
计算语言学 computational (Lenhart Schubert)
首次发表于 2014 年 2 月 6 日星期四;实质性修订于 2014 年 2 月 26 日星期三。
“人类的知识是用语言表达的。因此,计算语言学非常重要。” –马克·斯蒂德曼(Mark Steedman),ACL 主席演讲(2007 年)
计算语言学是一门科学和工程学科,关注从计算的角度理解书面和口头语言,并构建能够有用地处理和生成语言的工具,无论是批量处理还是对话设置。在语言是思维的镜子的程度上,对语言的计算理解也能提供对思考和智能的洞察。而且,由于语言是我们最自然、最多才多艺的交流方式,具备语言能力的计算机将极大地促进我们与各种机器和软件的互动,并以真正满足我们需求的方式,将互联网上的大量文本和其他资源放在我们的指尖之间。
下文概述了计算语言学的目标和方法(从历史的角度),然后详细介绍了语言结构和分析的基本概念(第 2 节),解释(第 3-5 节)和语言使用(第 6-7 节),以及语言知识的获取(第 8 节),自然语言处理中的统计和机器学习技术(第 9 节)和其他应用(第 10 节)。
1. 引言:计算语言学的目标和方法
1.1 计算语言学的目标
计算语言学的理论目标包括制定语法和语义框架,以便以计算可行的方式描述语言的句法和语义分析;发现利用语言的结构和分布(统计)特性的处理技术和学习原则;以及开发在大脑中可能发生语言处理和学习的认知和神经科学上可行的计算模型。
该领域的实际目标广泛而多样。其中一些最突出的目标包括:在某个特定主题上进行高效的文本检索;有效的机器翻译(MT);回答问题(QA),从简单的事实性问题到需要推理和描述性或论述性答案(可能带有理由)的问题;文本摘要;对文本或口语进行主题、情感或其他心理属性的分析;用于完成特定任务的对话代理人(购买、技术故障排除、旅行计划、日程维护、医疗咨询等);最终,创建具有类似人类对话能力、语言习得能力和从文本中获取知识能力的计算系统。
1.2 计算语言学的方法
计算语言学的理论和实践研究所采用的方法通常借鉴了理论语言学、哲学逻辑、认知科学(尤其是心理语言学)以及计算机科学的理论和发现。然而,从 1950 年代中期到 1970 年左右的早期工作往往比较理论中立,主要关注的是开发用于机器翻译和简单问答等应用的实用技术。在机器翻译中,核心问题是词汇结构和内容,以及为特定领域(例如天气预报)定义“子语言”和从一种语言到另一种语言的转换(例如使用相当临时的图形转换语法或转换语法)。在问答中,关注的是对特定领域中遇到的问题模式进行描述,并将这些问题模式与可能存储答案的形式(例如关系数据库)之间的关系进行刻画。
到了 20 世纪 60 年代中期,由于通用计算机的不断增强和普及,以及对人级人工智能梦想的启发,许多研究人员开始设计旨在实现真正的语言理解和对话的系统。所采用的技术和理论基础各不相同。一个最小程度依赖于语言或认知理论的例子是 Joseph Weizenbaum 的 ELIZA 程序,旨在模拟(或许是夸张)罗杰斯式心理医生。ELIZA 依靠将用户输入与存储的模式(简短的单词序列与编号的插槽交替出现,从输入中填充)进行匹配,并返回与匹配的输入模式相关联的一组输出模板之一,其中包含来自输入的材料。虽然 ELIZA 及其现代聊天机器人后代常被认为是依靠简单的欺骗,但可以说人类的口头行为在某种程度上类似于 ELIZA 的反射方式,即我们在某些情况下以“预编程”或公式化的方式运作,例如在交换问候时,或者在嘈杂的聚会上对那些除了偶尔的单词外,我们无法理解其内容的评论作出回应。
在早期,研究人员从大脑中的联想过程的思想出发,提出了一种非常不同的语言处理视角。例如,M. Ross Quillian(1968)提出了一个基于概念网络中的“传播激活”(通常对应名词的意义)的词义消歧模型,这些概念通过关系链接(通常对应动词或介词的意义)相互连接。这种“语义记忆”模型的变体由 Rumelhart、Lindsay 和 Norman(1972)等研究人员追求,并且仍然是计算语言学和认知的活跃研究范式。另一条受心理学启发的研究线路始于 20 世纪 60 年代,并由 Roger Schank 及其合作者追求了二十多年,但他的目标是完全理解故事和推理性问题回答。这项工作的一个核心原则是,句子意义的表示以及围绕少数(例如 11 个)行动原语的世界知识为中心,推理主要由与这些原语相关的规则驱动(类似观点的一个重要代表是 Yorick Wilks)。Schank 工作的最重要方面也许是认识到语言理解和推理在很大程度上依赖于大量的背景知识,包括对许多“脚本”(例如在餐馆用餐等熟悉类型的复杂事件的典型方式)和计划(人们试图实现目标的典型方式)的了解(Schank&Abelson 1977)。
更纯粹的受人工智能启发的方法也在 20 世纪 60 年代出现,例如 Sad Sam(Lindsay 1963)、Sir(Raphael 1968)和 Student(Bobrow 1968)等系统。这些系统采用了模式匹配/转换等设备,用于分析和解释英语的受限子集,以及以关系层次结构和属性-值列表的形式表示的知识,以及基于图搜索、形式推理协议和数值代数的问答方法。稍后出现的一个有影响力的想法是,AI 系统中的知识应该以过程化的方式来构建,而不是以声明性的方式——知道某事是能够执行某些功能(Hewitt 1969)。两个相当令人印象深刻的系统,shrdlu(Winograd 1972)和 Lunar(Woods 等人 1972),就是这种方法论的典型示例。它们包含了复杂的过程化语法和语法-语义映射规则,并且能够在它们的“微领域”(模拟的桌上积木和月球岩石数据库)中相当稳健地运行。此外,shrdlu 还具有重要的规划能力,这得益于微规划器目标链语言(Prolog 的前身)。所有这些方法都面临的困难是扩展语言覆盖范围、解析和解释的可靠性,以及最重要的是从微领域或几段文字的覆盖范围扩展到更多样化、更广泛的领域。扩展规模的困难很大程度上归因于“知识获取瓶颈”——编码或获取更一般理解所需的无数事实和规则的困难。关于上述最后两段提到的早期工作的经典文集包括 Marvin Minsky 的《语义信息处理》(1968)和 Schank 和 Colby 的《思维和语言的计算机模型》(1973)。
自 1970 年代以来,从纯粹的过程性方法逐渐转向旨在以更易理解、模块化、可重用的形式编码大部分语言和世界知识的方法,具有更坚实的理论基础。这一趋势得益于综合的句法-语义框架的出现,如广义短语结构语法(GPSG)、头驱动短语结构语法(HPSG)、词汇-功能语法(LFG)、树相邻语法(TAG)和组合范畴语法(CCG),在每种情况下都对语法到语义的映射以及解析的计算可行性都给予了密切的理论关注。在后一领域中最重要的发展包括 Richard Montague 对语言逻辑(尤其是内涵逻辑)语义的深刻洞察,以及 Hans Kamp 和 Irene Heim 对话语表示理论(DRT)的发展,为语言中的指代提供了系统的、语义形式化的解释。
