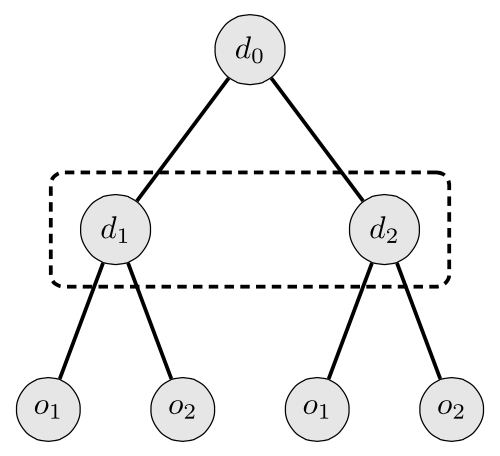
在一场存在不完全信息的博弈中(参见 Ross 2010 进行讨论),玩家可能无法完全了解对手的动作或自然机会动作的结果。存在不完全信息的游戏可以如下图所示:
![a diagram with a single circle, a node,
图 2
解释是指在第一个节点(d0)做出的决策被遗忘,因此决策者对自己是在节点 d1 还是 d2 上存在不确定性。有关带有不完全信息的一般博弈理论,请参阅 Osborne(2003 年:第 9 章和第 10 章)。在本节中,我们简要讨论了在带有不完全信息的博弈中出现的一个基础问题。
Kuhn(1953 年)在带有不完全信息的博弈中引入了完全回忆和不完全回忆之间的区别。粗略地说,只要玩家记得自己过去的所有行动(参见 Bonanno 2004; Kaneko&Kline 1995,对完全回忆假设的一般讨论),他们就具有完全回忆。在博弈理论文献中,通常假设所有玩家都具有完全回忆(即,他们可能对对手或自然的先前选择感到不确定,但他们确实记得自己的行动)。
正如我们在第 1.3 节中指出的,决策过程有不同的阶段。在具有时间维度的广泛博弈中,这些阶段之间的差异变得更加明显。在带有不完全信息的广泛博弈中,有两种方式来思考决策过程。第一种是专注于初始的“规划阶段”。也就是说,最初,玩家们确定一种策略,指定他们在每个选择节点上将要采取的(可能是随机的)行动(这是玩家们的全局策略)。然后,玩家们开始进行各自的行动(按照他们已经承诺的策略进行,而不重新考虑每个选择节点上的选项)。或者,我们可以假设玩家在每个选择节点上做出“局部判断”,始终选择根据当前可用信息而言最佳的选项。Kuhn(1953 年)的一个著名定理表明,如果玩家具有完全回忆,则策略在全局上是最优的,当且仅当它在局部上是最优的(参见 Brandenburger 2007,对这一经典结果的自包含演示)。也就是说,在广泛博弈(带有不完全信息)中,对决策过程的这两种方式都会得出相同的建议/预测。
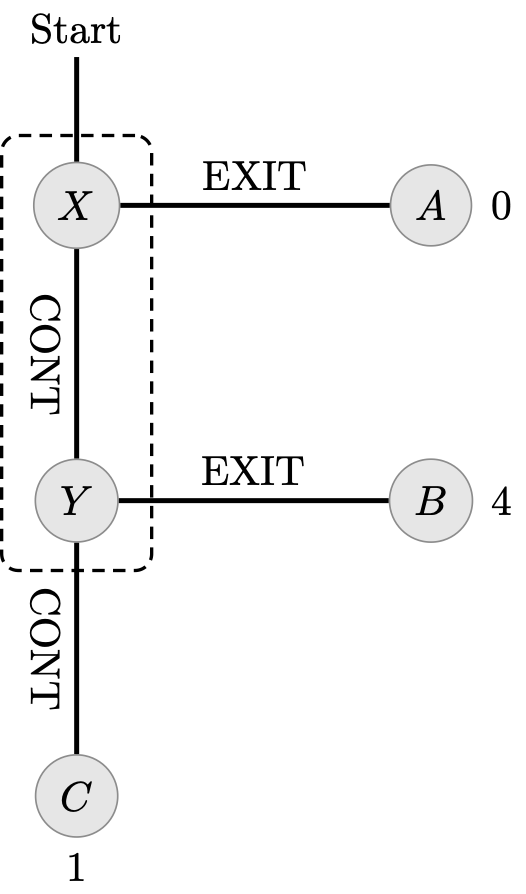
完美回忆的假设对于库恩的结果至关重要。这一点可以通过皮西奥内和鲁宾斯坦(1997a)著名的健忘司机问题来证明。有趣的是,他们的例子是一个决策者在初始规划阶段之后可能会被诱导改变策略的情况,尽管没有获得新的信息。他们如下描述了这个例子:
一个人在深夜坐在酒吧里计划他的午夜回家之行。为了回家,他必须上高速公路并在第二个出口下车。在第一个出口转弯会进入一个灾难性的区域(收益为 0)。在第二个出口转弯会获得最高的回报(收益为 4)。如果他继续超过第二个出口,他将无法返回,并且在高速公路的尽头他会找到一个汽车旅馆,在那里他可以过夜(收益为 1)。这位司机健忘,并且意识到这一事实。在一个十字路口,他无法判断是第一个还是第二个十字路口,也无法记住他已经经过了多少个(可以通过提到第 17 个十字路口使情况更加真实)。在酒吧里坐着时,他所能做的就是决定是否在十字路口下车。(皮西奥内和鲁宾斯坦 1997a:7)
健忘司机的决策树如下图所示:
![a diagram with the word 'start' at the
图 3
这个问题很有趣,因为它表明决策者在酒吧计划时所承诺的行为与他在第一个十字路口认为最好的行为之间存在冲突:
计划阶段:在酒吧计划回家的路上时,决策者面临选择“继续;继续”和“退出”。由于他无法区分两个十字路口,他无法计划在第二个十字路口“退出”(他必须在 X 和 Y 处计划相同的行为)。由于“退出”会导致最糟糕的结果(收益为 0),最佳策略是“继续;继续”,保证收益为 1。
行动阶段:当到达一个十字路口时,决策者面临着一个本地选择,要么“退出”,要么“继续”(可能会跟随另一个决策)。现在决策者知道,由于他承诺在每个十字路口选择“继续”的计划,他有可能在第二个十字路口。事实上,决策者得出结论,他以 1/2 的概率在第一个十字路口。但是,他选择“退出”的预期回报是 2,这比他之前承诺的策略所保证的回报更大。因此,他选择“退出”。
这个问题已经被许多不同的研究者讨论过[4]。本文的范围不包括讨论不同分析的复杂性。《游戏与经济行为》(1997 年第 20 卷)的整个一期专门讨论了这个问题。有关这个问题的不同方法的代表性样本,请参见 Kline(2002);Aumann,Hart 和 Perry(1997);Board(2003);Halpern(1997);Piccione 和 Rubinstein(1997b)。
1.6 混合策略
混合策略在许多博弈论分析中起着重要作用。让 Δ(X)表示有限集合 X 上的概率测度集。对于玩家 i 的混合策略,是 Si 中的一个元素 mi∈Δ(Si)。如果 mi∈Δ(Si)将概率分配为 1 给 Si 中的元素 si∈Si,则 mi 被称为纯策略(在这种情况下,我写 si 代替 mi)。混合策略被纳入博弈论分析如下。假设 G=⟨N,{Si,ui}i∈N⟩ 是一个有限的战略博弈。G 的混合扩展是战略博弈,其中玩家 i 的策略是 G 中的混合策略(即 Δ(Si)),并且联合混合策略 m∈Πi∈NΔ(Si)的玩家 i 的效用(表示为 Ui)以明显的方式计算(对于 s∈Πi∈NSi,让 m(s)=m1(s1)⋅m2(s2)⋯mn(sn)):
Ui(m)=∑s∈Πi∈NSim(s)⋅ui(s)
因此,游戏 G 的混合扩展的解空间是集合 Πi∈NΔ(Si)。
尽管在博弈论中占据重要地位,混合策略的解释存在争议,正如 Ariel Rubinstein 所指出的:
我们不愿意相信我们的决策是随机做出的。我们更愿意能够为我们采取的每个行动指出一个理由。除了拉斯维加斯,我们不会转动轮盘。(Rubinstein 1991: 913)。
在认识论博弈论中,更自然的是采用混合策略的另一种解释:对于玩家 i 来说,混合策略是对 i 的对手对她将会采取什么行动的信念的一种表达。这在 Robert Aumann 的具有影响力的论文中得到了很好的解释(Aumann 1987—特别是该论文第 6 节对混合策略解释的讨论)。
我们方法的一个重要特点是,它不需要玩家明确地进行随机选择。每个玩家总是选择一个确定的纯策略,没有尝试随机选择;策略的概率性反映了其他玩家对他选择的不确定性。(Aumann 1987: 3)
2. 游戏模型
游戏模型是一个代表给定游戏的信息背景的结构。游戏模型中的状态或可能的世界描述了游戏的可能进行以及影响玩家选择的具体信息(在每个状态可能不同)。这包括每个玩家对自己选择的“知识”以及对对手选择的“信念”的看法。构建游戏模型时的一个关键挑战是如何表示玩家的不同信息态度。对决策理论、认识论和信念逻辑的基础以及最近的形式认识论感兴趣的研究人员已经发展了许多不同的形式模型,可以描述评估决策或游戏理论情境中理性代理人选择的重要信息态度的多种变体。
在讨论描述游戏信息背景时出现的一些一般性问题后,我们介绍了两种主要模型,用于描述游戏情境中玩家的信念(和其他信息态度):类型空间(Harsanyi 1967–68; Siniscalchi 2008)和所谓的奥曼-或克里普凯结构(Aumann 1999a; Fagin, Halpern, Moses, & Vardi 1995)。尽管这两种方法有很多共同之处,但下面我们将突出一些重要的区别。文献中发现的第二个更基本的区别是“定量”结构和“定性”结构之间的区别,前者代表“分级”态度(通常通过概率分布表示),后者代表“全面”态度。克里普凯结构通常与前者相关联,而类型空间与后者相关联,但这并不是严格的分类。
2.1 一般问题
2.1.1 信息态度的种类
游戏的信息背景可以包括各种形式的态度,从经典的知识和信念到坚定的(Stalnaker 1994)和强烈的(Battigalli&Siniscalchi 2002)信念,每种都在不同的博弈理论合理性概念中回响。本文不涉及调查这一庞大文献的细节(有关此文献的讨论,请参见下一节)。相反,我们将介绍硬态度和软态度之间的一般区别,这一区别主要在动态认知逻辑(van Benthem 2011)中得到发展,这对于理解认知博弈理论引发的各种哲学问题非常有用。
我们称之为硬信息的信息是真实的、完全内省的,且不可修改的。这个概念旨在捕捉在给定的互动情况下,代理人完全且正确地确定的内容。例如,在临时阶段,玩家对自己的选择有硬信息。他们“知道”他们选择了哪种策略,他们知道他们知道这一点,没有新的信息可以让他们改变对此的看法。正如这种措辞所暗示的,术语“知识”经常被用来描述这种非常强大的信息态度,因为没有更好的术语。认知逻辑学家和博弈论家都很清楚这种硬“知识”与我们直观甚至哲学上对这一概念的理解之间可能存在的差异。在当前情境中,观察到硬信息与认知博弈理论中所谓的反直觉特性更为有益,而不是在最后否定这一概念为错误或有缺陷。
软信息大致上是指任何不是“硬”的东西:它不一定是真实的,也不一定是完全内省的,或者在有新信息的情况下可以高度修改。因此,它更接近于信念。再次强调,这里需要哲学上的谨慎。被标记为“信念”的整个信息态度范围确实属于可以描述为“将某事视为真实”的态度(Schwitzgebel 2010),其中信念在哲学意义上似乎构成一个适当的子类别。
2.1.2 可能世界模型
下面介绍的模型描述了互动情境中玩家的硬信息和软信息。它们在对世界状态的表示上有所不同,但都可以广义地描述为“可能世界模型”,这在许多哲学逻辑文献中是常见的。起点是一个非空(有限或无限)的自然状态集合 S,描述了不依赖于代理人不确定性的外生参数(即关于物理世界的事实)。除非另有规定,S 是游戏可能结果的集合,也是所有策略剖面的集合。[6] 每个玩家被假定持有一些可能性,称为可能世界或简称(认识论)状态。这些“可能性”旨在代表游戏情境可能发展的一种方式。因此,每种可能性将与唯一的自然状态相关联(即,存在从可能世界到自然状态的函数,但这个函数不一定是一一对应的,甚至不一定是到达的)。对于游戏中的理性分析来说,可能存在与相同自然状态相关联的不同可能世界是至关重要的。这些可能世界很重要,因为它们为代表不同的信息状态打开了大门。这种基于状态的建模自然地产生了对代理人信息态度的命题观点。代理人将对命题(在博弈论文献中也称为事件)持有信念/知识,并表示为可能世界的集合。这些基本建模选择并不是毫无争议的,但这些问题并不是我们在本条目中关心的问题。
2.2 关系模型
我们从对哲学逻辑学家(van Benthem 2010)和计算机科学家(Fagin 等,1995)熟悉的模型开始。这些模型是由罗伯特·奥曼(Robert Aumann)在他的开创性论文《不同意就别再争了》(Agreeing to Disagree)中引入到博弈论中的(参见 Vanderschraaf & Sillari,2009,第 2.3 节,讨论了这一结果)。首先,一些术语:假设 W 是状态或可能世界的集合,让我们将任何子集 E⊆W 称为 事件 或 命题。给定事件 E⊆W 和 F⊆W,我们使用标准的集合论符号表示交集(E∩F,读作“E 和 F”)、并集(E∪F,读作“E 或 F”)和(相对)补集(−E,读作“非 E”)。我们说事件 E⊆W 在状态 w 上发生,如果 w∈E。这些术语对于研究以下模型至关重要。
定义 2.1(认知模型) 假设 G 是一个战略博弈,S 是 G 的策略剖面的集合,N 是玩家的集合。一个 基于 S 和 N 的认知模型 是一个三元组 ⟨W,{Πi}i∈N,σ⟩,其中 W 是一个非空集合,对于每个 i∈N,Πi 是 W 上的一个分割[7],σ:W→S。
认知模型以可能的游戏状态和代理人对它们的硬信息的可能配置来表示给定游戏的信息背景。函数 σ 将每个可能的世界映射到一个独特的游戏状态,其中每个基本事实都是真或假。如果 σ(w)=σ(w′),则两个世界 w、w′ 在所有基本事实上将保持一致(即玩家将选择什么行动),但是,关键的是,代理人们在其中可能拥有不同的信息。因此,W 的元素比 S 的元素_更丰富_(关于这一点稍后会详细说明)。 给定状态 w∈W,单元 Πi(w)被称为第 i 个代理的信息集。按照标准术语,如果 Πi(w)⊆E,则我们说代理 i 在状态 w 下知道事件 E。给定事件 E,代理 i 知道 E 的事件表示为 Ki(E)。形式上,我们为每个代理 i 定义一个知识函数,将事件 E 分配给代理 i 知道的事件:
定义 2.2(知识函数)设 M=⟨W,{Πi}i∈N,σ⟩ 是一个认知模型。基于 M 的代理 i 的知识函数是 Ki:℘(W)→℘(W),具体为:
Ki(E)={w∣Πi(w)⊆E}
对于任意集合 X,℘(X)是 X 的幂集。
备注 2.3 通常更方便使用等价关系而不是分割。在这种情况下,基于 S 和 N 的认识模型也可以定义为三元组 ⟨W,{∼i}i∈N,σ⟩,其中 W 和 σ 如上所述,对于每个 i∈N,∼i⊆W×W 是自反的、传递的和对称的。给定这样的模型 ⟨W,{∼i}i∈N,σ⟩,我们写
[w]i={v∈W∣w∼iv}
对于等价类 w。由于等价关系和分割之间存在一一对应关系,[ 8]我们将滥用符号,并交替使用 ∼i 和 Πi。
应用上述备注,Ki(E)的另一种定义是,E 在代理 i 认为可能的所有状态中都为真(根据 i 的硬信息)。也就是说,Ki(E)={w∣[w]i⊆E}。
分割或等价关系旨在表示每个状态下代理的硬信息。众所周知,知识运算符满足认知逻辑 S5 的性质(有关讨论,请参见 Hendricks & Symons 2009)。我们不在这里讨论这些相关问题,而是专注于这些模型如何用于提供游戏的信息背景。
一个例子。考虑安(player 1)和鲍勃(player 2)之间的协调博弈。众所周知,存在两个纯策略纳什均衡((u,l)和(d,r))。
BobAnn
图 4:安和鲍勃之间的战略协调游戏
对于我们来说,玩家的效用在这个阶段并不重要。为了构建这个游戏的认识模型,我们首先需要指定我们将考虑哪些自然状态。为简单起见,将它们视为策略配置的集合 S={(u,l),(d,l),(u,r),(d,l)}。代理的集合当然是 N={A,B}。那么状态集 W 将是什么?我们首先假设 W=S,因此每个自然状态对应一个可能的世界。这并非一定如此,但在这里这将有助于说明我们的观点。
我们可以使用许多不同的分区来完成对这个简单认识模型的描述。然而,并非所有的分区都适用于分析决策过程的 ex interim 阶段。例如,假设 ΠA=ΠB={W},考虑表示安选择 u 的事件 U={(u,l),(u,r)}。请注意,由于对于所有 w∈W,ΠA(w)⊈U,所以 KA(U)=∅,因此没有状态可以让安知道她选择了 u。这意味着这个模型适用于推理 ex ante 阶段而不是 ex interim 阶段。这可以通过额外的技术假设轻松解决:假设 S 是某个(战略或广义)游戏的策略配置集合,玩家为 N={1,…,n}。
一个模型 M=⟨W,{Πi}i∈N,σ⟩ 被称为是一个 ex interim 认识模型,如果对于所有的 i∈N 和 w,v∈W,如果 v∈Πi(w)那么 σi(w)=σi(v)
其中 σi(w)是由 σ 分配给 w 的策略配置 s∈S 的第 i 个组成部分。一个具有状态 W 的 ex interim 认识模型的例子是:
ΠA={{(u,l),(u,r)},{(d,l),(d,r)}} and
ΠB={{(u,l),(d,l),(u,r),(d,r)}}.