自 20 世纪 80 年代末至 1995 年底,自然语言处理的几乎所有方面发生了重大转变:从基于语料库的统计方法(例如,1993 年季刊《计算语言学》上关于该主题的两期特刊的出现)开始。新的范式得益于机器可读文本和语音数据的日益丰富和庞大,以及对语言分布特性重要性的日益认识,强大的基于统计的学习技术的发展,并希望这些技术能够克服自其起源以来一直困扰计算语言学(以及更广泛的人工智能)的可扩展性问题。
基于语料库的方法确实在生成全面、适度准确的语音识别器、词性标注器、学习概率短语结构语法的解析器,甚至机器翻译、基于文本的问答系统和摘要系统方面取得了相当大的成功。然而,语义处理仅限于一些相对浅层的方面,例如从文本中提取特定类型事件的特定数据(例如恐怖爆炸的地点、日期、肇事者、受害者等),或者从文本语料库中提取参数类型的聚类、关系元组或释义集合。目前,基于语料库的统计方法仍然占主导地位,但似乎有一股趋势朝着将形式逻辑方法与基于语料库的统计方法相结合,以实现更深入的理解和更智能的语言理解和对话系统行为。还有一些努力将连接主义和神经网络方法与符号和逻辑方法相结合。下面的章节将详细阐述上述许多主题。计算语言学的一般参考文献有 Allen 1995、Jurafsky 和 Martin 2009 以及 Clark 等人 2010。
2. 句法和解析
2.1 结构层次
语言在多个层次上被构建,对于口语来说,从声学信号中可以找到一些模式,这些模式可以映射到音素(构成语言的可辨识连续音)。对于某种语言来说,一组在听者交换时不会影响被听者识别的单词的音素是该语言的音位。音位又是词素(最小的有意义的词段)的组成部分,而词素则是词的组成部分。(在书面语中,我们用字符、字素、音节和词来代替。)词被分组成短语,比如名词短语、动词短语、形容词短语和介词短语,这些短语是句子的结构组成部分,表达完整的思想。在更高的层次上,我们有各种类型的话语结构,尽管这通常比较松散。
已经开发了在所有这些结构层面上进行语言分析的技术,尽管空间限制不允许对单词级别以下使用的方法进行严肃讨论。然而,值得注意的是,20 世纪 80 年代和 90 年代开发的语音识别技术对将自然语言处理研究转向新的基于语料库的统计方法产生了很大影响。一个关键的思想是隐马尔可夫模型(HMMs),它将“嘈杂”的序列(例如,电话序列、音素序列或单词序列)建模为由“隐藏”的潜在状态及其转换以概率方式生成。连续的隐藏状态个别或组合地模拟从观察到的嘈杂序列中提取的更抽象、更高层次的成分,例如从音素中提取出单词,或从单词中提取出词类。生成概率和状态转移概率是这些模型的参数,重要的是这些参数可以从训练数据中学习得到。随后,可以使用快速动态规划算法(如维特比算法)将这些模型高效地应用于新数据的分析。这些非常成功的技术随后被推广到更高层次的结构,很快影响了自然语言处理的各个方面。
2.2 句法
在考虑如何表示、分析和使用语法结构之前,我们应该问一下我们对于认为某个语法“正确”或某个句子“符合语法”的依据是什么。当然,这些主要是语言学的问题,但我们给出的答案对计算语言学肯定有影响。
传统上,形式语法被设计为尽可能简洁地捕捉语言学家对句子合法性的直觉,同时也允许对特定语言(例如英语疑问句中的主-助动词倒装)和跨语言(例如陈述句中名词主语、动词和名词宾语的一致排序)进行概括。关于语言学家对句子合法性的具体判断,值得注意的是,它们在很大程度上不仅与彼此一致,而且与非语言学家的判断也一致——至少对于“明显符合语法”和“明显不符合语法”的句子(Pinker 2007)。此外,发现传统短语结构支持优雅的组合意义理论,进一步证实了传统的理论方法的可信度。
然而,传统的形式语法通常没有全面涵盖任何一种语言,并且在确定句子的正确性和错误性之间划定了鲜明的界限,而实际上人们(包括语言学家)对许多句子的语法判断是不确定或模棱两可的。此外,当我们试图处理“野外”的句子时,我们希望能够适应语言、方言和注册依赖的区域性、流派特定以及错误和粗糙的语言变体(例如拼写错误、没有标点的长句、口语中的犹豫和修正、非母语者产生的错误成分顺序以及母语者的定型错误,比如“for you and I”——可能是学校教师反对主语位置上的“you and me”的结果)。因此,语言学家理想化的语法需要在大多数实际应用中具有变异容忍性。通常情况下,满足这种需求的方式是引入比语言简洁性所允许的短语结构规则要多得多的规则,比如说,不是几百条规则,而是 1 万条或更多。这些规则并不是由语言学家(无论是计算机语言学家还是其他语言学家)直接提供的,而是可以从已经由训练有素的注释者(如语言学研究生)用基本短语树结构装饰过的书面或口语语料库中“读取”出来。无监督语法获取(通常从带有词性标注的训练语料库开始)是另一种途径(见第 9 节),但结果可能不太令人满意。结合统计训练和解析技术,这种语法的放松导致了对什么构成语法错误句子的概念的相当不同理解:它不一定是语法所拒绝的句子,而是其分析需要一些很少使用的规则的句子。
如第 1.2 节所述,计算语言学中使用的语法表示形式从过程化的形式到形式语言学中发展的形式各异,以及由计算导向的语言学家开发的系统化、可解析的变体。例如,Winograd 的 shrdlu 程序中包含了用他的程序语言表达的代码,
要解析一个句子,尝试解析一个名词短语(NP);如果失败,则返回 NIL,否则尝试解析一个动词短语(VP),如果失败或成功但还有剩余的词,则返回 NIL,否则返回成功。
同样,Woods 的 lunar 语法基于一种特定类型的过程解释的转换图(增强转换网络,或 ATN),其中句子子图可能包含标记为 NP 的边(使用 NP 子图分析 NP)后跟标记为 VP 的边(类似解释)。在这两种情况下,局部特征值(例如 NP 和 VP 的数量和人称)被注册,并且作为成功的条件进行一致性检查。一个密切相关的形式化方法是确定性子句语法(例如,Pereira&Warren 1982),它使用 Prolog 来断言“事实”,例如,如果输入的词序列包含从索引 I1 到索引 I2 的 NP 和从索引 I2 到索引 I3 的 VP,则输入包含从索引 I1 到索引 I3 的句子。(同样,特征一致性约束也可以纳入这样的断言中。)鉴于证明存在一个句子的目标,Prolog 的目标链接机制为这些断言提供了过程解释。