请注意,这只是将图 1 中的博弈矩阵重新解释为一个认识模型,其中行是安的信息集,列是鲍勃的信息集。除非另有说明,我们将始终假设我们的认识模型是 ex interim 的。ex interim 认识模型的类别非常丰富,其中的模型描述了代理人对自己选择的(困难的)信息,其他玩家的(可能的)选择以及关于这些决定的更高阶(困难的)信息(例如,“安知道鲍勃知道…”)。
现在我们更详细地看一下上面描述的认识模型。我们经常使用以下图形表示模型以便更容易阐述。状态由图中的节点表示,当 wi 和 wj 在同一分区单元中时,状态 wi 和 wj 之间有(无向)边。我们使用实线标记为 A 表示安的分区,使用虚线标记为 B 表示鲍勃的分区(为简单起见,不表示自反边)。事件 U={w1,w3}代表命题“安决定选择选项 u”的阴影灰色区域。
![a diagrom of four circles in a square.
图 5
请注意,以下事件在所有状态下都是真实的:
−KB(U): “Bob does not know that Ann decided to choose u”
KB(KA(U)∨KA(−U)): “Bob 知道 Ann 知道她是否决定选择 u”
KA(−KB(U)): “Ann 知道 Bob 不知道她是否决定选择 u”
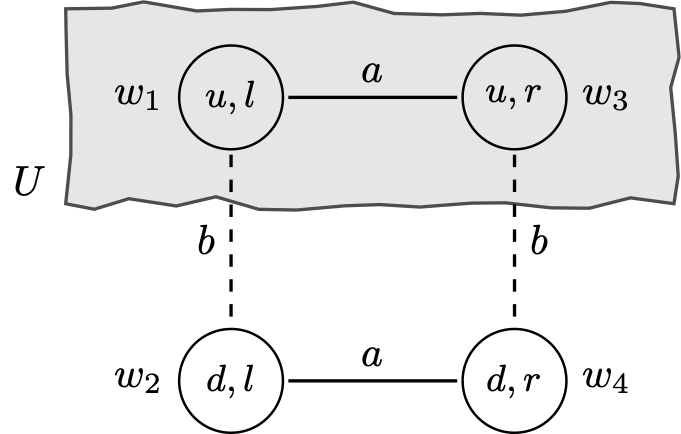
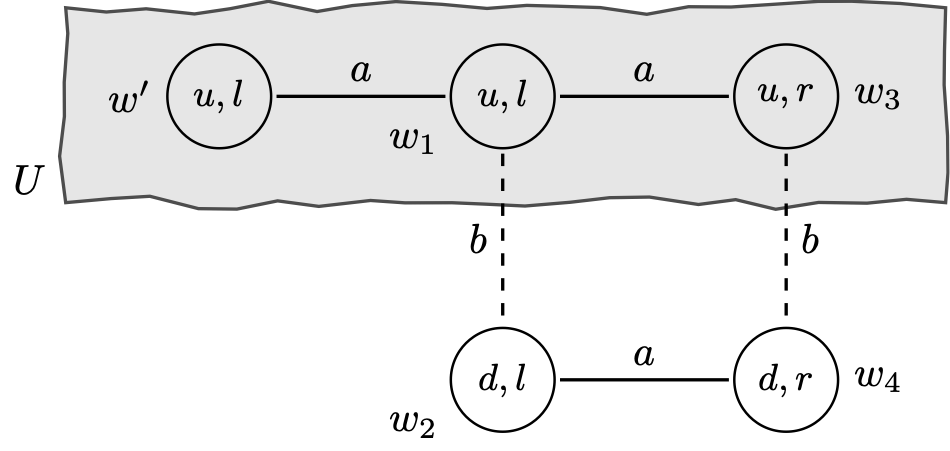
特别是,在 Ann 决定选择 u 的状态 w1 中,这些事件是真实的(即 w1∈U)。第一个事件在 ex interim 阶段关于可用信息的假设下是有意义的:每个玩家都知道自己的选择,但不知道其他玩家的选择。第二个事件是关于可用信息的另一个假设的具体例子:Bob 拥有 Ann 已经做出某种选择的信息。但是,是什么使 Ann 得出结论 Bob 不知道她选择了 u(第三个事件)?这是关于 Ann 知道 Bob 对她的期望的一个更重要的陈述。实际上,在某些情境下,Ann 可能有很好的理由认为 Bob 实际上知道她会选择 u 是可能的。我们可以找到一个 ex interim 认识模型,在这个事件(−KA(−KB(U)))在 w1 处为真,但这需要添加一个新的可能世界:
![a diagrom of four circles in a square and
图 6
注意,由于 ΠB(w′)={{w′}}⊆U,我们有 w′∈KB(U)。也就是说,Bob 知道 Ann 在状态 w′选择了 u。最后,一个简单的计算表明 w1∈−KA(−KB(U)),正如所期望的那样。当然,我们可以质疑模型中内置的其他实质性假设(例如,在 w1 处,Bob 知道 Ann 不知道他会选择 L),并继续修改模型。这引发了一系列有趣的概念和技术问题,我们将在第 7 节中讨论。
2.2.1 添加信念
Plausibility Orderings
** 信念的一个关键方面尚未在上述模型中得到体现,即在新信息的存在下,它们是可修订的。虽然关于“AGM”风格的信念修订理论有大量文献(Alchourrón, Gärdenfors, & Makinson 1985),但我们关注的是如何扩展认知模型,以表示更柔和、可修订的信息态度。标准方法是为每个代理人包括一个可信度排序:一个预序(自反和传递),表示为 ⪯i⊆W×W。如果 w⪯iv,我们说“玩家 i 认为 w 至少和 v 一样可信”。对于事件 X⊆W,让**
A key aspect of beliefs which is not yet represented in the above models is that they are revisable in the presence of new information. While there is an extensive literature on the theory of belief revision in the “AGM” style (Alchourrón, Gärdenfors, & Makinson 1985), we focus on how to extend an epistemic model with a representation of softer, revisable informational attitudes. The standard approach is to include a plausibility ordering for each agent: a preorder (reflexive and transitive) denoted ⪯i⊆W×W. If w⪯iv we say “player i considers w at least as plausible as v.” For an event X⊆W, let
Min⪯i(X)={v∈W | v⪯iw for all w∈X }
根据 ⪯i,将 X 的最小元素集合表示为 Min⪯i(X)。因此,虽然 ∼i 根据代理人的硬信息将可能世界进行了划分,但是偏好序关系 ⪯i 表示代理人认为哪个可能世界更有可能发生(即代表了玩家的软信息)。
定义 2.4(认知-偏好模型)假设 G 是一个战略博弈,S 是 G 的策略配置集合,N 是玩家集合。认知-偏好模型是一个元组 ⟨W,{Πi}i∈N,{⪯i}i∈N,σ⟩,其中 ⟨W,{Πi}i∈N,σ⟩ 是一个认知模型,σ:W→S,对于每个 i∈N,⪯i 是 W 上的一个良基[9]、自反且传递的关系,满足以下性质,对于所有的 w,v∈W。
可能性暗示着可能性:如果 w⪯iv,则 v∈Πi(w)。
局部连接:如果 v∈Πi(w),则要么 w⪯iv,要么 v⪯iw。
备注 2.5 请注意,如果 v∉Πi(w),则 w∉Πi(v)。因此,根据属性 1,w⪯̸iv 且 v⪯̸iw。因此,我们有以下等价关系:v∈Πi(w)当且仅当 w⪯iv 或 v⪯iw。
本地连通性意味着 ⪯i 完全排序 Πi(w),而良基性意味着 Min⪯i(Πi(w))非空。这个更丰富的模型使我们能够正式定义各种(软)信息态度。我们首先需要一些额外的符号:可信度关系 ⪯i 可以如下扩展到 W 的子集[10]
X⪯iY 当且仅当对于所有的 x∈X 和 y∈Y,有 x⪯iy
假设 M=⟨W,{Πi}i∈N,{⪯i}i∈N,σ⟩ 是一个认知-可信度模型,考虑以下运算符(形式上,每个运算符都是从 ℘(W) 到 ℘(W) 的函数,类似于上面定义的知识运算符):
信念:Bi(E)={w∣Min⪯i(Πi(w))⊆E} 这是通常的信念概念,满足上述讨论的标准属性(例如,一致性,积极和消极内省)。
Robust Belief: Bri(E)={w∣v∈E, for all v with w⪯iv} 因此,如果 E 在所有比当前世界更有可能的世界中都是真实的,那么 E 就是强大的信念。这种更强的信念概念有些作者也称之为确定性(参见 Shoham & Leyton-Brown 2008: sec. 13.7)。
强信念:* Bsi(E)={w∣E∩Πi(w)≠∅ and E∩Πi(w)⪯i−E∩Πi(w)} 因此,只要它在认识论上是可能的,并且代理 i 认为 E 中的任何状态比 E 的补集中的任何状态更合理,那么 E 就被强烈认为是真实的。
不难看出,如果代理 i 知道 E,那么 i(强烈地)相信 E。然而,关于这些不同概念之间的逻辑关系还有更多可以说的(有关这些概念的逻辑已经被 Alexandru Baltag 和 Sonja Smets 在一系列文章中广泛研究,有关参考文献,请参阅 Baltag & Smets 2009 的其他互联网资源)。
正如前面所指出的,这些信息态度的一个关键特征是它们可能会被适当的证据所推翻。事实上,我们可以用能够促使代理人调整其信念的证据类型来描述这些态度。为了准确地描述这一点,我们引入了条件信念的概念:假设 M=⟨W,{Πi}i∈N,{⪯i}i∈N,σ⟩ 是一个认知-合理性模型,E 和 F 是事件,那么条件信念算子的定义如下:
BFi(E)={w∣Min⪯i(F∩Πi(w))⊆E}
因此,“BFi”编码了当代理 i 收到(可能具有误导性的)证据表明 F 为_真_时,他将相信什么。
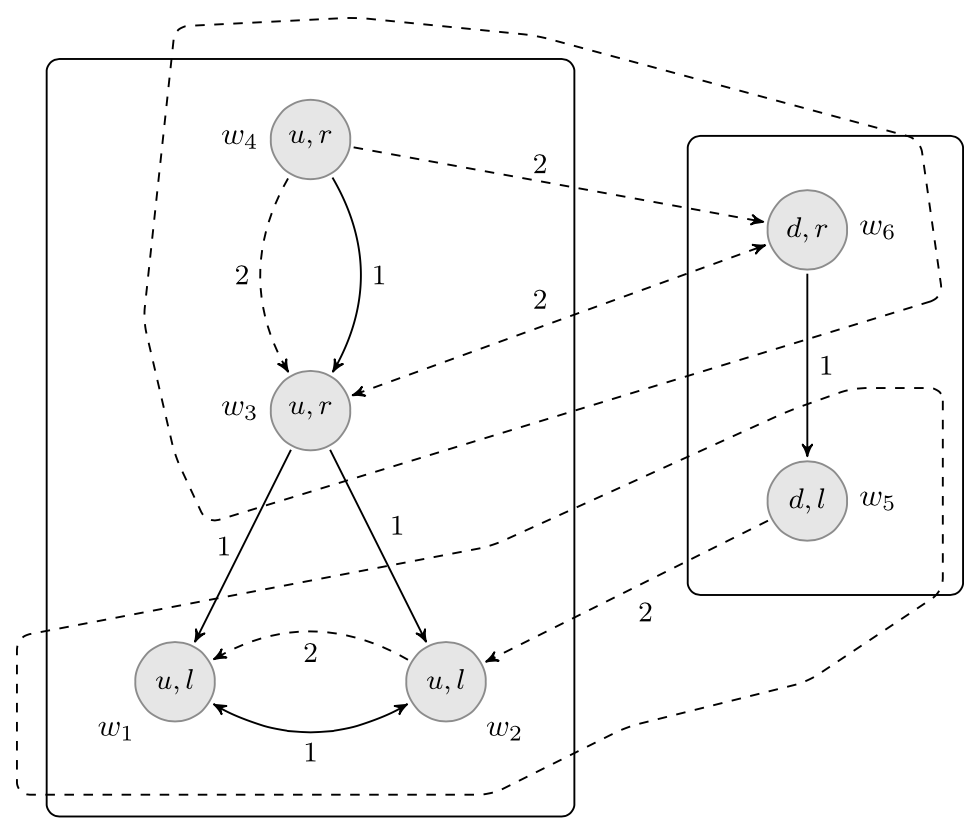
我们用一个例子来总结本节以说明上述概念。再次回想一下 图 4 中的协调游戏:对于玩家 1(安),有两种行动选择 u 和 d,对于玩家 2(鲍勃),有两种行动选择 r 和 l。再次强调,玩家的偏好(或效用)在这个阶段并不重要,因为我们只关心描述玩家的信息。下面的认知-可能性模型是与这个游戏相关的玩家信息态度的一种可能描述。实线代表玩家 1 的信息态度,虚线代表玩家 2 的信息态度。箭头对应于玩家的可能性排序,从 w 到 v 的 i-箭头表示 v⪯iw(我们没有绘制所有的箭头:每个可能性排序可以通过填充由自反性和传递性导致的箭头来完善)。不同的区域代表了玩家的硬信息。
![a diagram of six circles labelled w\1
图 7
假设实际的局势是 w4。因此,玩家 1(Ann)选择 u,玩家 2(Bob)选择 r。此外,假设 L={w1,w2,w5}是玩家 2 选择 l 的事件(对于 U、D 和 R 也是类似)
B1(L): “玩家 1 相信玩家 2 正在选择 L”
B1(B2(U)): "玩家 1 相信玩家 2 相信玩家 1 选择 u"
BR1(−B2(U)): "假设玩家 2 选择 r,玩家 1 相信玩家 2 不相信她选择 u"
这个最后的公式很有趣,因为它“预先编码”了玩家 1 在得知玩家 2 选择 R 后的信念。请注意,在接收到这个真实信息后,玩家 1 放弃了她相信玩家 2 相信她选择 u 的信念。如果语言中有一些陈述只揭示了关于玩家策略选择的部分信息,情况可能会更有趣。假设 E 是事件{w4,w6}。现在在 w4 处 E 为真,并且玩家 2 相信在 E 为真的情况下玩家 1 选择 d(即 w4∈BE2(D))。因此,玩家 1 可以通过揭示真实(尽管是部分的)信息 E 来“虚张声势”。
** 概率**
上述模型使用了“清晰”的不确定性概念,即对于每个代理和状态 w,任何其他状态 v∈W 要么可能要么更可能发生于 w。然而,有大量文献集中在分级或定量的不确定性模型上(Huber 2009; Halpern 2003)。例如,在博弈论文献中,通常用概率来表示玩家的信念(Aumann 1999b; Harsanyi 1967–68)。这个想法很简单:用概率分布替换可能性排序:
定义 2.6(认识-概率模型)假设 G 是一个战略博弈,S 是 G 的策略配置集合,N 是玩家集合。认识-概率模型是一个元组
M=⟨W,{∼i}i∈N,{Pi}i∈N,σ⟩
其中 ⟨W,{Πi}i∈N,σ⟩ 是一个认识模型,而
Pi:W→Δ(W)Δ(W)={p:W→[0,1]∣p is a probability measure}
为每个状态分配在 W 上的概率测度。在状态 w 时,将 pi 的概率测度写为 pwi。我们做出两个自然的假设(参见定义 2.4):
对于所有 v∈W,如果 pwi(v)>0,则 pwi=pvi;和
对于所有 v∉Πi(w),pwi(v)=0。
特性 1 表明,如果 i 在状态 w 处为状态 v 分配了非零概率,则代理在两个状态下使用相同的概率测度。这意味着玩家“知道”他们自己的概率测度。第二个特性意味着玩家必须将所有当前(硬)信息单元之外的状态的概率分配为零。这些模型非常精确地描述了玩家的硬信息和软信息态度。但是,请注意,编写模型需要我们为每个分区单元指定不同的概率测度,这可能相当麻烦。幸运的是,上述定义中的特性意味着,对于每个代理,我们可以将代理的概率测度视为通过条件化产生于一个概率测度。形式上,对于每个 i∈N,代理 i 的(主观)先验概率是 Δ(W)中的任何元素 pi∈Δ(W)。然后,为了定义一个认识-概率模型,我们只需要为每个 i∈N 给出(1)一个先验概率 pi∈Δ(W)和(2)一个关于 W 的分区 Πi,使得对于每个 w∈W,pi(Πi(w))>0。然后,对于每个 i∈N,概率测度被定义为:
Pi(w)=pi(⋅∣Πi(w))=pi(⋅∩Πi(w))pi(Πi(w))
当然,对于每个 w∈W,pi(Πi(w))>0 的附加条件很重要,因为我们不能除以零——这将在后面的章节中更详细地讨论。实际上,(假设 W 是有限的[11])对于任何认识-可能性模型,我们可以找到对于每个代理的先验(可能对于不同的代理是不同的),这些先验可以生成上述描述的模型。这不仅仅是一个技术性的观察:这意味着我们假设玩家对情况的结果的信念是固定的 ex ante,而 ex interim 的信念是通过在代理的硬信息上进行条件化得出的。(有关存在共同先验时的情况的广泛讨论,请参见 Morris 1995。)我们将在文本中多次提到这些关键假设。
正如上文所述,我们可以定义信念算子,这次要指定代理人相信事件的确切程度:
概率信念:Bri(E)={w∣pwi(E)=r} 在这里,r 可以是单位区间内的任意实数;然而,通常足够限制注意力在单位区间内的有理数。
完全信念:Bi(E)=B1i(E)={w∣pwi(E)=1} 因此,完全信念被定义为概率为一的信念。尽管存在一些众所周知的概念上的困难(详见 Huber 2009 对此及相关问题的广泛讨论),但这在这个文献中是一个标准假设。有时候,使用以下对完全信念的替代描述也是有用的(使其具有更多的“模态”风格):当且仅当 i 在状态 w 上分配正概率的所有状态都在 E 中时,代理 i 相信 E。形式上, Bi(E)={w∣ 对于所有的 v,如果 pwi(v)>0,则 v∈E}
这些模型也经过了复杂的逻辑分析(Fagin, Halpern, & Megiddo 1990; Heifetz & Mongin 2001),补充了上述讨论的逻辑框架(cf. Baltag & Smets 2006)。
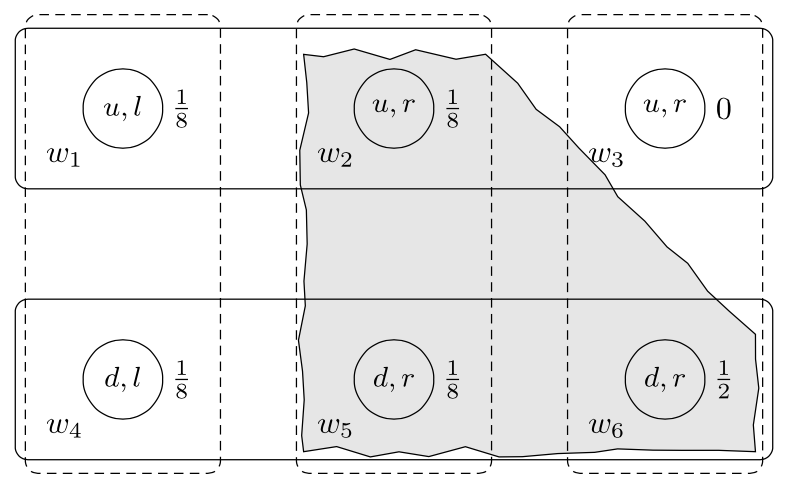
我们用一个认知-概率模型的例子结束本节。再次回顾图 4 中的协调博弈:玩家 1(Ann)有两个行动 u 和 d,玩家 2(Bob)有两个行动 r 和 l。在这个阶段,玩家的偏好(或效用)并不重要,因为我们只关心描述玩家的信息。
![a diagram of 6 circles in an array two
图 8
实线代表安的信息分割,虚线代表鲍勃的信息分割。我们进一步假设存在一个共同的先验概率 p0,其中分配给每个状态的概率写在状态右边。让 E={w2,w5,w6}为一个事件。然后,我们有
B121(E)={w∣p0(E∣Π1(w))=p0(E∩Π1(w))p0(Π1(w))=12}={w1,w2,w3}:“安在给定她的信息单元 Π1(w1)的情况下,分配概率 1/2 给事件 E。
B2(E)=B12(E)={w2,w5,w3,w6}。特别地,注意在 w6 处,代理人相信(概率为 1)E 为真,但不知道 E 为真,因为 Π2(w6)⊈E。因此,代理人认为可能的状态(考虑到他们的“硬信息”)和玩家分配非零概率的状态之间存在区别。
让 U={w1,w2,w3} 表示安玩 u 的事件,而 L={w1,w4} 表示鲍勃玩 l 的事件。然后,我们有
K1(U)=U 和 K2(L)=L:安和鲍勃都知道他们选择了什么策略;
B121(L)=U:在安玩 u 的所有状态下,安相信鲍勃以 1/2 的概率玩 L;
B1(B122(U))={w1,w2,w3}=U: 在 Ann 打出 u 的所有状态下,她相信 Bob 以 1/2 的概率相信她正在打出 u。
2.3 Harsanyi Type Spaces
一种替代建模信念的方法是由 Harsanyi 在他的开创性论文中提出的(Harsanyi 1967–68)。与“可能世界”不同,Harsanyi 将玩家的类型概念作为原始概念。形式上,玩家被分配一个非空类型集合。通常情况下,玩家被假定知道自己的类型,但不知道其他玩家的类型。正如我们将看到的,每种类型都可以与特定的信念层次相关联。
Definition 2.7 (Qualitative Type Space) A Qualitative type space for a (nonempty) set of states of nature S and agents N is a tuple ⟨{Ti}i∈N,{λi}i∈N,S⟩ where for each i∈N, Ti is a nonempty set and
λi:Ti→℘(Xj≠iTj×S).
So, each type t∈Ti is associated with a set of tuples consisting of types of the other players and a state of nature. For simplicity, suppose there are only two players, Ann and Bob. Intuitively, (t′,o′)∈λAnn(t) means that Ann’s type t considers it possible that the outcome is o′ and Bob is of type t′. Since the players’ uncertainty is directed at the choices and types of the other players, the informational attitude captured by these models will certainly not satisfy the Truth axiom. In fact, qualitative type spaces can be viewed as simply a “re-packaging” of the relational models discussed above (cf. Zvesper 2010 for a discussion).
重新考虑安和鲍勃之间的协调博弈的运行示例(见图 1)。在这种情况下,自然地修改类型函数 λi 的定义,以考虑玩家只对其他玩家的选择感到不确定:让 SA={u,d}和 SB={l,r},假设 TA 和 TB 是非空类型集。定义 λA 和 λB 如下:
λA:TA→℘(TB×SB)λB:TB→℘(TA×SA)
假设每个玩家有两种类型:TA={tA1,tA2}和 TB={tB1,tB2}。描述映射 λA 和 λB 的一种方便的方法是:
λA(TA1)
λA(TA2)
λB(TB1)
λB(TB2)
图 9
在上述矩阵的(t′,s)位置上的 1 对应于假设(t′,s)∈λi(t) (i=A,B)。Ann(Bob)相信一个事件 E 在一个类型结构中意味着什么?我们从对上述类型结构的一些直观观察开始:
无论我们给 Ann 分配什么类型,她都相信 Bob 会选择 l,因为在两个矩阵 λA(tA1)和 λA(tA2)中,1 出现的唯一位置都在 l 列下。因此,固定一个类型给 Ann,在 Ann 认为可能的所有情况下,Bob 选择 l 是正确的。
如果给 Ann 分配类型 tA1,那么她认为 Bob 相信她会选择 u 是可能的。注意,类型 tA1 在标记为 tB1 的行上有一个 1,所以她认为 Bob 可能是类型 tB1,并且类型 tB1 相信 Ann 选择 u(1 出现的唯一位置是在 u 列下)。
如果安被分配为类型 tA2,则安相信鲍勃相信安相信鲍勃会选择 l。注意类型 tA2“相信”鲍勃会选择 l,而且 tA2 相信鲍勃是类型 tB2,后者又相信安是类型 tA2。
我们可以使用以下概念来形式化上述非正式观察:为代理人 N 和自然状态集合 S(非空)固定一个定性类型空间 ⟨{Ti}i∈N,{λi}i∈N,S⟩。
一个(全局)状态或可能世界是一个元组(t1,t2,…,tn,s),其中对于每个 i=1,…,n,ti∈Ti,s∈S。如果 S=XSi 是某个博弈的策略配置集合,则我们将可能世界写为:(t1,s1,t2,s2,…,tn,sn),其中对于每个 i=1,…,n,si∈Si。
类型空间描述了玩家对其他玩家选择的信念,因此事件的概念需要相对于一个代理进行相对化。对于代理 i 来说,一个事件是 Xj≠iTj×S 的子集。同样,如果 S 是一个策略配置的集合(所以 S=XSi),那么对于代理 i 来说,一个事件是 Xj≠i(Tj×Sj)的子集。
假设 E 是代理 i 的一个事件,那么我们说在(t1,t2,…,tn,s)时刻,代理 i 相信 E,如果 λ(t1,s)⊆E。
在上述具体例子中,Ann 的一个事件是一个集合 E⊆TB×SB,我们可以定义相信这个事件的一对(tA,sA)的集合:
BA(E)={(tA,sA)∣λA(tA,sA)⊆E}
同样对于 Bob。注意,事件 BA(E)是 Bob 的事件,反之亦然。对类型空间的上述定义(定义 2.7)进行微小修改,使我们能够表示概率信念(我们在此给出完整定义以供将来参考):
定义 2.8(类型空间)对于自然状态的(非空)集合 S 和代理人 N,类型空间是一个元组 ⟨{Ti}i∈N,{λi}i∈N,S⟩,其中对于每个 i∈N,Ti 是一个非空集合,
λi:Ti→Δ(Xj≠iTj×S).
其中 Δ(Xj≠iTj×S) 是 Xj≠iTj×S 上的概率测度集合。
类型及其在 λi 下的关联图像编码了玩家对其他玩家信息的(概率)信息。事实上,每种类型都与一种信念层次相关联。更正式地说,回想一下,对于类型 ti 的事件 E 是一组对偶 (σ−j,t−j),即所有其他玩家的策略选择和类型的集合。对于玩家 i 的事件 E,让 λi(ti)(E) 表示 λi(ti) 分配给 E 中元素的概率之和。玩家 i 的类型 ti 被称为(全面)相信事件 E,每当 λi(ti)(E)=1 时。条件信念是按标准方式计算的:类型 ti 相信给定 F 时的事件 E。
λi(ti)(E∩F)λi(ti)(F)=1
一个类型结构中的状态是一个元组(σ,t),其中 σ 是一个策略配置,t 是“类型配置”,即每个玩家的类型的元组。对于每个玩家 j,令 Bi(E)={(σ−j,t−j):ti 相信 E}表示事件 i 相信 E(对于 j)。那么当 λj(tj)(Bi(E))=1 时,代理 j 相信 i 相信 E。我们可以继续以这种方式计算任何(有限)层次的高阶信息。
例子
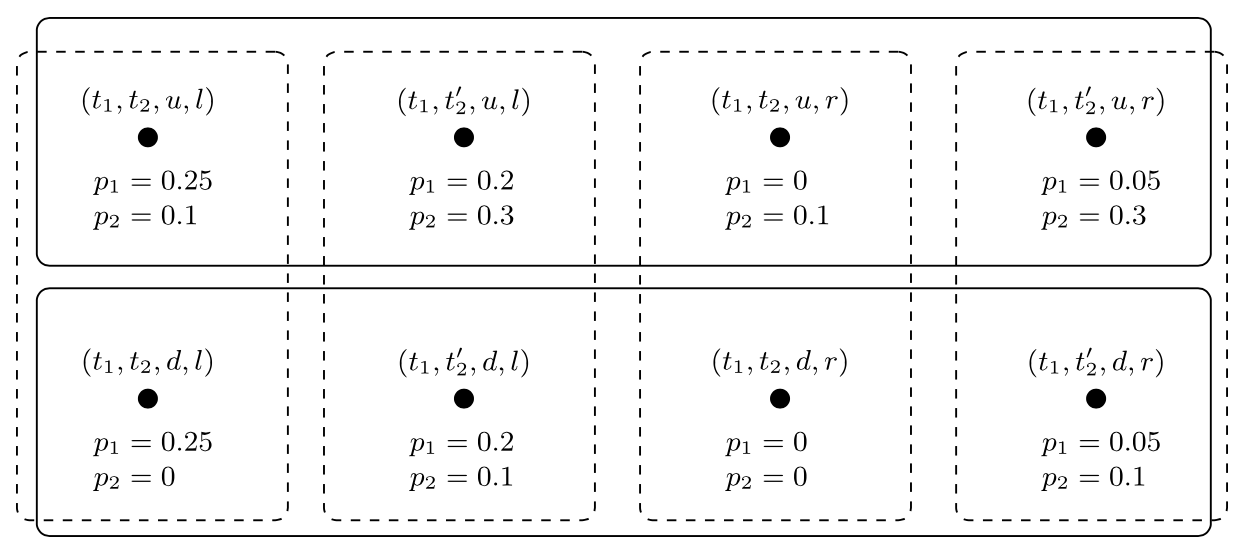
再次回到我们的运行示例游戏,其中玩家 1(Ann)有两个可用动作{u,d},玩家 2(Bob)有两个可用动作{l,r}。以下类型空间描述了玩家的信息:Ann 有一个类型(t1),Bob 有两个类型(t2,t′2),对应的概率测度如下:
λ1(t1)
图 10:安对鲍勃的信念
λ2(t2)
λ2(t′2)
Figure 11: Bob's belief about Ann
在这个例子中,由于安只有一种类型,鲍勃的两种类型都 确定 安的信念。如果鲍勃是类型 t2,那么他确信安选择 u,而如果他是类型 t′2,他认为安选择 u 的可能性为 75%。安将鲍勃的类型赋予相等的概率(0.5),因此她认为鲍勃确定她选择 u 和鲍勃认为她选择 u 的可能性为 75% 是同样可能的。上述类型空间是对玩家信息态度的非常简洁的描述。一个认知-概率模型可以描述相同的情况(这里 pi 对于 i=1,2 是玩家 i 的先验概率):
![a diagram of 8 dots in an array two high
Figure 12
一些简单(但有启发性!)的计算可以使我们相信这两个模型代表了同样的情况。更有趣的问题是这些概率模型如何与定义 2.4 中的认识-信念模型相关。在这里,情况更加复杂。一方面,概率模型具有比认识-信念模型中讨论的“全面”信念概念更加精细的分级信念概念。另一方面,在认识-信念模型中,对于所有事件都定义了条件信念。在上述模型中,它们仅对被分配非零概率的事件进行定义。换句话说,认识-概率模型不描述玩家在得知某些“令人惊讶”的事情(即,当前被分配概率为零的事情)后可能相信什么。
文献中讨论了一些扩展基本概率论的方法,以解决这个问题。我们在这里不详细介绍这些方法(Halpern(2010)中可以找到一个很好的总结和详细比较),而是概述主要思想。第一种方法是使用所谓的波普函数,它将条件概率测度作为原始概念。也就是说,对于每个非空事件 E,存在一个概率测度 pE(⋅),满足通常的科尔莫哥洛夫公理(相对于 E,例如 pE(E)=1)。第二种方法是为每个代理分配一个有限序列的概率测度(p1,p2,…,pn),称为词典概率系统。其思想是在给定 F 的条件下,首先找到第一个不将 F 分配为零的概率测度,并使用该测度对 F 进行条件化。粗略地说,可以将词典概率系统中的每个概率测度视为对应于一个可能性排序的级别。我们将在第 5.2 节中回顾这些概念。
2.4 共同知识
在一个博弈模型中,状态不仅代表玩家对对手会做什么的信念,还代表他们对对手思考的高阶信念。这意味着在特定信息背景下被认定为“理性”的结果将在一定程度上取决于这些高阶信念。博弈论家和逻辑学家已经广泛讨论了关于群体知识和信念的不同概念,比如共同知识和信念。在本节中,我们简要回顾了共同知识的标准定义。有关更多信息和相关文献的指引,请参阅 Vanderschraaf & Sillari (2009)和 Fagin et al. (1995: ch. 6)。
考虑这样的陈述:“I 组中的每个人都知道 E”。这在形式上定义如下:
KI(E) := ⋂i∈IKi(E)
其中 I 是任意非空的玩家集合。如果 E 对于组 I 是共同知识,那么不仅组中的每个人都知道 E 是真的,而且这个事实对于组中的所有成员来说都是完全透明的。我们首先通过归纳定义 KnI(E) 来定义每个 n≥0:
K0I(E)=E,对于 n≥1,KnI(E)=KI(Kn−1I(E)
然后,根据奥曼(1976)的定义,E 的共同知识被定义为以下无限连词:
CI(E)=⋂n≥0KnI(E)
解包定义,我们有
CI(E)=E∩KIϕ(E)∩KI(KI(E))∩KI(KI(KI(E)))∩⋯
上述定义共同知识的方法可以被视为定义共同(稳健/强)信念的配方(只需用适当的信念算子替换知识算子 Ki)。有关共同信念逻辑的更多信息,请参阅 Bonanno(1996)和 Lismont&Mongin(1994, 2003)。尽管我们在本条目中没有讨论它,但 Monderer&Samet(1989)引入了共同信念的概率变体。
3. 选择规则,或最佳选择
决策理论中存在许多哲学问题,但这不是我们关心的问题。有关主要哲学问题的讨论,请参阅 Joyce 2004 及其引用。本节提供了足够的决策理论背景,以理解本条目其余部分中呈现的认识论博弈论的关键结果。
决策规则或选择规则确定在给定情境中,每个个体玩家将会或应该做出什么选择,考虑到她的偏好和信息。在认识论博弈论文献中,最常用的选择规则是:(严格)优势、期望效用最大化和可接受性(也称为弱优势)。可以使用替代的选择规则进行认识论博弈分析,例如,最小最大遗憾(Halpern & Pass 2011)。在本条目中,我们只关注最常见的选择规则。
决策理论家区分不确定性下的选择和风险下的选择。在后一种情况下,决策者对世界可能状态有概率信息。在前一种情况下,没有这样的信息。关于这两种情况下的决策制定有大量文献(参见 Peterson 2009,讨论和指向相关文献)。在认识论博弈论的设置中,一个“理性选择”的适当概念取决于用于描述博弈信息背景的博弈模型的类型。因此,一般来说,“理性”应该被理解为遵循给定的选择规则。一般的方法是从定义一个非理性选择开始(例如,在某人的信念下是严格被优势支配的选择),然后将理性定义为不是非理性。一些作者最近研究了解除这个简化假设的后果(参见 Cubitt & Sugden (2011)和 Pacuit & Roy (2011)中的三分法分类概念),但这超出了本条目的范围。
最后,当理性的基本概念超越期望效用最大化时,一些作者将“最优”一词保留用于限定满足后者要求但不一定满足完全理性要求的决策。有关此更多信息,请参见第 5.2 节的备注。
3.1 Maximization of Expected Utility
期望效用最大化是决策理论中最著名的选择规则。考虑到一个 agent 的偏好(以效用函数表示)和信念(以主观概率度量表示),一个行动或选项的期望效用是该行动的结果的效用的加权和,权重是它们发生的概率(根据 agent 的信念)。建议选择最大化这个加权平均值的行动。这个想法是贯穿于实践理性的_贝叶斯_观点的,可以直接在类型空间中定义。我们首先定义游戏中一个玩家的期望效用。
Expected utility
Suppose that G=⟨N,{Si,ui}i∈N⟩ is a strategic game. A conjecture for player i is a probability on the set S−i of strategy profiles of i’s opponents. That is, a conjecture for player i is an element of Δ(S−i), the set of probability measures over S−i. The expected utility of si∈Si with respect to a conjecture p∈Δ(S−i) is defined as follows:
EU(si,p) := ∑s−i∈S−ip(s−i)u(si,s−i)
A strategy si∈Si maximizes expected utility for player i with respect to p∈Δ(S−i) provided for all s′i∈Si, EU(si,p)≥EU(s′i,p). In such a case, we also say si is a best response to p in game G.