目前,最常用的语法结构的陈述性表示是由诺姆·乔姆斯基(Noam Chomsky)(1956 年,1957 年)定义的无上下文文法(CFGs),因为它们简单且易于解析。乔姆斯基曾经主张,只有深层语言表示是无上下文的,而表面形式是通过转换(例如,英语的被动化和疑问句形成)生成的,这导致了非无上下文语言。然而,后来证明,一方面,无限制的乔姆斯基转换语法允许计算上难以处理甚至不可判定的语言,另一方面,乔姆斯基认为需要转换分析的现象可以通过在句法范畴的规范中使用适当的特征来处理,从而在无上下文的框架内进行。值得注意的是,无限移动,例如在句子“Which car did Jack urge you to buy?”中,最后一个动词宾语的表面移动到句子前面,被证明可以通过每个嵌套的动词短语携带的类型为/NP[wh]的间隙(或斜杠)特征来分析,为前置对象的范畴与空置对象位置的范畴匹配提供了路径。在非转换语法框架中,因此使用无限制(或长距离)依赖性来代替无限制移动。同时,值得注意的是,至少有一些自然语言被证明是轻微上下文敏感的(例如,荷兰语和瑞士德语展示了交叉序列依赖性,其中一系列名词“NP1 NP2 NP3 …”需要按照相同的顺序与后续的一系列动词“V1 V2 V3 …”匹配)。似乎允许近似适度的轻微上下文敏感性的语法框架包括头语法(Head Grammar)、树相邻语法(Tree-Adjoining Grammar,TAG)、组合范畴语法(Combinatory Categorial Grammar,CCG)和线性索引语法(Linear Indexed Grammar,LIG)。 头语法允许在短语的头部(例如 VP 的初始动词,NP 的最后一个名词或句子的 VP)和已经存在的补语之间插入一个补语;它们是头驱动短语结构语法(HPSG)的历史前身,HPSG 是一种统一语法(见下文),在计算语言学中受到了广泛关注。然而,无限制的 HPSG 可以生成递归可枚举(通常只是半可决定)的语言。
一个典型(稍微简化的)上下文无关文法的样本片段如下,其中短语类型用特征-值对进行注释:
这里的 v、n、p、c 是可以取值为“过去”、“现在”、“基本”、“过去分词”等(即各种动词形式)、“1”、“2”、“3”(第一、第二、第三人称)、“单数”、“复数”以及“主语”、“宾语”等的变量。subcat 特征指示了动词的补语要求。词典将提供如下条目:
允许,例如,对句子“Thetis loves a mortal”进行短语结构分析(为简单起见,我们省略了特征名称,只保留了它们的值,并忽略了格特征):
![a tree diagram: at the top, 图 1:将句子作为解析树进行句法分析
作为 CFG 的一种变体,依存语法(DGs)也广受欢迎。与 CFG 的区别在于,通过直接将词语从属于词语(允许一个中心词有多个从属词),而不是从属于短语,来实现分层分组。例如,在图 1 的句子中,我们将 Thetis 和 mortal 视为 loves 的从属词,使用标记为 subj 和 obj 的依存链接,而冠词 a 则是 mortal 的从属词,通过依存链接 mod(表示修饰语)连接。投射性依存语法是没有交叉依存的依存语法(使得一个节点的后代形成一个连续的文本段),这些依存语法生成与 CFG 相同的语言。值得注意的是,轻微非投射性依存语法允许一个中心词支配两个分离的块,提供了与之前提到的轻微上下文敏感框架相同的生成能力,这些框架对于某些语言是必需的(Kuhlmann 2013)。
正如本节开头所指出的,传统的形式语法在覆盖范围上过于有限,在语法准则上过于僵化,无法为实际使用的自然语言提供强大的覆盖基础。直到基于大规模短语括号化语料库(尤其是宾夕法尼亚树库)的概率语法出现之前,这种情况一直存在。这种类型语法的最简单例子是概率上下文无关文法或 PCFG。在 PCFG 中,每个短语结构规则 X → Y1 … Y k 都被赋予一个概率,被视为类型为 X 的成分扩展为类型为 Y1,…,Y k 的(直接)成分序列的概率。在最低级别上,扩展概率指定了给定词性(如 Det,N 或 V)作为特定词汇出现的频率。这样的语法不仅提供了语言的结构模型,还提供了分布模型,预测了各种短语序列和最低级别的词序列的出现频率。
然而,这类最简单的模型并不能非常准确地模拟实际语言语料库的统计特征,因为给定短语类型(或词性)X 的扩展概率忽略了周围短语上下文和生成成分的更详细属性(如头词)。然而,上下文和详细属性非常有影响力;例如,在“她用{双筒望远镜,行星}探测到一颗星星”中,最后的介词短语是修饰探测到还是行星,非常依赖于词的选择。这种建模不准确导致了解析不准确(见下一小节),因此生成语法模型已经以各种方式进行了改进,例如(在所谓的词汇化模型中)允许在规则中指定特定的短语头词,或者(在树替换语法中)允许将非终结符扩展为深度为 2 或更多的子树。然而,完全准确地分布建模语言似乎需要考虑语义内容、话语结构和交际意图,而不仅仅是短语结构。可能是构式语法(例如,Goldberg 2003),强调语言固定模式(包括普通短语结构、陈词滥调和习语)与其意义和话语功能之间的耦合,将为构建足够准确的统计语言模型提供概念基础,以实现更接近人类解析准确性的能力。
2.3 解析
计算语言学在人工智能的早期阶段往往依赖于模板匹配,例如将模板(X 有 Y)或(X 上有多少个 Y)与待分析的输入进行匹配。当然,这取决于具有非常受限制的话语和任务领域。到了 20 世纪 60 年代末和 70 年代初,相当复杂的递归解析技术开始被使用。例如,Woods 的月球系统采用了自上而下的递归解析策略,以类似于第 2.2 节中粗略指示的 ATN 解释方式(尽管 ATN 原则上允许其他解析风格)。它还将识别出的成分保存在一个表中,类似于我们即将描述的解析器类别。后来的解析器受到了 Jay Earley(1970)和(分别)John Cocke、Tadao Kasami 和 Daniel Younger(例如,Younger 1967)所描述的高效且概念上优雅的 CFG 解析器的影响。后者算法被称为 CYK 或 CKY 算法,以三位独立作者命名,它特别简单,采用自下而上的动态规划方法,首先识别和记录长度为 1(即单词)的句子片段的可能类型(非终结符标签),然后是长度为 2 的句子片段的可能类型,依此类推,始终在先前发现的片段类型的基础上识别更长的短语。这个过程的运行时间与句子的长度成立方关系,可以从记录的成分中以平方时间构建解析树。CYK 算法假设一个乔姆斯基范式(CNF)语法,只允许形式为 Np → Nq Nr 或 Np → w 的产生式,即从给定的非终结符生成两个非终结符或一个单词。这只是一个表面上的限制,因为任意的 CF 语法都可以轻松转换为 CNF。