We now can define an event in a type space or epistemic-probability model where all players “choose rationally”, in the sense that their choices maximize expected utility with respect to their beliefs.
Expected utility in type spaces
Let G=⟨N,{Si,ui}i∈N⟩ be a strategic game and T=⟨{Ti}i∈N,{λi}i∈N,S⟩ a type space for G. Recall that each ti is associated with a probability measure λ(ti)∈Δ(S−i×T−i). Then, for each ti∈Ti, we can define a probability measure pti∈Δ(S−i) as follows:
pti(s−i)=∑t−i∈T−iλi(ti)(s−i,t−i)
状态集合(策略概要和类型概要的对)中,玩家 i 选择理性的地方被定义为:
Rati := {(si,ti)∣si is a best response to pti}
所有玩家都是理性的事件
Rat={(s,t)∣ for all i,(si,ti)∈Rati}.
注意这里的类型与玩家不同,它们最大化预期效用。这是因为在类型结构中,信念与类型相关联(见上文第 2.3 节)。熟悉决策理论的读者会意识到,这只是预期效用最大化的标准概念,其中每个玩家的不确定性空间,即其行动后果所依赖的可能“世界状态”,是其他玩家的类型和策略选择的可能组合。
为了说明上述定义,考虑图 4 中的游戏和图 11 中的类型空间。以下计算表明(u,t1)∈Rat1 (u 是玩家 1 的最佳响应,考虑到她由 t1 定义的信念):
EU(u,pt1)=pt1(l)u1(u,l)+pt1(r)u1(u,r)=[λ1(t1)(l,t2)+λ1(t1)(l,t′2)]⋅u1(u,l)+[λ1(t1)(r,t2)+λ1(t1)(r,t′2)]⋅u1(u,r)=(0.5+0.4)⋅3+(0+0.1)⋅0=2.7
EU(d,pt1)=pt1(l)u1(d,l)+pt1(r)u1(d,r)=[λ1(t1)(l,t2)+λ1(t1)(l,t′2)]⋅u1(d,l)+[λ1(t1)(r,t2)+λ1(t1)(r,t′2)]⋅u1(d,r)=(0.5+0.4)⋅0+(0+0.1)⋅1=0.1
一项类似的计算表明(l,t2)∈Rat2。
期望效用在认识-概率模型中
在认识-概率模型中,理性事件的定义类似。为了完整起见,我们给出正式的细节。假设
G=⟨N,{Si,ui}i∈N⟩
是一个战略博弈
M=⟨W,{∼i}i∈N,{pi}i∈N,σ⟩
是一种认识论概率模型,其中每个 pi 都是关于 W 的先验概率测度。每个状态 w∈W,让
Es−i={w∈W∣(σ(w))−i=s−i}。
然后,对于每个状态 w∈W,我们定义一个测度 pw∈Δ(S−i) 如下:
pw(s−i)=p(Es−i∣Πi(w))
如上所述,
Rati:={w∣σi(w) is a best response to pw}
和
Rat:=⋂i∈NRati.
3.2 支配推理
当一个游戏模型没有描述玩家的概率信念时,我们处于不确定性选择的情况。在这种情况下,对“理性选择”的标准概念是基于优势推理(Finetti 1974)。优势的两个标准概念是:
定义 3.1(严格优势)假设 G=⟨N,{Si,ui}i∈N⟩ 是一个战略游戏,X⊆S−i。让 mi,m′i∈Δ(Si)是玩家 i 的两个混合策略。如果对于所有的 s−i∈X,Ui(mi,s−i)>Ui(m′i,s−i),则策略 mi 在 X 的情况下严格优于 m′i。
for all s−i∈X,Ui(mi,s−i)>Ui(m′i,s−i).
我们说 mi 在严格支配下,只要存在某个 m′i∈Δ(Si),它严格支配 mi。
如果 mi∈Δ(Si)在无论其他玩家如何行动时都比 m′i∈Δ(Si)更好(即给予玩家 i 更高的回报),则 mi 严格支配 m′i。还有一个较弱的概念:
定义 3.2(弱支配)假设 G=⟨N,{Si,ui}i∈N⟩ 是一个战略博弈,X⊆S−i。让 mi,m′i∈Δ(Si)是玩家 i 的两个混合策略。如果 mi 相对于 X 在弱意义上支配 m′i,则 mi 弱支配 m′i。
对于所有 s−i∈X,Ui(mi,s−i)≥Ui(m′i,s−i)
and
存在一些 s−i∈X,使得 Ui(mi,s−i)>Ui(m′i,s−i)
我们说 mi 是弱支配的,只要存在某个 m′i∈Δ(Si),它弱支配 mi。
因此,一个混合策略 mi 弱支配另一个策略 m′i,只要无论其他玩家做什么,mi 至少和 m′i 一样好,并且至少存在一种情况下,mi 比 m′i 严格更好。
在我们使用这些选择规则之前,我们需要解决关于这些定义的两个可能令人困惑的问题。
严格支配和弱支配的定义是以混合策略的形式给出的,即使我们假设玩家只选择纯策略。也就是说,我们不考虑玩家明确进行随机选择的情况。特别地,要记住,只有纯策略与博弈模型中的状态相关联。然而,以混合策略的形式定义严格/弱支配是重要的,因为有些游戏中,一个纯策略严格(弱)被混合策略支配,但不被其他任何纯策略支配。
即使考虑玩家的纯策略被混合策略严格/弱支配的情况是重要的,我们也不会将上述定义扩展到对对手策略的概率上。也就是说,我们不会用以下定义替换上述定义
mi 相对于 X⊆Δ(S−i) 是严格 p-支配 m′i,只要对于所有 q∈X, Ui(mi,q)>Ui(m′i,q)。
这是因为两个定义是等价的。显然,p-严格支配意味着严格支配。为了看到逆否命题,假设对于 X⊆S−i,m′i 被 mi 支配。我们证明对于所有 q∈Δ(X),Ui(mi,q)>Ui(m′i,q)(因此 m′i 在 X 方面是 p-严格被 mi 支配的)。假设 q∈Δ(X)。那么,
Ui(mi,q)=∑s−i∈S−iq(s−i)Ui(mi,s−i)>∑s−i∈S−iq(s−i)Ui(m′i,s−i)=Ui(m′i,q)。
上述定义中的参数 X 旨在表示玩家 i 认为是“活可能性”的策略配置集。认知(-可能性)模型中的每个状态都与这样一个策略配置集相关联。在游戏模型中的可能世界 w 中,让 S−i(w)表示玩家 i“认为”可能的状态集。精确的定义取决于游戏模型的类型:
认知模型假设
G=⟨N,{Si,ui}i∈N⟩
是一个战略博弈,
M=⟨W,{Πi}i∈N,σ⟩
是 G 的认识模型。对于每个玩家 i 和 w∈W,定义集合 S−i(w)如下:
S−i(w)={σ−i(v)∣v∈Πi(w)}
认知-合理性模型假设
G=⟨N,{Si,ui}i∈N⟩
是一个战略博弈,
M=⟨W,{∼i}i∈N,{⪯i}i∈N,σ⟩
是 G 的认识-可能性模型。对于每个玩家 i 和 w∈W,定义集合 S−i(w)如下:
S−i(w)={σ−i(v)∣v∈Min⪯i([w]i)}
In either case, we say that a choice at state w is sd-rational for player i at state w provided it is not strictly dominated with respect to S−i(w). The event in which i chooses rationality is then defined as
Ratsdi := {w∣σi(w) is not strictly dominated with respect to S−i(w)}.
In addition, we have Ratsd := ⋂i∈NRatsdi. Similarly, we can define the set of states in which player i is playing a strategy that is not weakly dominated, denoted Ratwdi and Ratwd using weak dominance.
自己行动的认知,作为临时情况的特征,在上述定义中起着重要作用。它强调,每当 w′∈Πi(w)时,σi(w′)=σi(w)。这意味着玩家 i 的理性是根据她当前选择的结果来评估的,而这个结果是根据其他玩家行动的不同组合而定的。
一个重要的特例是当玩家们认为所有对手的策略都是可能的。很明显,一个理性的玩家永远不会选择一个在 S−i 方面严格被支配的策略。也就是说,如果 si 在 S−i 方面严格被支配,那么在任何信息背景下,玩家 i 选择 si 都是不理性的。这可以通过以下著名引理更加精确地描述。
引理 3.1 假设 G=⟨N,{Si,ui}i∈N⟩ 是一个战略博弈。对于 X⊆S−i,如果策略 si∈Si 在 X⊆S−i 方面严格被支配(可能是由混合策略),当且仅当不存在概率测度 p∈Δ(X)使得 si 对于 p 是最佳响应。
这个引理的证明在补充部分的第 1 节中给出。
一般的结论是,在给定状态下,没有一种被支配的策略能够最大化预期效用;反之,如果存在一种策略在特定情境下不是最佳的,那么它就不是严格被支配的。
关于弱支配也存在类似的事实,尽管情况更加微妙。关键观察是,有一种对于某些类型的概率测度的最佳反应的弱支配的表征。概率测度 p∈Δ(X)被称为在 X 上具有全支持(with respect to X),如果 p 对 X 的每个元素分配了正概率(形式上,supp(p)={x∈X∣p(x)>0}=X)。设 Δ>0(X)为 X 上具有全支持的概率测度的集合。对于 S−i 上的全支持概率,这意味着玩家 i 不完全排除(即,她对任何对手的策略配置分配了零概率)任何策略配置。下面的引理 3.1 的类比也是众所周知的:
引理 3.2 假设 G=⟨N,{Si,ui}i∈N⟩ 是一个战略博弈。对于 X⊆S−i,如果策略 si∈Si 在全支持概率测度 p∈Δ>0(X)下是最佳响应,则 si 是弱支配的(可能是由混合策略)。
这个引理的证明更加复杂。参见 Bernheim (1984: 附录 A)。为了使策略 si 不被严格支配,只要 si 对于某种信念是最佳响应,无论那种信念是什么,都足够了。可接受性需要更多:策略必须对一个不明确排除任何对手选择的信念是最佳响应。比较这两个引理,我们可以看到严格支配蕴含弱支配,但反之则不一定成立。一个策略可能对任何全支持概率测度都不是最佳响应,但对于某些特定的信念却是最佳响应,这些信念赋予某种状态的概率为一,使得玩家对于其当前行动的结果和可能的不可接受的结果之间持中立态度。
弱支配和严格支配之间还有另一个关键的区别。从严格支配的定义中立即得到以下观察:
观察 3.3 如果 si 在 X 方面严格被支配,并且 X′⊆X,则 si 在 X′方面严格被支配。
如果一种策略在严格意义上被支配,那么当玩家获得更多关于对手可能行动的信息时,它仍然如此。因此,如果在游戏 G 中,策略 si 在整个对手策略集 S−i 方面严格被支配,那么在 G 的任何认知(-可能性)模型中,si 都不会被视为理性(根据上述定义)。也就是说,没有信念可以使玩家 i 认为 si 是理性的。相同的观察结果不适用于弱支配。弱支配的定义中的存在部分意味着观察 3.3 的类比不适用于弱支配:如果 si 在 X 方面被弱支配,那么 si 在某些 X′⊆X 方面不一定被弱支配。
4. 基础
对博弈论的认识论方法侧重于特定信息背景下个体决策者的选择,根据决策理论的选择规则进行评估。这是一种自下而上的方法,与古典的自上而下方法相对。该范式的早期研究包括 Bernheim(1984)和 Pearce(1984)关于合理性的概念,以及 Aumann(1987)从玩家“贝叶斯理性”最小假设推导出相关均衡的推导。
认识论博弈论中的一个重要研究方向是在什么认识论条件下玩家会遵循特定解概念的建议?提供这样的条件被称为解概念的认识论表征。
在本节中,我们提出了两个基本的认识论表征结果。第一个是对严格被支配策略的迭代消除(以下简称 ISDS)的表征,第二个是对反向归纳的表征。这些认识论表征结果在历史上具有重要意义。它们标志着认识论博弈论的开端,也是概念上的重要。后续章节的发展建立在本节提出的思想基础上。
4.1 严格支配策略的迭代消除
知识论博弈论的核心结果是“理性和对理性的共同信念意味着严格支配策略的迭代消除”。这一结果已经在 Vanderschraaf & Sillari (2009)中进行了讨论。因此,我们将重点放在其对博弈论知识基础的重要性上,而不是专注于形式细节。一个重要的信息是,该结果突显了高阶信息的重要性。
4.1.1 结果
严格支配策略的迭代淘汰(ISDS)是一个解决概念,其运行如下。首先,从原始游戏中移除对于玩家 i 来说是严格被对手策略支配的任何策略(关于所有对手的策略概况)。在移除原始游戏中的严格被支配策略之后,观察所得到的子游戏,移除在那里变得严格被支配的策略,并重复这个过程,直到淘汰不再移除任何策略。在这个过程中幸存下来的概况被称为迭代非支配的。
例如,考虑以下战略游戏:
BobAnn
图 13
请注意,对于{t,m,b},r 对于玩家 2 是严格被支配的。一旦 r 从游戏中移除,我们有 b 对于玩家 1 在{l,c}方面是严格被支配的。因此,{(t,l),(t,c),(m,l),(m,c)}被迭代地去支配。也就是说,迭代地移除严格被支配的策略会生成以下游戏序列:
↣
↣
图 14
对于任意大的(有限)战略博弈,如果所有玩家都是理性的,并且存在一个共同的信念,即所有玩家都是理性的,那么他们将选择一种迭代非支配策略。该结果归功于 Bernheim(1984)和 Pearce(1984)。参见 Spohn(1982)的早期版本,以及 Brandenburger&Dekel(1987)与相关均衡的关系。
在陈述正式结果之前,我们用一个例子来说明结果。我们首先描述上述游戏的“信息背景”。为此,定义一个类型空间 T=⟨{T1,T2},{λ1,λ2},S⟩,其中 S 是上述游戏中的策略配置,对于玩家 1 有两种类型(T1={t1,t2}),对于玩家 2 有三种类型(T2={s1,s2,s3})。类型函数 λi 定义如下:
λ1(t1)
λ1(t2)
λ2(s1)
λ2(s2)
λ2(s3)
图 15
然后我们考虑(s,t)对,其中 s∈Si,t∈Ti,并确定所有合理对(即 s 是对 λi(t)的最佳响应,有关讨论请参见前一节):
Rat1={(t,t1),(m,t1),(b,t2)}
Rat2={(l,s1),(c,s1),(l,s2),(c,s2),(l,s3)}
下一步是确定相信其他玩家是理性的类型。在这种情况下,信念意味着概率 1。对于类型 t1,我们有 λ1(t1)(Rat2)=1; 然而,
λ1(t2)(s2,r)=0.5>0,
但 (r,s2)∉Rat2,所以 t2 并不相信玩家 2 是理性的。这可以转化为一个迭代过程,如下所示:设 R1i=Rati。我们首先需要一些符号表示。假设对于每个 i, Rni 已经被定义。那么,定义 Rn−i 如下:
Rn−i={(s,t)∣s∈S−i, t∈T−j,且对于每个 j≠i, (sj,tj)∈Rnj}。
对于每个 n>1,按如下归纳定义 Rni。
Rn+1i={(s,t)∣(s,t)∈Rni and λi(t) assigns probability 1 to Rn−i}
因此,我们有 R21={(t,t1),(m,t1)}。请注意,s2 对 (m,t2) 这一对分配了非零概率,而这对不在 R11 中,因此 s2 不认为 1 是理性的。因此,我们有 R22={(l,s1),(c,s1),(l,s3)}。继续这个过程,我们有 R21=R31。然而,s3 对 (b,t2) 这一对分配了非零概率,而这对不在 R21 中,因此 R32={(l,s1),(c,s1)}。将所有内容放在一起,我们有
⋂n≥1Rn1 × ⋂n≥1Rn2={(t,t1),(m,t1)}×{(l,s1),(c,s1)}。
因此,所有在迭代地删除严格被支配策略({(t,l),(m,l),(t,c),(m,c)})后幸存下来的配置都与玩家理性且共同相信自己是理性的状态一致。
注意,上述过程不一定会生成所有在迭代地删除严格被支配策略后幸存下来的策略。例如,考虑一个类型空间,玩家 1 的单一类型分配概率 1 给玩家 2 的单一类型和 l,玩家 2 的单一类型分配概率 1 给玩家 1 的单一类型和 u。那么,在这个模型中,(u,l)是唯一的策略配置,显然满足理性和共同相信的理性。然而,对于任何类型空间,如果一个策略配置与理性和共同相信的理性一致,那么它必须是在迭代地删除严格被支配策略后幸存下来的策略集合中的策略。
定理 4.1 假设 G 是一个战略博弈,T 是 G 的任意类型空间。如果(s,t)是 T 中的一个状态,其中所有玩家都是理性的,并且存在共同相信的理性,即对于每个 i,
(si,ti)∈⋂n≥1Rni
—then s is a strategy profile that survives iteratively removal of strictly dominated strategies.
这一结果建立了 ISDS 的充分条件。它还有一个逆向的方向:对于任何能够经受住严格支配策略迭代淘汰的策略配置,存在一个模型,在这个模型中,所有的玩家都是理性的,并且这是共知的。换句话说,我们总是可以将能够经受住迭代淘汰程序的策略配置的选择视为理性共知的结果。当然,这种逆向的形式并不特别有趣,因为我们总是可以定义一个类型空间,在这个空间中,所有的玩家都对给定的策略配置分配概率 1(并且每个人都按照他们所需的策略行动)。更有趣的是,问题是整个能够经受住严格支配策略迭代淘汰的策略配置集是否与理性和对理性的共同信念一致。这是 Brandenburger & Dekel(1987)的以下定理所涵盖的(参见 Tan & Werlang 1988)。
定理 4.2 对于任何游戏 G,存在一个类型结构,其中与理性和对理性的共同信念一致的策略剖面是在严格支配策略迭代移除后幸存的策略集。
参见 Friedenberg & Keisler (2010) 关于上述结果的最强版本。使用不同的游戏模型(例如认知模型、认知-可能性模型等)已经证明了上述结果的类比。例如,参见 Apt & Zvesper (2010) 使用 Kripke 模型证明相应定理的证明。
4.1.2 哲学问题
许多作者已经指出了前一节结果中普遍信念假设的强度(参见,例如,Gintis 2009;Bruin 2010)。这要求玩家不仅相信其他人不选择非理性策略,而且相信每个人都相信没有人选择非理性策略,每个人都相信每个人都相信每个人都相信没有人选择非理性策略,依此类推。然而,需要指出的是,这种无限性特性仅仅是为了确保结果适用于_任意_有限的游戏。对于特定的游戏和其模型,“每个人都相信”的有限迭代就足以确保一个可以经受迭代淘汰过程的游戏进行。
对于普遍信念假设无限性的批评,一个可能的回应是将结果视为对一个_基准_案例的分析,而不是对真正的游戏情境的描述或对理性玩家_应该_做什么的规定(Aumann 2010)。事实上,理性的普遍知识/信念长期以来一直被用作解释经典博弈理论分析所基础的理想化的非正式解释(Myerson 1991)。上述结果表明,一旦形式化,这种假设确实导致了一个经典的解决方案概念,尽管有趣的是,并非像早期的博弈理论文献中经常不正式地声称的那样,是著名的纳什均衡。关于纳什均衡的认识论条件,请参见 第 5.1 节。
从前一节结果中可以得出的主要信息是:在博弈中进行战略推理涉及更高阶的信息。这意味着,特别地,
“贝叶斯理性”单独来看——即期望效用最大化——并不能足以确保在一般情况下玩出迭代不被支配的策略剖面。
一般来说,一阶理性的信念也不够。究竟需要多少级别的信念才能保证在游戏情况下发挥“理性”仍然是一个争论的焦点(Kets 2014;Colman 2003;de Weerd, Verbrugge, & Verheij 2013;Rubinstein 1989)。我们还需要解决两个进一步的问题。
首先,代理人如何达成普遍相信理性的情境?上述结果并未回答这个问题。这是动态认知逻辑最近研究的课题(van Benthem 2003)。在这一文献中,通过反复和公开“宣布”他们不是非理性的方式,回答了这个问题,这样代理人可以消除关于彼此理性的所有高阶不确定性,从而确保没有策略被玩出,而这些策略无法经受迭代淘汰过程的检验。换句话说,理性的公开宣布的迭代使玩家的期望收敛到足以发挥迭代非被支配策略的充分认知条件。有关这种动态观点对解决方案认知特征化的更多信息,请参见 van Benthem (2003);Pacuit & Roy (2011);van Benthem & Gheerbrant (2010);以及 van Benthem, Pacuit, & Roy (2011)。
其次,当参与者超过两名时,上述结果仅在参与者相信其对手的选择是相关的情况下成立(Bradenburger & Dekel 1987; Brandenburger & Friedenberg 2008)。Brandenburger & Friedenberg (2008)提供的以下例子阐明了这一点。考虑以下三人博弈,Ann 的策略为 SA={u,d},Bob 的策略为 SB={l,r},Charles 的策略为 SC={x,y,z},他们对每种结果的偏好分别列于相应的单元格中:
x_ y _z
图 16
请注意,对于查尔斯来说,y 并非严格被支配。很容易找到一个概率测度 p∈Δ(SA×SB),使得 y 是对 p 的最佳响应。假设 p(u,l)=p(d,r)=12。那么,EU(x,p)=EU(z,p)=1.5,而 EU(y,p)=2。然而,并不存在概率测度 p∈Δ(SA×SB),使得 y 是对 p 的最佳响应,且 p(u,l)=p(u)⋅p(l)(即查尔斯认为安和鲍勃的选择是独立的)。为了看到这一点,假设 a 是分配给 u 的概率,b 是分配给 l 的概率。那么,我们有:
y 的预期效用是 2ab+2(1−a)(1−b);
x 的预期效用是 3ab+3a(1−b)=3a(b+(1−b))=3a; and
z 的期望效用是 3(1−a)b+3(1−a)(1−b)=3(1−a)(b+(1−b))=3(1−a).
有三种情况:
假设 a=1−a(即 a=1/2)。然后,
2ab+2(1−a)(1−b)=2ab+2a(1−b)=2a(b+(1−b))=2a<3a。
因此,y 不是最佳反应。
假设 a>1−a。那么,
2ab+2(1−a)(1−b)<2ab+2a(1−b)=2a<3a。
因此,y 不是最佳反应。
假设 1−a>a。然后,
2ab+2(1−a)(1−b)<2(1−a)b+2(1−a)(1−b)=2(1−a)<3(1−a)。
因此,y 不是最佳反应。
在所有情况下,y 都不是最佳反应。
4.2 反向归纳
第二个基本结果分析了理性和理性的共同信念/知识在广泛博弈中(即树而不是矩阵)的后果。在这里,最著名的解决概念是所谓的子博弈完美均衡,也被称为完全信息博弈中的反向归纳。对这个解决概念的认识是以“实质理性”和所有玩家都是实质理性的共同信念为基础的(参见 Vanderschraaf&Sillari 2009:第 2.8 节)。我们在本节中强调的主要观点,现在在文献中被广泛认可,是:
信念修正政策在广泛博弈的认识分析中起着关键作用
这一点最为著名的例证是通过比较两个明显矛盾的结果,即在广泛博弈中假设理性和理性的普遍知识的后果。奥曼(1995)表明这一认识条件意味着玩家将根据反向归纳解来进行游戏,而斯坦纳克(1998)则认为这并非一定成立。这两个结果之间的关键差异在于它们对玩家在(假设性地)得知对手偏离反向归纳路径后的信念变化建模的方式。
4.2.1 广泛博弈:基本定义
广泛博弈明确了博弈情境中选择的顺序结构。在本节中,我们关注完全信息博弈,其中对于游戏中较早的选择没有不确定性。这些游戏由树状结构表示:
定义 4.3(完全信息广泛博弈)广泛博弈是一个元组 ⟨N,T,Act,τ,{ui}i∈N⟩,其中
N 是一组有限的玩家;
T 是描述游戏情况时间结构的树:形式上,T 由一组节点和一个直接后继关系 ↣ 组成。让 Z 表示终端节点的集合(即没有任何后继节点的节点),V 表示剩余节点(称为决策节点)。让 v0 表示初始节点(即树的根)。在决策节点 v∈V 处的边缘都标有来自行动集 Act 的动作。让 Act(v)表示在 v 处可用的动作集。让 ⇝ 表示 ↣ 的传递闭包。
τ 是一个将每个节点 v∈V 分配给一个玩家的转换函数(对于玩家 i∈N,让 Vi={v∈V∣τ(v)=i})。
ui:Z→R 是为玩家 i 分配实数到结果节点的效用函数。
策略是广泛博弈中的一个艺术术语。它表示对每一种可能性的计划,告诉一个代理人在她要玩的所有历史中该做什么,甚至包括那些被策略本身排除的情况。
定义 4.4(策略)对于玩家 i 的策略是一个函数 si:Vi→Act,其中对于所有 v∈Vi,si(v)∈Act(v)。策略配置,表示为 s,是 Πi∈NSi 的一个元素。给定一个策略配置 s,让 si 表示玩家 i 的 s 分量,s−i 表示除 i 之外所有玩家的 s 策略序列。
每个策略配置 s 都会在广泛博弈中生成一条路径,其中路径是按照广泛博弈中的节点之间的直接后继关系 ↣ 排序的节点的最大序列。我们说如果 v 是由策略配置 s 生成的路径上的节点,那么 v 就被 s 到达。假设 v 是广泛博弈中的任何节点。让 out(v,s)表示如果从节点 v 开始,所有玩家根据其在配置 s 中的相应策略移动,所达到的终端节点。给定玩家 i 的决策节点 v∈Vi,玩家 i 的策略 si 和一组 X⊆S−i 对手的策略配置,让 Outi(v,si,X)={out(v,(si,s−i))∣s−i∈X}。也就是说,Outi(v,si,X)是一组终端节点,如果从节点 v 开始,玩家 i 使用策略 si,i 的对手使用来自 X 的策略配置,可能到达的节点。
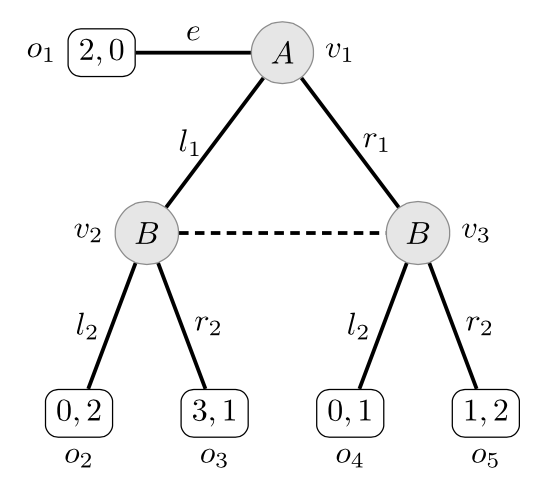
The following example of a perfect information extensive game will be used to illustrate these concepts. The game is an instance of the well-known centipede game, which has played an important role in the epistemic game theory literature on extensive games.
Figure 17: An extensive game
A 的决策节点为 VA={v1,v3},B 的决策节点为 VB={v2};结果节点为 O={o1,o2,o3,o4}。上述树中边的标签是每个玩家可用的行动。例如,Act(v1)={O1,I1}。A 有四种策略,B 有两种策略。为了简化表示,我们用每个决策节点上的选择序列来表示玩家的策略。例如,A 的策略 s1A 定义为 s1A(v1)=O1 和 s1A(v3)=O3,表示为序列 O1O3。因此,A 的策略有:s1A=O1O3,s2A=O1I3,s3A=I1O3 和 s4A=I1I3。请注意,A 的策略 s2A 指定了在 v3 处的移动,即使在 v1 处的早期移动 O1 意味着 A 将不会有机会在 v3 处移动。类似地,Bob 的策略将用 s1B=O2 和 s2B=I2 表示,给出 B 在他的决策节点上选择的行动。然后,例如,out(v2,(s2A,s2B))=o4。最后,如果 X={s1A,s4A},那么 OutB(v2,s2B,X)={o3,o4}。
4.2.2 反向归纳的认识特征
在广泛博弈中,有多种方式可以描述玩家的知识和信念。博弈模型根据所代表的认识态度(例如,知识和/或各种信念概念)以及在博弈过程中玩家修正其信念的方式而异。请参阅 Battigalli, Di Tillio, & Samet (2013); Baltag, Smets, & Zvesper (2009); 以及 Battigalli & Siniscalchi (2002),了解文献中不同类型模型的样本。
最简单的方法之一是使用第 2.2 节介绍的认识模型(参见 Aumann 1995; Halpern 2001b)。广泛博弈 G=⟨N,T,Act,τ,{ui}i∈N⟩ 的认识模型是一个元组 ⟨W,{Πi}i∈N,σ⟩,其中 W 是一个非空状态集合;对于每个 i∈N,Πi 是 W 上的一个划分;σ:W→Πi∈NSi 是一个将每个状态 w 映射到 G 的策略配置的函数。如果 σ(w)=s,则我们写 σi(w)表示 si,σ−i(w)表示 s−i。通常情况下,我们假设玩家知道自己的策略:对于所有 w∈W,如果 w′∈Πi(w),则 σi(w)=σi(w′)。
在决策节点上的策略的合理性取决于该策略在所有未来决策节点上规定的行动,以及玩家对其对手正在遵循的策略的了解。设 S−i(w)={σ−i(w′)∣w′∈Πi(w)}是玩家 i 的对手的策略配置集合,玩家 i 认为在状态 w 下可能存在的。然后,Outi(v,si,S−i(w))是玩家 i 认为在节点 v 开始,如果她遵循策略 si 可能发生的结果集合。
定义 4.5(决策节点上的合理性)对于状态 w 中的节点 v∈Vi,如果对于所有策略 si,si≠σi(w),存在一个 o′∈Outi(v,si,S−i(w))和一个 o∈Outi(v,σi(w),S−i(w)),使得 ui(o)≥ui(o′),则玩家 i 在节点 v 上是合理的。
因此,玩家 i 在状态 w 中的决策节点 v∈Vi 上是合理的,只要 i 不知道存在另一种能够给她更高回报的替代策略。
定义 4.6 (Substantive rationality) 玩家 i 在状态 w 下是实质上理性的,前提是对于所有决策节点 v∈Vi,i 在状态 w 下在 v 处是理性的。
我们可以用标准方式定义玩家 i 实质上理性的事件:Rati={w∣player i 在状态 w 下是实质上理性的};因此,所有玩家实质上理性的事件是 Rat=⋂i∈NRati。
在决策节点 v 处的理性概念是前瞻性的,因为它只考虑了游戏中从那一点开始可能出现的可能性。它不考虑导致 v 的先前动作,即选择已经或可能导致 v。我们将在下面的讨论中回到这一点。
这一重要结论是,仅由终端节点跟随的节点上的选择的理性与相关玩家的知识无关。如果一个节点 v 是预终端的,那么 v 的所有直接后继节点都是终端节点。在这样的节点上,玩家认为可能的策略并不重要:如果 v 是一个预终端节点,并且玩家 i 在 v 处行动,那么对于游戏的认知模型中的所有状态 w 和所有策略 si∈Si,Outi(v,si,S−i(w))={si(v)}。这意味着,例如,在图 17 的广泛博弈的认知模型中的任何状态 w,节点 v3 上理性的策略只能是那些规定 A 在节点 v3 选择 O3 的策略。因此,如果 w∈RatA,则 σA(w)(v3)=O3。无论 A 知道或者曾经知道 B 在游戏达到节点 v3 时会做什么,A 的唯一理性选择都是 O3。
对于预终端节点上玩家的理性信息对于在游戏中较早选择的玩家非常重要。回到图 17 的游戏,如果 B 知道 A 在游戏的认知模型中的状态 w 上是实质上理性的,那么 ΠB(w)⊆RatA。根据上述论点,这意味着如果 w′∈ΠB(w),那么 σA(w′)(v3)=O3。因此,对于游戏的认知模型中的任何状态 w,我们有
OutB(v2,I2,S−i(w))={o3};
当然,
OutB(v2,O2,S−i(w))={o2}.