目前在完全分析句子结构方面最常用的方法是图表分析。这是一种概念上简单而高效的动态规划方法,与刚才提到的算法密切相关;即,它首先为最小成分分配可能的分析,然后根据这些分析推断出更大的成分,直到找到一个跨越给定文本或文本段的顶层类别(通常是 S)的实例。根据是否仅假设完整的成分或不完整的成分(以逐步扩展)以及我们是按照词流从左到右进行还是按照其他顺序进行(例如,某种看似最佳优先顺序),有许多变体。一个常见的变体是左角图表分析器,在其中只要它们的“左角”——即规则右侧最左边的成分已经就位,就会假设部分成分。新完成的成分被放置在议程中,然后逐个从议程中取出并用于可能作为新的更高级成分的左角,并扩展部分完成的成分。同时,已完成的成分(或者说类别)被放置在一个图表中,可以将其视为一个宽度为 n、高度为 n(已处理的单词数)的三角形表格,其中索引为(i,j)的单元格,其中 i < j,包含了到目前为止从输入位置 i 到位置 j 的所有已验证的完整成分的类别。图表既用于避免重复构建已构建的成分,又最终用于重建一个或多个全局结构分析。(如果构建了所有可能的图表条目,最终的图表将允许重建所有可能的解析。)图表分析方法在 PCFGs 中基本上没有变化,仍然在句子长度方面保持立方时间复杂度。 维护已完成图表条目的概率(以及可能的未完成条目的概率上限,用于修剪目的)是一个额外的任务。
由于它们更具表达能力,TAG 和 CCG 在最坏情况下(O(n6))比 CFG 和投影 DG 更难解析(O(n3)),至少在当前算法下是如此(有关基于自底向上动态规划的 TAG、CCG 和 LIG 的解析算法,请参见 Vijay-Shankar&Weir 1994)。然而,这并不意味着 TAG 解析或 CCG 解析在实际语法和实际语言中是不切实际的,事实上,存在对两者都具有竞争力的更常见的基于 CFG 的解析器。
最后,我们提到了使用分层(人工)神经网络(ANNs,NNs)进行句法分析的连接主义模型(请参见 Palmer-Brown 等人的 2002 年; Mayberry 和 Miikkulainen 的 2008 年; 以及 Bengio 的 2008 年的调查)。通常有一层输入单元(节点),一层或多层隐藏单元和一个输出层,其中每一层都向下一层前进(兴奋和抑制)连接,通常将更高级别的成分的证据传递给该层。在隐藏层内部也可能存在连接,实现对替代方案的合作或竞争。语言实体(如音素、单词或特定类型的短语)可以通过该层中单元的激活模式(分布式表示)或单个激活单元(局部表示)来表示。
连接主义模型需要面对的问题之一是输入是按时间顺序排列的,因此为了组合组成部分,网络必须保留有关最近处理部分的信息。两种可能的方法是使用简单循环网络(SRNs)和在局部网络中使用持续激活。SRNs 使用从隐藏层到与前一层对齐的特殊上下文单元的一对一反馈连接,实际上将它们当前的输出存储在这些上下文单元中。因此,在下一个周期,隐藏单元可以使用它们自己的先前输出以及来自输入层的新输入来确定它们的下一个输出。在局部模型中,通常假设一旦一个单元(代表特定概念)被激活,它会保持一段时间的激活状态,以便同一句子的多个部分对应的多个概念及其属性可以同时激活。出现的一个问题是如何将在特定时间点处活动的实体的属性正确地与该实体绑定,而不是与其他激活的实体绑定(这是变量绑定问题,已经产生了各种方法-参见 Browne 和 Sun 1999)。一种解决方案是假设单元激活由以全局固定频率发射的脉冲组成,并且彼此同相的脉冲列对应于相同的实体(例如,参见 Henderson 1994)。当前许多连接主义研究借鉴了符号处理的观点,假设解析将语言短语结构分配给句子,并将选择结构视为同时满足符号语言约束(或偏好)的过程。 此外,还在探索更激进的混合化和模块化形式,例如将神经网络解析器与符号栈进行接口连接,或者使用神经网络学习统计解析器所需的概率,或者将解析器网络与独立的预测网络和学习网络进行互连。有关连接主义句子处理和一些混合方法的概述(参见 Crocker 2010)。
2.4 处理句法歧义
如果自然语言在某个全面有效的可解析语法方面是结构上无歧义的,那么我们的解析技术很可能早就达到了类似人类的准确性,而不是在 90%的成分识别准确率上停滞不前。然而,事实上,语言在所有结构层面上都存在歧义:在语音层面(“recognize speech” vs. “wreck a nice beach”);在形态层面(“un-wrapped” vs. “unwrap-ped”);在词类层面(round 作为形容词、名词、动词或副词);在复合词结构层面(wild goose chase);在短语类别层面(名词性 that 从句 vs. 相对从句在“the idea that he is entertaining”中);以及修饰语(或补语)的附着(“He hit the man with the baguette”)。这里的括号示例被选择为其歧义性很容易被注意到,但是歧义远比直观上显而易见的要多,而一个中等长度的句子的替代分析数量很容易达到数千个。
自然地,不同的结构导致不同的意义,正如上面的例子所示,因此结构消歧是必不可少的。问题在于,即使在句法上明确的词语和短语中,其意义和话语功能的歧义也会加剧,如下所讨论的(第 4 节)。但在这里,我们只提到了一些已经被用来实现至少部分结构消歧的结构偏好原则。首先,一些已经被提出的心理语言学原则是右关联(RA)(或迟闭(LC)),最小附着(MA)和词汇偏好(LP)。以下例子说明了这些原则:
(2.1)
(RA)他买了我为玛丽挑选的那本书。
(注意优先将 for Mary 附着到 selected 而不是 bought。)
(2.2)
(MA?) 她为玛丽提着杂货。
(注意尽管 RA,但更倾向于将 for Mary 附加到 carried 而不是 groceries。所谓的 MA 效应实际上可能是一种类似于 LP 的动词修饰偏好。)
(2.3)
(LP) 她将在农场工作过的男人描述为牛仔。
(请注意,与其说是工作,不如说是牛仔的附着。)
文献中还注意到了一种偏好,即在并列结构中使用平行结构,如下面的例子所示:
(2.4)
他们要求加糖的茶和咖啡。
(请注意,尽管 RA,但更倾向于将[[茶和咖啡]与糖]分组。)
(2.5)
约翰决定买一本小说,而玛丽买了一本传记。
(部分省略的连词被理解为“玛丽决定买一本传记”。)
(2.6)
约翰向编辑提交了短篇小说,还有诗歌。
(部分省略的并列成分被理解为“也向编辑提交了诗歌”。)
最后,以下示例用于说明频率效应的重要性,尽管对于任何单个句子来说,这种效应很难与语义偏差分离开来(通过使用词语和短语频率来改进解析提供了更有说服力的证据)。
(2.7)
一个在空间中的物体有哪些自由度?