但是,(O2) 是 B 在 v2 时在任何状态 w 下唯一理性的策略(这是因为 uB(o2)=2≥1=uB(o3))。这意味着如果 w∈RatB 并且 ΠB(w)⊆RatA,那么 σB(w)(v2)=O2。最后,如果 A 知道 B 知道 A 是实质上理性的,那么
ΠA(w)⊆KBRatA={w′∣ΠB(w′)⊆RatA}.
一个类似的论点表明,如果 w∈RatA 并且 w∈KA(KB(RatA)),那么 σA(w)(v1)=O1。
策略配置(O1O3,O2)是图 17 中游戏的唯一纯策略_子博弈完美均衡_(Selten,1975)。此外,我们在前面段落中进行的推理与_反向归纳_算法非常接近。该算法可用于计算任何完美信息博弈中的子博弈完美均衡,其中所有玩家在每个结果上都获得唯一的收益。
BI 算法 在终端节点,玩家已经将节点标记为他们的效用。在非终端节点 v 上,一旦所有直接后继节点都被标记,节点将按如下方式标记:找到对于玩家 τ(v)(轮到他在 v 处移动的玩家)具有最高效用的直接后继节点 d。将 d 上的效用复制到 v 上。
给定一个标记的博弈树,从博弈树的根节点 v0 到与分配给 v0 的效用相匹配的结果的唯一路径称为反向归纳路径。事实上,每个节点上的标记(甚至不在反向归纳路径上的节点)都定义了博弈树上的唯一路径。这些路径可以用来为每个玩家定义策略:在每个决策节点 v 上,选择与从 v 开始的路径一致的动作。让 BI 表示由反向归纳算法给出的反向归纳策略(其中每个玩家都遵循反向归纳算法给出的策略)。
Aumann (1995) 表明上述推理可以适用于任何完全信息的广义博弈。
定理 4.7 (Aumann 1995) 假设 G 是一个完全信息的广泛博弈,s 是 G 的一个策略配置。以下命题是等价的:
存在一个状态 w 在 G 的认识模型中,使得 σ(w)=s 并且 w∈CN(Rat) (有共同知识,所有玩家都是实质理性的)。
s 是 G 的子博弈完美均衡。
这一结果已被广泛讨论。争议的标准基础是,这一论点中使用的理性的共同知识似乎是自相矛盾的,至少在直觉上是如此。回想一下,我们问过在理性的共同知识下,B 在节点 v2 会做什么,我们得出结论他会选择 O2。但是,如果游戏最终达到那个状态,那么根据上述定理,B 必须得出结论,要么 A 不是理性的,要么她不知道他是理性的。这两种情况都违反了理性的共同知识。这里是否存在矛盾?本文不会对这个问题的广泛文献进行调查。读者可以参考 Bruin 2010 中的参考文献。我们在这里要强调的是,如何看待这个潜在的悖论取决于玩家们在观察到一个在理性的共同知识下看起来“非理性”的举动后,他们将如何调整他们对“未来”理性的信念。
4.2.3 没有反向归纳的理性的共同知识
Stalnaker(1996, 1998)对反向归纳提出了不同的观点。与奥曼的分析不同之处最好通过以下例子来说明:
图 18:一个广泛的博弈
在上述博弈中,反向归纳剖面是(I1I3,I2),导致结果 o4,两个玩家都获得 3 的回报。考虑一个具有单一状态 w 的认识模型,其中 σ(w)=(O1I3,O2)。这不是反向归纳剖面,因此,根据奥曼定理(定理 4.7),在状态 w,A 和 B 之间不可能共同知道 A 和 B 都是实质上理性的。
回想一下,对于玩家 i 的策略指定了 i 在所有决策节点的选择,即使这些节点根据策略规定的早期移动是不可能到达的。因此,策略包括关于玩家在每个决策节点上有机会移动时会做什么的“反事实”信息。在单一状态认识模型中,B 知道 A 正在遵循策略 O1I3。这意味着 B 知道 A 在游戏中的选择行为有两个方面。第一,A 最初选择 O1。第二,如果 A 有机会在 v3 选择,那么她会选择 I3。现在,鉴于 B 对 A 的行为的了解,无论 B 在 v2 选择什么,他的选择都是理性的。这是显然的,因为 A 在 w 处由她的策略规定的初始选择使得 B 无法移动。如果在认识模型中的状态 w,玩家 i 在状态 w 的所有决策节点 v∈Vi 上根据策略剖面 σ(w)可达,则称玩家 i 在状态 w 处在实质上是理性的。我们已经看到 B 是显然在实质上是理性的。此外,A 在实质上是理性的,因为她知道 B 正在选择 O2(即,S−A(w)={O2})。因此,OutA(v1,O1,S−i(w))={o1},OutA(v1,OI,S−i(w))={o2};因此,A 在 v1 选择 O1 使得她在 w 处在实质上是理性的。奥曼和斯塔尔纳克之间的主要争议点归结为单一状态认识模型是否包含关于 B 在评估 B 在 v2 的假设选择 O2 时对 A 在 v3 的选择的具体看法的足够信息。
According to Aumann, B is not substantively rational: Since S−B(w)={O1I3}, we have
OutB(v2,O2,S−B(w))={o2}
and
OutB(v2,I2,S−B(w))={o4};
因此,在 w 中 v2 处 B 不是理性的(注意到 uB(o4)=3>1=uB(o2))。Stalnaker 建议玩家应该被赋予一种信念修订政策,描述了如果他们观察到与他们对对手策略的了解不一致的动作,他们将恢复到哪种信息状态。如果 B 确实学到了他可以移动,那么他已经对 A 的策略学到了一些东西。特别是,他现在知道她不能遵循任何在 v1 处选择 O1 的策略(因此,特别是她不能遵循策略 O1I3)。假设 B 倾向于对 A 的策略的意外信息做出如下反应:在得知 A 不遵循在 v1 处选择 O1 的策略后,他得出结论说她正在遵循策略 I1O3。也就是说,B 的“信念修订政策”可以总结如下:如果 A 做出了一个“不理性的动作”,那么她会做另一个。Stalnaker 解释了这种信念修订政策与他对 A 如果有机会在 v3 处选择,那么她会选择 I3 的认识之间的明显紧张关系:
认为这种信念和信念修订政策的组合存在一些不连贯的想法是混淆了认识论与因果反事实——这就好比认为因为我相信如果莎士比亚没有写《哈姆雷特》,那么它就永远不会被任何人写,我因此必须倾向于得出结论说《哈姆雷特》从未被写出,如果我得知莎士比亚实际上不是它的作者一样。(Stalnaker 1996: 152)
然后,关于 B 在 v3 时对 A 的选择的适当更新的知识(根据他指定的信念修订政策),他的策略 O2 实际上是理性的。根据 Stalnaker,节点 v 处的选择的理性应该在玩家如果到达该节点时的(反事实的)认识状态中进行评估。假设 A 知道 B 正在使用上述的信念修订政策,则 A 知道 B 在 Stalnaker 的意义上是实质上理性的。如果模型包括有关玩家信念修订政策的明确信息,则可以有实质上理性的共同知识(在 Stalnaker 的意义上),但玩家的选择并不符合向后归纳轮廓。
4.3 共同强信念和向前归纳
在前一节中,我们假设玩家解释对手在广泛博弈中的预期游戏偏离(例如,偏离向后归纳路径)作为表明该玩家将在未来决策节点上“非理性”选择的迹象。然而,这只是信念修订政策的一个例子。并不是建议玩家应该采用这种信念修订政策。Stalnaker 的核心主张是,广泛博弈的模型应包括一个描述玩家在游戏中改变他们的信念倾向的组成部分,这可能因模型而异,甚至在单个模型中的玩家之间也可能不同。
面对游戏过程中的意外行为,玩家必须决定接下来该相信什么。他们的策略将基于他们的信念如何被修正,而这又将基于他们的认识优先级——即意外行为是否应被视为一次孤立的错误,从而在认知上独立于对后续行为的信念,或者它是否揭示了玩家的期望,无论是有意还是无意地,从而揭示了她未来行为的方式。玩家必须做出决定,但理论家不应该——至少他们不应该试图概括适用于任何理性主体在所有情况下的认识优先级。(Stalnaker 1998: 54)
在认识游戏理论文献中,一个被广泛讨论的信念修正原则是合理性原则。Battigalli(1997)描述了这一信念修正原则如下:
合理性原则 一个玩家应该始终尝试解释她对对手行为的信息,假设他们没有实施“非理性”的策略。
This belief revision policy is closely related to so-called forward induction reasoning. To illustrate, consider the following imperfect information game:
。乍一看,这是令人困惑的:关于单个状态 w 分配给配置(u,l)的认知概率模型不是一个存在一个状态满足玩家不选择弱支配策略的普遍知识的模型吗?问题在于,玩家在这个模型中没有“谨慎”的信念(特别是,Bob 的信念不符合下面描述的谨慎)。回想一下,拥有谨慎信念意味着玩家不能_知道_她的对手从一组可选择的选项中_选择_了哪一个(在上述游戏中,如果 Ann_知道_Bob 选择 l,那么 u 和 d 都是“可选择”的,因此 Bob 不能_知道_Ann 选择 u)。这暗示了游戏模型的一个额外要求:让 M=⟨W,{Πi}i∈N,{pi}i∈N,σ⟩ 是一个认知概率模型。对于每个动作 a∈∪i∈NSi,令[[a]]={w∣(σ(w))i=a}。
如果对于玩家 i 在状态 w 下,a∈Si 是合理的,那么对于所有的玩家 j≠i,[[a]]∩Πj(w)≠∅。
这意味着一个玩家不能知道她的对手不会在状态 w 下选择一个被认为是合理的行动(根据某种选择规则)。这个性质被 Cubitt 和 Sugden(2011: 8)称为“决策的隐私”、“Asheim 和 Dufwenberg(2003)称之为“无外部信念”[16]。关于上述假设的详细讨论,请参见 Cubitt 和 Sugden(2011)。
鉴于上述考虑,对迭代弱支配的认识分析并不是对前一节讨论的迭代严格支配分析的简单适应。特别是,任何这样的分析都必须解决战略推理和可接受性考虑之间的冲突,其中玩家排除了对手的某些策略选择,而可接受性考虑则要求玩家必须考虑所有对手的可能选择。许多作者已经开发了解决这一冲突的框架(Brandenburger 等人,2008 年;Asheim 和 Dufwenberg,2003 年;Halpern 和 Pass,2009 年)。我们在下面概述其中一种解决方案:
关键思想是将玩家的信念表示为一个词典概率系统(LPS)。LPS 是一系列有限的概率测度(p1,p2,...,pn)和支持(概率测度 p 在状态集合 W 上定义,其支持是所有具有非零概率的状态的集合;形式上,Supp(p)={w∣p(w)>0}),这些支持不重叠。这样解释:如果(p1,...,pn)表示 Ann 的信念,那么 p1 是 Ann 对 Bob 将要做的事情的“初始假设”,p2 是 Ann 的次要假设,依此类推。在上述游戏中,我们可以描述 Bob 的信念如下:他的初始假设是 Ann 将以概率 1 选择 U,他的次要假设是她将以概率 1 选择 D。这样解释是,尽管 Bob 不排除 Ann 选择 D(即选择非理性)的可能性,但他认为这种可能性比她选择 U(即选择理性)的可能性无限小。
因此,将信念表示为词典概率测度解决了战略推理与玩家不采用弱支配策略的假设之间的冲突。然而,在迭代弱支配的认知分析中还存在另一个更基本的问题:
在可接受性下,Ann 认为一切都是可能的。但这只是一个决策理论的陈述。Ann 参与了一个游戏,所以我们可以想象她问自己:“那么 Bob 呢?他认为什么是可能的?”如果 Ann 真的认为一切都是可能的,那么似乎她应该特别考虑到 Bob 可能不这样认为!换句话说,对可接受性要求的全面分析应该包括其他玩家不符合该要求的想法。(Brandenburger 等人,2008 年:313)
论述迭代弱支配的认识特征有两个主要要素。第一个是将玩家的信念表示为词典概率系统。第二个是使用更强的信念概念:玩家假设事件 E 成立,只要 E 相对于 E 的补集 E¯¯¯¯ 是无限可能发生的(在有限空间中,这意味着 E 中的每个状态都比不在 E 中的状态更有可能发生)。关键问题是:在“理性和对理性的共同假设”事件与通过迭代移除弱支配策略而幸存的策略之间的确切关系是什么?确切的答案实际上非常微妙——细节超出了本文的范围(参见 Brandenburger 等人 2008 年)。
5.3 纳入不知情
在第 2 节介绍的博弈模型已被用于描述玩家对于在博弈情境中对手的行为和思考的不确定性。到目前为止提供的分析中,假定了博弈的结构(即谁在玩,不同玩家的偏好是什么,以及哪些行动是可用的)是玩家之间的共同知识。然而,有许多情况下,玩家并不完全了解这样的博弈。使用第 2 节的模型来描述玩家对于博弈结构并非完全了解的情况并不困难(例如,对可用行动存在一定的不确定性的情况)。
然而,这里出现了一个基础性问题。假设安认为她的对手选择行动 a 是不可能的。现在,有许多原因可以解释安为何会持有这样的观点。一方面,安可能知道一些关于她的对手将要做什么或者在想什么的信息,这使她能够排除行动 a 作为一个可能的选择——也就是说,根据安对她的对手的所有证据,她得出结论说行动 a 根本不是她的对手会做的事情。另一方面,安可能甚至无法想象她的对手会选择行动 a 的可能性。她可能心中构建的游戏模型与她的对手完全不同。基础性问题是:第 2 节中介绍的游戏模型能否忠实地代表这种后一种不确定性?
问题不在于是否可以正式描述安在这种假设下所知道和相信的内容。事实上,一个认知概率模型,其中安将她的对手选择行动 a 的概率设为零,是对安认知状态的一个完全良好的描述。问题在于,这个模型模糊了一个重要的区别,即安不知道行动 a 是一个可能的选择,和安排除行动 a 是她的对手的一个可行选项。这个区别可以通过以下来自著名的福尔摩斯短篇小说《银色火焰》(道尔,1894 年)的片段来说明:
…我看到督察的脸上表现出了极大的兴趣。 “你认为那很重要吗?”他(Gregory 督察)问道。 “非常重要。” “你有什么要我注意的地方吗?” “To the curious incident of the dog in the night-time.” “The dog did nothing in the night-time.” “That was the curious incident,” remarked Sherlock Holmes.
问题在于福尔摩斯意识到了一个特定事件(“狗没有叫”),并利用这一点得出了结论。检察官并不知道这一事件,因此(没有福尔摩斯的帮助)无法得出相同的结论。这在许多侦探故事中都是真实的:聪明的侦探不仅有能力“连接点”,而且他们也知道需要连接哪些点。我们能否用认识论模型来描述检察官的无知?[17]
假设 Ui(E) 是玩家 i 不知道事件 E 的事件。当然,如果 i 不知道 E ,那么 i 就不知道 E 是真的(Ui(E)⊆Ki(E)¯¯¯¯¯¯¯¯¯¯¯¯¯,其中 X¯¯¯¯ 表示事件 X 的补集)。回想一下,在认识论模型中(玩家的信息由分区描述),我们有负内省属性:
Ki(E)¯¯¯¯¯¯¯¯¯¯¯¯¯⊆Ki(Ki(E)¯¯¯¯¯¯¯¯¯¯¯¯¯)。
This means that if i is unaware of E, then i knows that she does not know that E. Thus, to capture a more natural definition of Ui(E) where
Ui(E)⊆Ki(E)¯¯¯¯¯¯¯¯¯¯¯¯¯∩Ki(Ki(E)¯¯¯¯¯¯¯¯¯¯¯¯¯)¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯,
we need to represent the players’ knowledge in a possibility structure where the Ki operators do not necessarily satisfy negative introspection. A possibility structure is a tuple ⟨W,{Pi}i∈N,σ⟩ where Pi:W→℘(W). The only difference with an epistemic model is that the Pi(w) do not necessarily form a partition of W. We do not go into details here—see Halpern (1999) for a complete discussion of possibility structures and how they relate to epistemic models. The knowledge operator is defined as it is for epistemic models: for each event E, Ki(E)={w∣Pi(w)⊆E}. However, S. Modica and A. Rustichini (1994, 1999) argue that even the more general possibility structures cannot be used to describe a player’s unawareness.
一种关于可能性结构上无意识的自然定义是:
U(E)=K(E)¯¯¯¯¯¯¯¯¯¯¯¯∩K(K(E)¯¯¯¯¯¯¯¯¯¯¯¯)¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯∩K(K(K(E)¯¯¯¯¯¯¯¯¯¯¯¯)¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯∩⋯
也就是说,如果一个代理人不知道 E 发生,不知道她不知道 E 发生,以此类推,那么代理人就对 E 无意识。Modica 和 Rustichini 使用上述福尔摩斯故事的变体来表明这种无意识的定义存在问题。
假设有两个信号:狗叫(d)和猫嚎(c)。此外,假设有三个状态 w1,w2,其中狗叫,w3 中猫嚎。表示没有入侵者的事件是 E={w1}(两个信号的缺失表明没有入侵者[ 18])。以下可能性结构(如果从状态 w 到状态 v 有箭头,则 v∈P(w))描述了检查员的认识状态:
![a diagram of three circles arranged in a
图 23
考虑以下计算:
K(E)={w2} (at w2, Watson knows there is a human intruder) and −K(E)={w1,w3}
K(−K(E))={w3} (at w3, Watson knows that she does not know E), and −K(−K(E))={w1,w2}.
−K(E)∩−K(−K(E))={w1} and, in fact, ⋂∞i=1(−K)i(E)={w1}
让 U(F)=⋂∞i=1(−K)i(F)。然后,
U(∅)=U(W)=U({w1})=U({w2,w3})=∅
U(E)=U({w3})=U({w1,w3})=U({w1,w2}={w1}
因此,U(E)={w1}和 U(U(E))=U({w1})=∅。这意味着在状态 w1 下,检查员不知道 E,但他知道自己不知道 E。更一般地,Dekel 等人(1998)表明,不存在满足以下性质的非平凡无意识运算符 U:
U(E)⊆K(E)¯¯¯¯¯¯¯¯¯¯¯¯∩K(E)¯¯¯¯¯¯¯¯¯¯¯¯
K(U(E))=∅
U(E)⊆U(U(E))
有大量的文献致力于开发能够表示玩家无知的模型。参见 Board, Chung, & Schipper (2011); Chen, Ely, & Luo (2012); E. Dekel et al. (1998); Halpern (2001a); Halpern & Rego (2008); 以及 Heifetz, Meier, & Schipper (2006)对与该条目相关的问题进行讨论。无知文献目录(请参阅其他互联网资源)中有这一领域的最新论文列表。
6. 游戏模型中的自我参照悖论
对于对局的认识论分析,第一步是使用在第 2 节介绍的模型之一(可能是变体)来描述玩家的知识和信念。正如我们在 2.2 节中已经指出的,有关玩家对游戏情况和彼此的知识和信念的陈述在某些模型中是普遍已知的,而在其他模型中则不是。
在任何特定的结构中,某些信念、关于信念的信念……将存在,而其他则不会存在。因此,在选择结构背后存在一个重要的隐含假设。这就是,对于玩家来说,选择的结构是“透明的”,并且只有这些信念是可能的……这个想法是,战略情境(例如历史、惯例等)有一个“背景”,并且这个“背景”导致玩家排除了某些信念。(Brandenburger & Friedenberg 2010: 801)
排除某些信念配置构成了关于决策过程中玩家推理的实质性假设。换句话说,实质性假设涉及代理人获得的信息的方式和程度,超出了用于描述玩家信息的数学结构本身所固有的信息。不难看出,在有限结构中总是存在实质性假设:例如,对于可数无限的原子命题集,对于有限结构,总是普遍已知某些逻辑一致的这些基本事实的组合是不会实现的,对于关于这些基本事实的信息和高阶信息的逻辑一致配置也是如此。另一方面,信念/知识运算符的单调性是一个典型的非实质性假设的例子。更一般地说,在我们在第 2 节中定义的游戏模型中,没有模型不普遍已知玩家相信他们信念的所有逻辑推论。[ 19]
可以比较模型在涉及的实质性假设数量上的差异吗?是否存在不做出或至少尽可能少做出实质性假设的模型?这些问题已在博弈论的认知基础领域广泛讨论过—参见 Samuelson (1992)中的讨论以及 Moscati (2009)中的参考文献。直觉上,一个没有任何实质性假设的结构必须表示所有可能的(高阶)信息状态。这样的结构是否存在将部分取决于玩家的信息态度是如何表示的—例如,作为(条件/词典式)概率测度或集合值的知识/信念函数。这些问题引发了对“丰富”模型存在性的兴趣,这些模型包含了大部分,如果不是所有,可能的(高阶)知识和信念的配置。
有不同的方法来理解一个结构如何最小化对玩家的高阶信息的实质性假设。我们在这里不试图对这个有趣的文献进行完整的概述(有关讨论和指向相关结果的参考,请参见 Brandenburger & Keisler (2006: sec. 11)和 Siniscalchi (2008: sec. 3))。一种方法是考虑所有(Harsanyi 类型-/Kripke-/认知合理性-)结构的空间,并尝试找到一个单一的结构,在某种合适的意义下,“包含”所有其他结构。这样的结构,通常称为_通用结构_(或者在范畴论的语言中称为_终结对象_),如果存在的话,将包含分析员可以想象到的任何实质性假设。已经证明这样的结构存在于 Harsanyi 类型空间中(Mertens & Zamir 1985; Brandenburger & Dekel 1993)。对于 Kripke 结构,问题的答案是否定的(Heifetz & Samet 1998; Fagin, Geanakoplos, Halpern, & Vardi 1999; Meier 2005),但对于用于描述它们的语言有一些限制(Heifetz 1999; Roy & Pacuit 2013)。
第二种方法采用内部视角,通过询问是否存在关于固定状态或类型的一组玩家对他们的对手知道或相信什么做出了任何实质性假设。其思想是在一个给定的模型中确定玩家的可能的_推测_集合。例如,在基于状态集 W 的知识结构中,这可能是所有 W 的子集或某种适当的逻辑语言中可定义的子集。如果每个代理正确地考虑了她对手的每一个可能的推测,那么一个空间被称为_完整_。一个简单的计数论证显示,当推测集是状态集的_所有_子集时,不能存在一个完整的结构(Brandenburger 2003)。然而,在这里有一个更深层次的结果,我们将在下面讨论。
布兰登堡-凯斯勒悖论
亚当·布兰登堡和 H·杰罗姆·凯斯勒(2006)介绍了以下两人,类似于罗素的悖论。悖论的陈述涉及两个概念:信念和假设。假设是玩家最强烈的信念:它是一组状态,暗示了在给定状态下的所有其他信念。我们将在下面更多地谈到对假设的解释。假设有两名玩家,安和鲍勃,考虑以下对信念的描述。
(S)安相信鲍勃假设安相信鲍勃的假设是错误的。
通过提出问题,产生了一个悖论
(Q)安是否相信鲍勃的假设是错误的?
为了简化讨论,让 C 是鲍勃在(S)中的假设,即 C 是“安相信鲍勃的假设是错误的”这个陈述。因此,(Q)问 C 是真还是假。我们将论证只有当 C 为假时,C 才为真。
假设 C 为真。那么,安相信鲍勃的假设是错误的,并且通过内省,她相信她相信这一点。也就是说,安相信 C 是正确的。此外,根据(S),安相信鲍勃的假设是 C。因此,实际上,安相信鲍勃的假设是正确的(她相信鲍勃的假设是 C 并且 C 是正确的)。所以,C 是错误的。
假设 C 为错误。这意味着安相信鲍勃的假设是正确的。也就是说,安相信 C 是正确的(根据(S),安相信鲍勃的假设是 C)。此外,根据(S),我们得出结论,安相信鲍勃假设安相信 C 是错误的。因此,安相信她相信 C 是正确的,她相信鲍勃假设她相信 C 是错误的。因此,她相信鲍勃的假设是错误的(安相信鲍勃的假设是她相信 C 是错误的,但她相信这是错误的:她相信 C 是正确的)。因此,C 是真的。
Brandenburger 和 Keisler 对上述论证进行了形式化,以证明关于所谓的假设完备结构存在的一个非常强的不可能性结果。我们需要一些符号来陈述这一结果。在两名玩家的定性类型空间中工作最为方便(定义 2.7)。两名玩家的定性类型空间(参见定义 2.7。在接下来的内容中,状态集并不重要,因此我们将其省略)是一个结构 ⟨{TA,TB},{λA,λB}⟩,其中
λA:TA→℘(TB)λB:TB→℘(TA)
一组关于 Ann 的猜想是 TA 的子集 CA⊆℘(TA)(类似地,关于 Bob 的猜想的集合是 TB 的子集 CB⊆℘(TB))。结构 ⟨{TA,TB},{λA,λB}⟩ 被称为对猜想 CA 和 CB 是假设完备的,前提是对于 CA 中的每个猜想,都有一个类型假设了该猜想(Bob 也是一样)。形式上,对于 CB 中的每个 Y∈CB,都有一个 t0∈TA,使得 λA(t0)=Y,Bob 也是一样。正如我们上面所述,一个简单的计数论证表明,当 CA=℘(TA)且 CB=℘(TB)时,假设完备模型只存在于平凡情况下。一个更深层次的结果是:
定理 6.1(Brandenburger & Keisler 2006: 定理 5.4)对于包含一阶可定义子集的猜想集合,不存在假设完备的类型结构。
请参阅补充部分,讨论此定理的证明(见第 2 节)。
请参考 Pacuit(2007)和 Abramsky&Zvesper(2010)对此结果进行广泛分析和概括。但并非一切都是坏消息:Mariotti,Meier 和 Piccione(2005)构建了一个完整的结构,其中猜想的集合是某些良好行为的拓扑空间的紧致子集。
7. 结语
对游戏的认识论观点是,玩家应被视为个体决策者,在特定信息背景下,根据自己的偏好和所拥有的信息来选择做什么。他们将做出什么决定——描述性问题——或者他们应该做出什么决定——规范性问题,取决于玩家在给定情境中使用或应该使用的决策理论选择规则。我们最后讨论了关于认识论博弈论的两个一般方法论问题,并提供了一些进一步阅读的指引。
7.1 什么是认识论博弈论试图实现的目标?
理性的共同知识是博弈论学者、哲学家和其他社会科学家在分析社会互动情境时经常诉诸的一种非正式假设。博弈论中的认识论计划表明,有许多理解方式可以解释“假设在博弈情境中存在‘理性的共同知识/信念’”的含义。
广义而言,认识论博弈论文献的大部分内容都集中在两类项目上。第一个项目的目标是描绘玩家在博弈情境中对彼此所知和所信的不同数学表征之间的关系。沿着这些方向的研究不仅提出了有趣的技术问题,涉及如何比较和对比玩家认识状态的不同数学模型,而且还突显了对博弈的认识分析的益处和局限。第二个项目涉及博弈情境中理性选择的本质。沃尔夫冈·斯波恩对这个项目的重要性进行了很好的解释:
…博弈论…可以说,在理性概念上存在混淆,对其主体(玩家)的假设非常不清晰,因此对应的决策规则也不明确…在定义博弈情境中的理性行为时的基本困难在于,一般来说,每个玩家的策略都将取决于他对其他玩家策略的期望。如果我们假设他的期望是确定的,那么他的策略选择问题将成为一个普通的最大化问题:他可以简单地选择一种策略,使自己的回报最大化,假设其他玩家会根据他给定的期望行动。但问题在于,博弈论不能将玩家对彼此行为的期望视为确定的;相反,博弈论中最重要的问题之一恰恰是决定智能玩家对其他智能玩家的行为可以合理持有什么样的期望。(斯波恩 1982: 267)
认识论博弈论的大部分工作可以被视为试图使用玩家的知识和信念的精确表征来帮助解决上述引用中提到的混淆。
7.2 替代方案:最大化期望效用之外的选择
在对游戏进行认知分析时,对玩家选择的具体建议或预测是从决策理论的选择规则中推导出来的。例如,在当代关于博弈论认知基础的文献中,大部分结果都基于最大化期望效用。然而,从方法论的角度来看,模型假设玩家遵循的选择规则只是一个可以变化的参数。近年来,已经有一些初步尝试开发具有替代选择规则的认知分析,例如 minregret Halpern & Pass (2009)。
7.3 Further reading
The reader interested in more extensive coverage of all or some of the topics discussed in this entry should consult the following articles and books.
Logic in Games by Johan van Benthem: This book uses the tools of modal logic broadly conceived to discuss many of the issues raised in this entry (2014, MIT Press).
The Language of Game Theory by Adam Brandenburger: A collection of Brandenburger’s key papers on epistemic game theory (2014, World Scientific Series in Economic Theory).
Epistemic Game Theory by Eddie Dekel and Marciano Siniscalchi: A survey paper aimed at economists covering the main technical results of epistemic game theory (2014, Available online).
Epistemic Game Theory: Reasoning and Choice by Andrés Perea: A non-technical introduction to epistemic game theory (2012, Cambridge University Press).
The Bounds of Reason: Game Theory and the Unification of the Behavioral Sciences by Herbert Gintis: This book offers a broad overview of the social and behavioral science using the ideas of epistemic game theory (2009, Princeton University Press).
Bibliography
Abramsky, S. & J.A. Zvesper, 2012, “From Lawvere to Brandenburger-Keisler: interactive forms of diagonalization and self-reference”, in Coalgebraic Methods in Computer Science (LNCS, Vol. 7399, pp. 1–19), CoRR, abs/1006.0992.
Alchourrón, C.E., P. Gärdenfors, & D. Makinson, 1985, “On the logic of theory change: Partial meet contraction and revision functions”, Journal of Symbolic Logic, 50(2): 510–530.
Apt, K. & J. Zvesper, 2010, “The role of monotonicity in the epistemic analysis of strategic games”, Games, 1(4): 381–394, doi:10.3390/g1040381
Asheim, G. & M. Dufwenberg, 2003, “Admissibility and common belief”, Game and Economic Behavior, 42: 208–234.
Aumann, R., 1976, “Agreeing to disagree”, The Annals of Statistics, 4(6): 1236–1239.
–––, 1987, “Correlated equilibrium as an expression of Bayesian rationality”, Econometrica, 55(1): 1–18.
–––, 1995, “Backward induction and common knowledge of rationality”, Games and Economic Behavior, 8(1): 6–19.
–––, 1999a, “Interactive epistemology I: Knowledge”, International Journal of Game Theory, 28(3): 263–300.
–––, 1999b, “Interactive epistemology II: Probability”, International Journal of Game Theory, 28(3): 301–314.
–––, 2010, “Interview on epistemic logic”, in V. F. Hendricks & O. Roy (Eds.), Epistemic logic: Five questions (pp. 21–35). Automatic Press.
Aumann, R. J., S. Hart, & M. Perry, 1997, “The absent-minded driver”, Games and Economic Behavior, 20(1): 102–116.
Aumann, R. & A. Brandenburger, 1995, “Epistemic conditions for Nash equilibrium”, Econometrica, 63(5): 1161–1180.
Aumann, R. & S. Hart, 1994, Handbook of game theory with economic applications (Vol. 2), Amsterdam: North Holland.
Baltag, A. & S. Smets, 2006, “Conditional doxastic models: A qualitative approach to dynamic belief revision”, in Electronic notes in theoretical computer science (Vol. 165, pp. 5–21), Springer.
Baltag, A., S. Smets, & J. Zvesper, 2009, “Keep ‘hoping’ for rationality: a solution to the backwards induction paradox”, Synthese, 169: 301–333.
Battigalli, P., 1997, “On rationalizability in extensive games”, Journal of Economic Theory, 74(1): 40–61.