(注意将定语从句附加到自由度而不是自由上的偏好,这归因于自由度倾向于作为“多词”出现的倾向。)
3. 语义表示
语言用于传达意义。因此,对句法结构的分析只能在一定程度上实现机械化的中心功能,而特定句法方法的优点取决于它们在支持语义分析和从待传达的意义生成语言方面的实用性。
这并不意味着句法分析本身没有价值——它可以在语法检查和统计机器翻译等应用中提供有用的支持。但对于推断和表达语言意义的更宏大目标来说,一个基本要求是语义表示理论以及它与表面形式的关系以及它如何与背景知识的表示和使用相互作用。我们将讨论逻辑主义方法、认知科学方法以及(更简要地)新兴的统计方法来表示意义。
3.1 逻辑主义方法对意义表示的处理方式
大多数语义学家、认知科学家和人类学家都会同意,在某种意义上,语言是心灵的一面镜子。但是,关于这个原则应该如何被理解,意见存在分歧。最直接的理解,我们将其称为逻辑主义观点,认为语言本身是一个具有组合性、指示性语义的逻辑意义表示——至少当我们根据解析树添加了括号,并且可能还有其他的增强(变量、λ 运算符等)。这种观点本身并不对心理表征做出任何承诺,但是奥卡姆剃刀的应用和思维与语言的假定共同演化则表明,心理语言学本身就像语言一样。常见的反对意见“人类思维不是逻辑的”对逻辑主义者来说毫无意义,因为逻辑意义表示绝不排除非演绎推理方式(归纳、绑架等);逻辑主义者也不会被人们迅速忘记口头传达信息的确切措辞的反对意见所打动,因为输入的规范化和除了主要蕴涵之外的系统性丢弃可以解释这种遗忘。此外,假设一种类似语言的逻辑心理语言当然不排除其他的表征和思维方式,比如形象思维,并与这些方式进行协同互动(Paivio 1986; Johnston & Williams 2009)。
将语言与逻辑联系起来
由于 Richard Montague(尤其是 Montague 1970, 1973)在证明语言可以逻辑上构建方面做出了很大贡献,让我们重新考虑图 1 中的句子结构以及相应的语法规则和词汇,但这次我们要压制特征,而是指出如何组合地获得在(一种变体的)Montague 的类型论意义逻辑中表达的逻辑解释。我们稍微“扭曲”了 Montague 的类型系统,使得可能世界的参数总是出现在符号或表达式的指示中的最后,而不是最前。例如,一个二元谓词的类型将是(e → (e → (s → t)))(依次应用于一个实体,另一个实体,最后一个可能世界以产生一个真值),而不是 Montague 的类型(s → (e → (e → t))),其中世界参数是第一个。这样就省去了许多 Montague 的内涵(∧)和外延(∨)运算符的应用,并且还稍微简化了真值条件。为了简单起见,我们在这里也忽略了上下文索引,并将名词和 VP 视为关于个体的真或假,而不是个体概念(Montague 用来解释诸如“温度是 90 度且在上升”之类的句子)。
这里的带撇的成分表示相应成分的内涵逻辑翻译(或者我们可以将它们视为代表相应成分的集合论指示)。应该注意几点。首先,每个短语结构规则都伴随着一个唯一的语义规则(由 Emmon Bach(1976)提出的规则对规则假设),其中每个短语的指示完全由其直接成分的指示确定:语义是组合的。
其次,在 S'-规则中,主语被假定为一个二阶谓词,应用于 VP(一个一元谓词)的指称,以产生一个句子意义,而我们通常认为主谓语义是相反的,即 VP 的指称应用于主语。但蒙塔古坚持认为他的处理方法是正确的,因为它可以统一处理所有类型的主语-代词、名称和量化的 NP。换句话说,一个 NP 总是表示一个二阶属性,或者(粗略地说)一组一阶属性的集合(参见 Lewis 1970)。例如,Thetis 表示 Thetis(一个在特定语境中确定的个体)拥有的所有属性的集合;(更确切地说,在当前的表述中,Thetis 表示从属性到句子意义的函数,其中对于特定属性得到的意义在实体具有该属性的世界中为真);some woman 表示至少有一个女人拥有的所有属性的并集;而 every woman 表示所有女人共享的属性的集合。因此,S'-规则产生的句子意义在给定的世界中为真,当且仅当主语所表示的二阶属性将 VP 所表示的属性映射到这样一个产生真值的意义。
第三,VP′-规则中,变量 x 和 y 被假定为 e 类型(它们取基本个体作为值),并且及物动词的指称应被视为一个函数,该函数首先应用于宾语,然后应用于主语(产生一个从世界到真值的函数-一个句子意义)。VP′-规则中的 λ 抽象可以理解为确保宾语 NP(像任何 NP 一样,它表示一个二阶属性)正确应用于一个普通属性(即成为某个 x 的爱对象的属性),并且结果是相对于(仍然开放的)主语位置的谓词。以下是一个解释性的样本词汇:
注意将不定冠词(第 2 行)解释为广义量词——实际上是对两个普通属性的二阶谓词,其中这些属性具有交叉的真值域。我们可以使用原子符号表示这个二阶谓词,但上述扩展方式显示了广义量词与普通存在量词的关系。虽然这是一个相当自明的问题,但在第 4.1 节中,我们将说明句子“Thetis 爱一个凡人”经过一些 λ 转换后产生以下表示:
(∃ x [mortal(x) ∧ loves(x)(Thetis)]).
(英语句子还具有一种泛指或习惯性的解读,“Thetis 爱一般的凡人”,但我们在这里忽略了这种解读。)这种解释看起来相当经典,但这仅仅是因为我们在上述规则的词汇语义中将广义量词约简为普通量词,而不是使用原子符号。蒙塔古特别关注如“John 寻找一只独角兽”之类的内涵表达。这并不要求存在一只独角兽才能使其成立——John 与独角兽属性有一定的关系,而不是与一只现有的独角兽有关。因此,蒙塔古将所有谓词参数都视为内涵;即,他将“John 寻找一只独角兽”翻译为
seeks(λ_Q_ ∃ x[unicorn(∧ x) ∧ Q(∧ x)]) (∧john),
可以简化为将独角兽扩展化为独角兽*的版本:
寻求(λQ ∃x[独角兽*(x) ∧ Q(∧x)]) (∧ 约翰)。
但最终蒙塔古对 NP 的处理,虽然在某种意义上是他提出的语言即逻辑概念的核心,但在计算语言学中并没有被广泛采用。这部分是因为后者社区并不认为需要一个 ω 阶逻辑来处理自然语言语义,发现在各种论证位置上对 NP 的处理有些复杂,特别是在处理作用域歧义方面,涉及到多个句法分析,这一点并不吸引人,并且他们更关注其他语义问题,比如充分表示事件及其关系,并为广泛覆盖的自然语言分析开发系统性的名词和动词 "本体论"。尽管如此,将语言视为逻辑的解释在计算语义学上留下了深刻的印记,通常将该领域引导向组合方法,并在某些方法中,如 CCG,为与类型论语义紧密耦合的句法提供了基础(Bach 等,1987 年; Carpenter,1997 年)。
对于蒙塔古的基于语法的量词作用域歧义的替代方法是将形式为 Det+N(或严格来说是 Det+N-bar)的 NP 视为初始未指定的高阶谓词,以后“提升”以适用于通过对空缺术语位置进行 λ-抽象而获得的一阶谓词。例如,在句子“每个人都知道一首诗”中,对象存在性解释,我们将具有未指定的逻辑形式
knows⟨a(poem)⟩⟨every(person)⟩
(不将决定词减少为经典量词),现在我们可以“提升”⟨a(poem)⟩ 以产生
一首诗(λy 知道(y)⟨ 每个人 ⟩,
然后“提升”⟨ 每个人 ⟩ 以产生
一首诗(λy 每个人(λx 知道(y)(x))),
或者
每个人(λx 一个诗歌)(λy 知道(y)(x))。
因此,我们得到了一种解读,即有一首诗是每个人都知道的,还有一种解读是每个人都知道一些诗歌(不一定是同一首)。 (关于范围消歧义的更多内容将在第 4 节中介绍)。 这种方法的系统化版本,即 Cooper 存储(参见 Barwise&Cooper 1981),将短语的含义分为两部分,即一系列 NP 解释(作为高阶谓词)和从中提取 NP 解释的逻辑矩阵。
但也可以采取更传统的方法,首先避免在谓词的语义中使用“柯里化”(Schönfinkel-Church-Curry)函数,而是使用关系解释,使用词汇语义公式,如 loves′ = λyλx(loves(x, y)),其次,未作用域的 NP 解释被视为未作用域的限定量词(Schubert&Pelletier 1982)。因此,上述未作用域的 LF 将是 knows(⟨∃poem⟩, ⟨∀person⟩),量词的作用域以及它们的限制器的作用现在涉及“提升”量词以使其作用于句式公式,并同时引入变量。对应于两种替代作用域的两个结果是
(∃ y: poem(y))(∀ x: person(x))knows(x, y),
和
(∀x: 人(x))(∃y: 诗(y))知道(x, y)。
虽然这种策略偏离了蒙塔古语法的严格组合性,但它通常能够满足预期目的,并且在计算上的麻烦最小化。另一种与逻辑形式和作用域歧义相关的方法是最小递归语义学(MRS)(Copestake 等,2005),它进一步将表达式的有意义的部分分解,目的是允许基于约束的逐步组装这些部分成为无歧义的句子逻辑形式。另一个有趣的发展是基于延续的方法,这是从编程语言理论中引入的概念(其中延续是由当前指令之后仍需执行的步骤确定的程序执行状态)。这也允许对量词的含义进行统一解释,并提供了对“放错位置的修饰语”等现象的处理方法,例如“他喝了一杯快速的咖啡”(Barker,2004)。
逻辑语义学中的一个重要创新是话语表示理论(DRT)(Kamp 1981; Heim 1982),旨在系统地解释指代。部分目标是为指代代词的名词短语(NP)的(不)可及性提供语义解释,例如在对比的例子中,“John doesn't drive a car; *he owns it”和“John drives a car; he owns it”。更重要的是,目标是解释涉及驴子指代的句子的令人困惑的语义,例如“如果 John 拥有一头驴,他就会打它。”不仅 NP 作为 if 从句的宾语,作为指代 it 的指称是可及的,与传统的句法约束理论(基于 C-命令的概念)相反,而且我们似乎还获得了一种解释类型“John 打败了他拥有的每一头驴”,这种类型无法通过“提升”嵌入的不定冠词 a donkey 以使其在整个句子上获得作用域来获得。还有一种较弱的解读类型,“如果 John 拥有一头驴,他就会打一头他拥有的驴”,这种解读也无法通过任何作用域分析获得。Kamp 和 Heim 提出了一种动态的句子解释过程,其中逐步建立了一个话语表示结构(DRS)。DRS 由一组话语指称(变量)和一组条件组成,其中这些条件可以是简单的断言或关于话语指称的方程,或者是 DRS 的逻辑组合(而不是条件的组合)。对于所考虑的句子的 DRS 可以线性地写为
[: [x, y: john(x), donkey(y)] ⇒ [u, v: he(u), it(v), beats(u, v), u=x, v=y]]
或者以图示形式表示为
![a box with a horizontal line 图 2:对于“如果约翰拥有一头驴,他就会打它”的 DRS
这里的 x、y、u、v 是由约翰、一头驴、他和它引入的话语指称,方程式 u=x、v=y 表示了对于他和它的指称解析的结果。条件句的前提中的话语指称在结论中是可访问的,而嵌套的 DRS 中的话语指称也是可访问的。从语义上讲,最重要的观点是话语指称是动态评估的。我们将变量赋值视为一种状态,而这个状态在我们从外到内、从左到右评估 DRS 时会发生变化。例如(稍微简化一下),图 4 中的条件 DRS 在给定模型中是真的,如果能够对于使前提为真的具有域{x, y}的每个赋值扩展到使结论为真的具有域{x, y, u, v}的赋值(新状态)。
表面上看,DRT 是非组合的(尽管 DRS 构造规则与短语结构规则有系统关联);但它可以以组合形式重新表述,当然仍然具有动态语义。一种密切相关的方法,动态谓词逻辑(DPL)保留了经典的量化语法,但实际上将存在量化视为非确定性赋值,并提供了一个明确的组合替代 DRT 的方法(Groenendijk&Stokhof 1991)。也许令人惊讶的是,DRT 对实际计算语言学的影响非常有限,尽管它确实在各种项目中得到了积极应用,并继续得到应用。一个原因可能是,驴子照应在迄今为止计算语言学家最密集调查的文本语料库中很少出现(尽管可以说它在通用句子和通用段落中普遍存在且非常重要,包括在词典或诸如 Common Sense Open Mind 之类的来源中,参见第 4.3 节和第 8.3 节)。另一个原因是,非驴子代词(和确定性 NP)的引用解析可以通过诸如存在量化的斯科勒化等技术轻松处理,以便后续出现的照应可以与先前引入的斯科勒常量进行识别。实际上,事实证明,斯科勒化的显式和隐式变体,包括功能斯科勒化,甚至对于驴子照应也是可能的(例如,在句子“如果每个人都有一把枪,很多人会使用它”中,参见 Schubert 2007)。最后,DRT 和其他动态语义理论的影响有限的另一个原因可能恰恰是它们是动态的:一般情况下,公式的评估需要其前置和嵌入上下文,这会干扰用于推理目的的知识模块化的种类(即能够在各种不同的上下文中使用任何给定的知识项的能力)。 在这里应该注意的是,从 DRT、DPL 和其他动态理论到静态逻辑的直接翻译程序是存在的(例如,对于动态方法的非内涵版本,可以转换为 FOL),但如果这样的转换对于实际目的是可取的,那么问题就是从动态表示开始是否有任何优势。
主题角色和(新)戴维森表示
语言语义学中一个长期存在的问题是动词和其他语言中的论元结构中的主题角色的理论地位(例如,Dowty 1991)。许多语言中的句法标记的情况在直观上对应于诸如施事者、主题、患者、工具、接受者、目标等主题角色,而在英语中,句子的主语和宾语通常分别对应于动作的施事者和主题或患者,其他角色可以作为间接宾语或更常见的作为介词短语补语和修饰语添加。为了对这些直觉进行形式化表达,许多计算语言学家将从语言中派生的动词(和其他)谓词分解为一个核心谓词,增加了表示主题角色的显式二元关系。例如,句子
(3.1)
约翰将球踢向篱笆
可能被表示为(在确定指称后)
∃e(踢(e) ∧ 在(e, 现在 1) ∧ 施事者(e, 约翰) ∧ 主题(e, 球 2) ∧ 目标位置(e, 篱笆 3)),
其中 e 被视为踢球事件。这种表示被称为新达维德森式,承认唐纳德·达维德森对动词暗示存在量化事件的观点的支持(Davidson 1967a)。前缀 neo-表示所有的论元和附加语都是以主题角色的术语表示的,这不是达维德森提议的一部分,但在(Parsons 1990)中得到了发展。(帕森斯将主题角色的概念归功于公元前 4 世纪的梵语语法学家潘尼尼。)这种表示风格的一个优点是,它使作者免于解释规则的困扰任务,即区分动词补语(将被并入动词的论元结构)和附加语(用于添加修饰信息)。例如,在(3.1)中不清楚是否应将 to the fence 视为 kick 的一个论元,还是仅仅修改 John 踢球的动作。也许大多数语言学家会认为后者是正确的(因为可以踢一个物体而无意将其推向目标位置),但直觉往往对于一组动词(如 dribble、kick、maneuver、move 和 transport)中的至少一个是模棱两可的。