Battigalli, P. & A. Friedenberg, 2012, “Forward induction reasoning revisited”, Theoretical Economics, 7(1): 57–98.
Battigalli, P. & M. Siniscalchi, 2002, “Strong belief and forward induction reasoning”, Journal of Economic Theory, 106(2): 356–391.
Battigalli, P., A. Di Tillio, & D. Samet, 2013, “Strategies and interactive beliefs in dynamic games”, in Advances in economics and econometrics: Theory and applications, Tenth World Congress, volume 1: economic theory, Cambridge: Cambridge University Press.
van Benthem, J., 2003, “Rational dynamic and epistemic logic in games”, in S. Vannucci (Ed.), Logic, game theory and social choice III, University of Siena, Department of Political Economy.
–––, 2010, Modal logic for open minds, Stanford, CA: CSLI Publications.
–––, 2011, Logical dynamics of information and interaction, Cambridge: Cambridge University Press.
van Benthem, J. & A. Gheerbrant, 2010, “Game solution, epistemic dynamics and fixed-point logics”, Fundamenta Informaticae, 100: 1–23.
van Benthem, J., P. Girard, & O. Roy, 2009, “Everything else being equal: A modal logic for Ceteris Paribus preferences”, Journal of Philosophical Logic, 38: 83–125.
van Benthem, J., E. Pacuit, & O. Roy, 2011, “Toward a theory of play: A logical perspective on games and interaction”, Games, 2(1): 52–86.
Bernheim, D., 1984, “Rationalizable strategic behavior”, Econometrica, 52: 1007–1028.
Board, O., 2003, “The not-so-absent-minded driver”, Research in Economics, 57(3): 189–200.
Board, O., K.S. Chung, & B. Schipper, 2011, “Two models of unawareness: Comparing object-based and subjective-state-space approaches”, Synthese, 179: 13–34.
Bonanno, G., 1996, “On the logic of common belief”, Mathematical Logical Quarterly, 42: 305–311.
–––, 2004, “Memory and perfect recall in extensive games”, Games and Economic Behavior, 47(2): 237–256.
–––, 2013, “A dynamic epistemic characterization of backward induction without counterfactuals”, Games and Economic Behavior, 78: 31–43.
Brandenburger, A., 2003, “On the existence of a “complete” possibility structure”, in M. Basili, N. Dimitri, & I. Gilboa (Eds.), in Cognitive processes and economic behavior (pp. 30–34). Routledge.
–––, 2007, “A note on Kuhn’s theorem”, in J. van Benthem, D. Gabbay, & B. Loewe (Eds.), Interactive logic, proceedings of the 7th Augustus de Morgan workshop, London (pp. 71–88). Texts in Logic; Games, Amsterdam University Press.
–––, 2010, “Origins of epistemic game theory”, in V. F. Hendricks & O. Roy (Eds.), Epistemic logic: Five questions (pp. 59–69). Automatic Press.
Brandenburger, A. & E. Dekel, 1987, “Rationalizability and correlated equilibria”, Econometrica, 55(6): 1391–1402.
–––, 1993, “Hierarchies of beliefs and common knowledge”, Journal of Economic Theory, 59.
Brandenburger, A. & A. Friedenberg, 2008, “Intrinsic correlation in games”, Journal of Economic Theory, 141(1): 28–67.
–––, 2010, “Self-admissible sets”, Journal of Economic Theory, 145: 785–811.
Brandenburger, A. & H. Keisler, 2006, “An impossibility theorem on beliefs in games”, Studia Logica, 84(2): 211–240.
Brandenburger, A., A. Friedenberg, & H.J. Keisler, 2008, “Admissibility in games”, Econometrica, 76(2): 307–352.
de Bruin, B., 2010, Explaining games : The epistemic programme in game theory, New York City: Springer.
Chen, Y.C., J. Ely, & X. Luo, 2012, “Note on unawareness: Negative introspection versus AU introspection (and KU introspection)”, International Journal of Game Theory, 41(2): 325 - 329.
Colman, A., 2003, “Cooperation, psychological game theory, and limitations of rationality in social interactions”, Behavioral and Brain Sciences, 26: 139–198.
Cubitt, R.P. & R. Sugden, 1994, “Rationally justifiable play and the theory of non-cooperative games”, The Economic Journal, 104(425): 798–893.
–––, 2014, “ Common reasoning in games: A Lewisian analysis of common knowledge of rationality”, Economics and Philosophy, 30(03): 285–329.
Dekel, E., B. Lipman, & A. Rustichini, 1998, “Standard state-space models preclude unawareness”, Econometrica, 66: 159–173.
Doyle, A.C., 1894, The Memoirs of Sherlock Holmes, Mineola, NY: Dover Thrift Edition, 2010.
Fagin, R., J. Geanakoplos, J. Halpern, & M. Vardi, 1999, “The hierarchical approach to modeling knowledge and common knowledge”, International Journal of Game Theory, 28(3): 331–365.
Fagin, R., J. Halpern, & N. Megiddo, 1990, “A logic for reasoning about probabilities”, Information and Computation, 87(1–2): 78–128.
Fagin, R., J. Halpern, Y. Moses, & M. Vardi, 1995, Reasoning about knowledge, Cambridge: The MIT Press.
Finetti, B., 1974, Theory of probability, vols. 1 and 2, New York: Wiley.
Friedenberg, A. & H.J. Keisler, 2011, “Iterated dominance revisited”, in Proceedings of the behavioral and quantitative game theory: Conference on future directions, ACM, New York, NY. [available online].
Friedenberg, A. & M. Meier, 2009, “The context of a game”, in Proceedings of the 12th Conference on Theoretical Aspects of Rationality and Knowledge, pp. 134–135 [available online].
Gintis, H., 2009, The bounds of reason: game theory and the unification of the behavioral sciences, Princeton: Princeton University Press.
Halpern, J.Y., 1991, “The relationship between knowledge, belief, and certainty”, Annals of Mathematics and Artificial Intelligence, 4(3): 301–322. [available online].
–––, 1997, “On ambiguities in the interpretation of game trees”, Games and Economic Behavior, 20(1): 66–96.
–––, 1999, “Set-theoretic completeness for epistemic and conditional logic”, Annals of Mathematics and Artificial Intelligence, 26: 1–27.
–––, 2001a, “Alternative semantics for unawareness”, Game and Economic Behavior, 37: 321–339.
–––, 2001b, “Substantive rationality and backward induction”, Games and Economic Behavior, 37(2): 425–435.
–––, 2003, Reasoning about uncertainty, Cambridge: The MIT Press.
–––, 2010, “Lexiographic probability, conditional probability and nonstandard probability”, Games and Economic Behavior, 68(1): 155–179.
Halpern, J.Y. & R. Pass, 2009, “A logical characterization of iterated admissibility”, in A. Heifetz (Ed.), Proceedings of the twelfth conference on theoretical aspects of rationality and knowledge (pp. 146–155).
–––, 2011, “Iterated regret minimization: A new solution concept”, Games and Economic Behavior, 74(1): 184–207 [available online].
Halpern, J.Y. & L.C. Rego, 2008, “Interactive unawareness revisited”, Games and Economic Behavior, 62(1): 232–262.
Harsanyi, J.C., 1967–68, “Games with incomplete information played by ‘Bayesian’ players, parts I–III”, Management Science, 14: 159–182; 14: 320–334; 14: 486–502.
Heifetz, A., 1999, “How canonical is the canonical model? A comment on Aumann’s interactive epistemology”, International Journal of Game Theory, 28(3): 435–442.
Heifetz, A. & P. Mongin, 2001, “Probability Logic for Type Spaces”, Games and Economic Behavior, 35(1–2): 31–53.
Heifetz, A. & D. Samet, 1998, “Knowledge spaces with arbitrarily high rank”, Games and Economic Behavior, 22(2): 260–273.
Heifetz, A., M. Meier, & B. Schipper, 2006, “Interactive unawareness”, Journal of Economic Theory, 130: 78–94.
Hendricks, V. & J. Symons, 2009, “Epistemic logic”, in E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Spring 2009 Edition), URL = <Epistemic Logic (Stanford Encyclopedia of Philosophy/Spring 2009 Edition)>.
Hoek, W. van der & M. Pauly, 2007, “Modal logic for games and information”, in P. Blackburn, J. van Benthem, & F. Wolter (Eds.), Handbook of modal logic (Vol. 3), Amsterdam: Elsevier.
Huber, F., 2009, “Formal representations of belief”, in E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Summer 2009 Edition), URL = <Formal Representations of Belief (Stanford Encyclopedia of Philosophy/Summer 2009 Edition)>.
Joyce, J., 2004, “Bayesianism”, in A. Mele & P. Rawling (Eds.), The Oxford handbook of rationality, Oxford: Oxford University Press.
Kadane, J.B. & P.D. Larkey, 1982, “Subjective probability and the theory of games”, Management Science, 28(2): 113–120. [available online]
–––, 1983, “The confusion of is and ought in game theoretic contexts”, Management Science, 29(12): 1365–1379. [available online]
Kaneko, M. & J. Kline, 1995, “Behavior strategies, mixed strategies and perfect recall”, International Journal of Game Theory, 24: 127–145.
Kline, J., 2002, “Minimum memory for equivalence between Ex Ante optimality and time-consistency”, Games and Economic Behavior, 38: 278–305.
Kuhn, H., 1953, “Extensive games and the problem of information”, in H. Kuhn & A. Tucker (Eds.), Contributions to the theory of games, vol. II, Princeton: Princeton University Press.
Lewis, D., 1969, Convention, Cambridge: Harvard University Press.
Leyton-Brown, K. & Y. Shoham, 2008, Essentials of game theory: A concise, multidisciplinary introduction, New York: Morgan & Claypool.
Lismont, L. & P. Mongin, 1994, “On the logic of common belief and common knowledge”, Theory and Decision, 37(1): 75–106.
–––, 2003, “Strong Completeness Theorems for Weak Logics of Common Belief”, Journal of Philosophical Logic, 32(2): 115–137.
Liu, F., 2011, “A two-level perspective on preference”, Journal of Philosophical Logic, 40(3): 421–439.
Lorini, E. & F. Schwarzentruber, 2010, “A modal logic of epistemic games”, Games, 1(4): 478–526.
Mariotti, T., M. Meier, & M. Piccione, 2005, “Hierarchies of beliefs for compact possibility models”, Journal of Mathematical Economics, 41: 303–324.
Mas-Colell, A., M. Winston, & J. Green, 1995, Microeconomic theory, Oxford: Oxford University Press.
Meier, M., 2005, “On the nonexistence of universal information structures”, Journal of Economic Theory, 122(1): 132–139.
Mertens, J. & S. Zamir, 1985, “Formulation of Bayesian analysis for games with incomplete information”, International Journal of Game Theory, 14(1): 1–29.
Modica, S. & A. Rustichini, 1994, “Awareness and partitional information structures”, Theory and Decision, 37: 107–124.
–––, 1999, “Unawareness and partitional information structures”, Game and Economic Behavior, 27: 265–298.
Monderer, D. & D. Samet, 1989, “Approximating common knowledge with common beliefs”, Games and Economic Behavior, 1(2): 170–190.
Morris, S., 1995, “The common prior assumption in economic theory”, Economics and Philosophy, 11(2): 227–253.
Moscati, I., 2009, Interactive and common knowledge in the state-space model (CESMEP Working Papers). University of Turin. [available online].
Myerson, R., 1997 [1991], Game theory: Analysis of conflict, Cambridge: Harvard University Press.
Osborne, M., 2003, An introduction to game theory, Oxford: Oxford University Press.
Pacuit, E., 2007, “Understanding the Brandenburger-Keisler paradox”, Studia Logica, 86(3): 435–454.
Pacuit, E. & O. Roy, 2011, “A dynamic analysis of interactive rationality”, in H. van Ditmarsch, J. Lang, & S. Ju (Eds.), Proceedings of the third international workshop on logic, rationality and interaction (Vol. 6953, pp. 244–258).
Pearce, D., 1984, “Rationalizable strategic behavior and the problem of perfection”, Econometrica, 52: 1029–1050.
Perea, A., 2007, “A one-person doxastic characterization of Nash strategies”, Synthese, 158: 251–271.
–––, 2012, Epistemic game theory: Reasoning and choice, Cambridge: Cambridge University Press.
–––, 2014, “Belief in the opponents’ future rationality”, Games and Economic Behavior, 83: 231–254.
Peterson, M., 2009, An introduction to decision theory, Cambridge: Cambridge University Press.
Piccione, M., & A. Rubinstein, 1997a, “On the interpretation of decision problems with imperfect recall”, Games and Economic Behavior, 20(1): 3–24.
–––, 1997b, “The absent-minded driver’s paradox: Synthesis and responses”, Games and Economic Behavior, 20(1): 121–130.
Rabinowicz, W., 1992, “Tortuous labyrinth: Noncooperative normal-form games between hyperrational players”, in C. Bicchieri & M. L. D. Chiara (Eds.), Knowledge, belief and strategic interaction (pp. 107–125).
Ross, D., 2010, “Game theory”, in E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Fall 2010 Edition), URL = <Game Theory (Stanford Encyclopedia of Philosophy/Fall 2010 Edition)>.
Roy, O. & E. Pacuit, 2013, “Substantive assumptions in interaction: A logical perspective”, Synthese, 190(5): 891–908.
Rubinstein, A., 1989, “The electronic mail game: Strategic behavior under ‘Almost common knowledge’”, American Economic Review, 79(3): 385–391.
–––, 1991, “Comments on the interpretation of game theory”, Econometrica, 59(4): 909–924.
Samuelson, L., 1992, “Dominated strategies and common knowledge”, Game and Economic Behavior, 4(2): 284–313.
Schelling, T., 1960, The Strategy of Conflict, Cambridge: Harvard University Press.
Schwitzgebel, E., 2010, “Belief”, in E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Winter 2010 Edition), URL = <Belief (Stanford Encyclopedia of Philosophy/Winter 2010 Edition)>.
Selten, R., 1975, “Reexamination of the perfectness concept for equilibrium points in extensive games”, International Journal of Game Theory, 4(1): 25–55. [available online].
Shoham, Y. & K. Leyton-Brown, 2008, Multiagent systems, Cambridge: Cambridge University Press.
Siniscalchi, M., 2008, “Epistemic game theory: Beliefs and types”, in S. Durlauf & L. Blume (Eds.), The new Palgrave dictionary of economics, Basingstoke: Palgrave Macmillan.
Spohn, W., 1982, “How to make sense of game theory”, Philosophy of economics: Proceedings, Munich, July 1981, W. Stegmüller, W. Balzer, & W. Spohn (eds), 239–270, Studies in Contemporary Economics, Volume 2, Berlin: Springer-Verlag.
Stalnaker, R., 1994, “On the evaluation of solution concepts”, Theory and Decision, 37(1): 49–73.
–––, 1996, “Knowledge, belief and counterfactual reasoning in games”, Economics and Philosophy, 12(02): 133–163.
–––, 1998, “Belief revision in games: forward and backward induction”, Mathematical Social Sciences, 36(1): 31–56.
–––, 1999, “Extensive and strategic forms: Games and models for games”, Research in Economics, 53(3): 293–319.
–––, 2006, “On logics of knowledge and belief”, Philosophical Studies, 128(1): 169–199.
Stuart Jr., H.W. & H. Hu, 2002, “An epistemic analysis of the Harsanyi transformation”, International Journal of Game Theory, 30(4): 517–525.
Tan, T.C.-C. & S.R. da Costa Werlang, 1988, “The Bayesian foundations of solution concepts of games”, Journal of Economic Theory, 45(2): 370–391, doi:10.1016/0022-0531(88)90276-1
Titelbaum, M., 2013, “Ten reasons to care about the sleeping beauty problem”, Philosophy Compass, 8: 1003–1017.
Ullmann-Margalit, E. & S. Morgenbesser, 1977, “Picking and choosing”, Social Research, 44: 757–785.
Vanderschraaf, P. & G. Sillari, 2009, “Common knowledge”, in E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Spring 2009 Edition), URL = <Common Knowledge (Stanford Encyclopedia of Philosophy/Spring 2009 Edition)>.
de Weerd, H., R. Verbrugge, & B. Verheij, 2013, “How much does it help to know what she knows you know? An agent-based simulation study”, Artificial Intelligence, 199–200: 67–92.
Zvesper, J., 2010, Playing with information (PhD thesis), ILLC, University of Amsterdam.
Academic Tools
Other Internet Resources
Baltag, A., and S. Smets, 2009, “Dynamic logics for interactive belief revision,” slides for ESSLLI 2009 Course.
Related Entries
belief, formal representations of | common knowledge | epistemology: Bayesian | game theory | game theory: and ethics | prisoner’s dilemma
Acknowledgments
The editors would like to thank Philippe van Basshuysen for reading this entry carefully and taking the time to inform us of a significant number of typographical errors.
Copyright © 2015 by Eric Pacuit <epacuit@umd.edu> Olivier Roy <Olivier.Roy@uni-bayreuth.de>
最后更新于



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}