然而,主题角色也引入了新的困难。正如 Dowty(1991)所指出的,主题角色缺乏明确定义的语义。例如,虽然(3.1)明显涉及一个有机体代理对一个物理对象进行因果作用,而 PP 显然提供了一个目标位置,但在(基于网络的)句子(如 3.2-3.4)中,角色应该是什么,以及它们会携带什么语义内容,就不太清楚了:
(3.2)
海浪将松动的石头扔到我们的脚下。
(3.3)
一辆大卡车挡住了他对交通灯的视线。
(3.4)
警察使用了一只嗅探犬来闻嫌疑人的行李。
此外,从主题关系的角度来看,对补语和附加语的统一处理并不能使计算语言学家免除识别动词短语(以及类似地,名词短语和形容词短语)的被动构成成分的任务,以便在解析和解释中引导句法和语义的期望。这些被动构成成分与动词的补语密切对应,与任何附加语不同。尽管如此,主题角色表示被广泛使用,部分原因是它们与基于框架的领域知识表示非常契合。这些表示以类型(将其与继承层次结构中的超类型和子类型相关联)和一组槽(也称为属性或角色)及相应的值来表征概念,并对值施加类型约束。例如,在购买领域中,我们可能会有一个购买谓词,可能具有超类型获取,子类型如分期购买、信用购买或现金购买,并具有带有类型值的属性,例如(买方(人或团体)),(卖方(人或团体)),(物品(物品或服务)),(价格(货币金额)),以及可能的时间、地点和其他属性。与动词和名词的相关意义(如购买、出售、购买、获取、收购、接收、投资、挥霍等)相关的主题角色可以很容易地映射到上述标准槽位。这引出了规范化问题,我们将在下面的一个单独标题下简要讨论。
表达问题
在计算语言学中,一个更为重要的问题是所采用的语义表示的表达能力,涉及到事件和时间参照、非标准量词(如 most)、复数、修饰、情态和其他形式的内涵性以及具体化等现象。对这些现象的全面讨论在此处是不合适的,但对每个现象的一些评论是必要的,因为语义解释和理解(以及生成)的过程明显取决于语义表示中可用的表达手段。
从事件和情境参照的角度来看是必要的,因为许多句子似乎描述了事件或情境,并对其进行限定和参照。例如,在以下句子中
(3.5)
莫莉昨晚连续吠叫了几分钟。这吵醒了邻居们。
这个吠叫事件被断定发生在昨晚,并持续了几分钟,而指示代词“这”明显直接指向它;此外,过去时态将事件放置在言语时间之前的某个时间点(即使没有时间副词也是如此)。这些时间和因果关系可以在上述提到的戴续生(或新戴续生)框架中轻松处理:
(3.5′)
吠叫(莫莉,E)∧ 昨晚(E,S)∧ 在(E,S)之前 ∧ 持续时间(E)=分钟(N)∧ 几个(N)。 导致唤醒(E,邻居,E')∧ 在(E',S)之前。
然而,例子(3.6)和(3.7)表明,事件可以由否定或量化的公式引入,正如 Reichenbach(1947)最初提出的那样:
(3.6)
一个月没有下雨,这导致了广泛的农作物歉收。
(3.7)
每个超级大国都以其核武库威胁着对方。这种情况持续了几十年。
Barwise 和 Perry(1983)在他们的情境语义中重新构思了这个想法,尽管这种情境语义缺乏捕捉语言中表达的因果关系所需的句子和事件之间的紧密耦合。Schubert(2000)在扩展了一阶逻辑的基础上提出了解决这个问题的方法,该方法引入了一个将情境或事件与描述它们的句子连接起来的运算符。
关于像 most 这样的非标准量词,我们已经勾勒出了蒙塔古语法的广义量词方法,并指出了使用受限量词的替代方法;一个例子可能是(Most x:dog(x))friendly(x)。我们可以将 most 视为二阶谓词,也可以通过类比经典量词来指定其语义:在给定解释下,样本公式为真,只有大多数满足 dog(x)(当作为 x 的值使用时)的个体也满足 friendly(x)。类似地处理 few、many、much、almost all 等量化限定词,尽管最终还需要解决模糊性问题(当然,这超出了量词的范围,扩展到谓词和形式语义表示的所有方面)。模糊量词似乎不是设定严格的定量界限,而是传达概率信息,好像在制定量化主张时应用了一种不太可靠的测量工具,并且信息的接收者需要考虑这种不可靠性来更新信念。除了模糊性之外,讨论中的量词也不是一阶可定义的(例如,Landman 1991),因此它们不能在 FOL 中完全公理化。但这并不妨碍实际推理,可以直接在句子的逻辑表示中使用这些量词(一种自然逻辑精神的方法),或者将它们归约为 FOL 框架中的集合论或部分整体关系。
诸如复数形式的
(3.8)
人们聚集在镇广场上,
提出了一个问题,即谓词的论证可以是由多个基本个体(我们通常量化并赋予属性的个体)组成的实体。对于这个问题的大多数方法都使用了一个复数运算符,比如说 plur,它允许我们将一个单数谓词 P 映射为一个适用于集体实体的复数谓词 plur(P)。通常假设这些集体实体与原子元素(单数实体)形成一个连接半格(例如 Scha 1981; Link 1983; Landman 1989, 2000)。当假设存在一个重叠关系,并且假设半格的所有元素都有一个上确界(完备性)时,结果就是一个完全的布尔代数,除了缺少一个底元素(因为没有一个空实体是所有其他实体的一部分)。一个理论问题是复数实体的半格与构成实体的物质部分的半格之间的关系。尽管在理论细节上存在差异(例如 Link 1983; Bunt 1985),但人们一致认为这些半格应该在这个意义上对齐:当我们将构成几个单数或复数实体的物质部分进行连接时,我们应该得到这些单数或复数实体的连接的物质部分。请注意,虽然一些动词谓词(如(不及物)gather)只适用于集合,而其他一些动词谓词(如 ate a pizza)则可以适用于个体或集合。因此,像 "The children ate a pizza" 这样的句子,
(3.9)
The children ate a pizza,
允许既有集体阅读,即孩子们作为一个群体吃了一块披萨,也有分布式阅读,即每个孩子吃了一块披萨(可能是不同的一块!)在实践中处理这种歧义的一种方法是将复数名词短语视为集合指称阅读和“集合中的每个成员”阅读之间的歧义。例如,(3.9)中的孩子们将被视为集合的孩子(这是短语的基本意义)和每个孩子之间的歧义。这意味着在(3.8)中也应该有一种类型为每个人的阅读可用 - 但我们可以假设这被排除在外,因为(不及物)聚集需要一个集体论证。在这样一个句子中
(3.10)
两个偷猎者抓住了三只 aracaris,
然后我们得到四种阅读,基于每个名词短语的两种解释。没有阅读被排除,因为捕捉和被捕捉都可以是个体或集体事件。一些理论家可能会提出额外的阅读,但如果存在这些阅读,它们可以被视为至少一个术语被集体解释的阅读的派生物。但毫无争议的是,复数需要在语义表示语言中进行丰富,以允许集合作为参数。在诸如 plur(child)的表达中,既有将谓词转化为另一个谓词的 plur 运算符,也有结果集合谓词,都是非标准类型的。
修改是所有语言中普遍存在的现象,如下句所示:
(3.11)
玛丽非常聪明。
(3.12)
玛丽是一位国际名人。
(3.13)
叛乱彻底失败了。
在(3.11)中,very 作为谓词修饰语,特别是作为一个子集修饰语,因为 very(P)的事物集合是 P 的事物集合的子集。我们需要在逻辑形式中使用这样的修饰语吗?在这种情况下,我们可以通过假设 smart 具有一个隐含的关于聪明程度的参数来避免使用修饰语,其中 smart(x,d)表示 x 的聪明程度为 d;添加 d > T,其中 T 是某个阈值,表示 x 非常聪明。其他程度形容词可以类似处理。然而,对于(3.12)中的国际名人,这种策略是不可行的。国际再次是子集修饰语(而不是交集修饰语——国际名人不是既国际又名人的东西),虽然可以想象出特定组合国际名人的定义,在普通的 FOL 框架中,要求这些定义可用于构建初始逻辑形式可能会产生巨大的障碍。 (3.13)说明了第三种类型的谓词修饰,即由副词进行 VP 修饰。请注意,修饰语不能合理地被视为关于失败的 Davidsonian 事件参数的隐含断言 utter(E)。综合这些例子,表明在语义表示中允许一元谓词修饰符是可取的。紧接着的讨论提供了证实性证据。
引力已经在与蒙塔古语法的联系中提到过,并且毫无疑问,自然语言的语义表示需要以某种方式捕捉引力。这些句子
(3.14)
约翰相信我们的宇宙是无限的。
(3.15)
约翰看起来很开心。
(3.16)
约翰设计了一艘星际飞船。
(3.17)
约翰戴了一个假胡子。
所有都涉及内涵性。态度句子(3.14)的意义(以及因此的真值)取决于从属从句的意义(内涵),而不仅仅是其真值(外延)。 (3.15)的意义取决于 happy 的意义,但不要求 happy 是约翰或其他任何东西的属性。 (3.16)的意义不依赖于星际飞船的实际存在,但确实依赖于该短语的意义。而(3.17)中的假胡子指的是除了真正的胡子之外的东西,尽管其意义自然取决于胡子的意义。蒙塔古分析当然可以很好地处理这样的句子。但我们可以问一下,蒙塔古类型理论的表达丰富程度对计算语言学来说真的有多重要。首先,像(3.14)这样的句子可以用经典模态逻辑来表达,而不需要承诺更高的类型。另一方面,(3.16)比蒙塔古的“约翰寻找一只独角兽”更坚决地抵制经典模态分析,对于后者,可以进行近似的经典释义:“约翰试图(对他来说)找到一只独角兽”。对于蒙塔古的一种适度让步,足以处理(3.15)-(3.17),就是允许内涵谓词修饰符进入我们的表征词汇。然后,我们可以将 look 视为谓词修饰符,使得 look(happy)成为从 happy 的意义中派生出的新谓词。类似地,如果我们愿意将星际飞船视为一个谓词短语,就可以将 design 视为谓词修饰符,就像我们在“企业号是一艘星际飞船”中所做的那样。最后,fake 自然被视为谓词修饰符,尽管与大多数名词修饰符不同,它不是交叉的(#约翰戴了一些是胡子且是假的东西)甚至不是子集的(#约翰戴了一种特定的胡子)。 注意,这种内涵性并不要求我们采用高阶逻辑——我们迄今为止并没有量化谓词的外延或内涵,只是量化个体(除了需要允许复数实体,如前所述)。我们语义词汇中关于内涵谓词修饰符的相当有说服力的案例,加强了上述允许谓词修饰的论证(基于外延例子)。
实体化,就像已经列举的现象一样,在自然语言中也是普遍存在的。以下是一些例句。
(3.18)
人类可能正在走向自我毁灭的道路。
(3.19)
雪是白色的。
(3.20)
礼貌是一种美德。
(3.21)
鲁莽驾驶是危险的。
(3.22)
约翰生气是不寻常的。
(3.23)
我们的宇宙是无限的观念已经被否定。
(3.18) - (3.21)都是谓词实体化的例子。在(3.18)中,人类可以被看作是从名词谓词“人类”派生出来的一个抽象种类的名称,即具有词汇意义 K(人类),其中 K 将谓词意图映射到个体。抽象种类作为个体的地位可以从以下事实得到证明:“走向自我毁灭”的谓词既适用于普通个体,也适用于种类。该术语的类似名称特征在于它不能很容易地被形容词修饰。在(3.19)和(3.20)中的主语可以类似地通过种类 K(雪)和 K(-ness(礼貌))进行分析。(这里-ness 是一个谓词修饰符,将适用于普通(通常是人类)个体的谓词礼貌转化为对抽象物质礼貌的数量的谓词。)但在这些情况下,K 运算符不是源自词典,而是源自类型为“NP → N,NP' = K(N')”的规则对。这允许在实体化之前修改名词谓词,例如“蓬松的雪”或“过度的礼貌”。(3.21)的主语可以逻辑上被解释为类似于 Ka(-ly(鲁莽)(驾驶))的东西,其中 Ka 实体化动作谓词,-ly 将一元谓词意图转化为子集谓词修饰符。最后,(3.22)说明了一种句义实体化的类型,再次产生一种种类;但在这种情况下,它是一种情境的种类-其实例的特征是约翰生气。在这里,我们可以假设一个实体化运算符 Ke,它将句子意图映射到情境的种类。这种类型的句义实体化需要与从句实体化区分开来,例如在(3.14)中涉及的那种。我们提到了对(3.的可能模态逻辑分析 14),但是一种谓词分析,其中谓词适用于具体化的句子内涵(命题)实际上更有说服力,因为它允许在类似于(3.14)和(3.23)的上下文中统一处理那些从句。使用具体化运算符是对严格的蒙特戈维安方法的一种偏离,但如果我们试图通过将谓词视为对个体的真或假,而不是对任意高类型的对象的真或假来限制我们的语义表示的表达能力,并且同样地,对所有情况下的个体进行量化,即一阶量化,这是合理的。
一些计算语言学家和人工智能研究人员希望在避免标准一阶逻辑之外的表达设备方面更进一步。在 FOL 中处理内涵性的一种策略是将所有谓词功能化,只保留一个或两个。例如,我们可以将像罗密欧爱朱丽叶这样的谓词作为在特定时间“持有”的函数值来处理:Holds(loves(Romeo, Juliet), t)。在这里,爱被视为产生具体化属性的函数,而 Holds(或在某些提案中为 True),以及可能的相等性,是表示语言中唯一的谓词。然后,我们可以不借助内涵语义来形式化(3.14),例如
Holds(believes(John, infinite(Universe)), t)
(其中 t 是某个特定的时间)。在(3.18)中,人类或许可以被表示为随时间变化的所有人的集合:
∀x∀t[Holds(member(x, 人类), t) ↔ Holds(human(x), t)],
(假设了一些天真集合论的公理化);而且,作为另一个例子,(4.22)可以被解释为
持有(不寻常的(生气(约翰)),t)
(对于某个特定的时间 t)。然而,这种策略在内涵语境中的量化中遇到了困难,比如在句子“约翰相信每个星系都有一些生命形式。”中。虽然我们可以表示(不太可能的)广域解读“对于每个星系,存在一些生命形式,约翰相信该星系拥有该生命形式”,使用持有策略,但我们无法轻松表示自然的狭域解读,因为 FOL 不允许在功能术语中使用变量绑定运算符(但参见麦卡锡 1990 年)。一个完全不同的方法是在所有谓词中引入“事件性”参数,并且只有当与该谓词对应的事件性被断言为“发生”时,才将一种断言视为提供关于实际世界的事实(霍布斯 2003 年)。这种方法背后的主要实际动力是能够利用现有的 FOL 推理技术和技术。然而,目前没有理由相信在 FOL 中容易的任何推理在与自然语言结构更接近的意义表示中是困难的;相反,最近在实现自然逻辑(MacCartney&Manning 2009)方面的工作表明,一大类明显的推理最容易在句法分析的自然语言中实现(除了一些调整)- 这是一个比 FOL 方法更接近蒙塔戈维安语义的框架。
规范化,主题角色(再次),和基本元素
另一个重要问题是规范化(或标准化):为了最小化在利用语言学信息时遇到的困难,应该对初始逻辑形式应用哪些转换?选择规范表示的目的包括在先前解释的文本(和一般知识)的背景下解释进一步的文本,以及推理问答和其他推理任务。
我们可以区分两种类型的规范化:逻辑标准化和概念标准化。在命题逻辑和 FOL 中,逻辑标准化的一个例子是转换为子句形式(Skolem 化,无量词连词范式)。其理论基础是将多个逻辑等价的公式简化为单一形式,从而减少推理的组合复杂性。然而,在具有“细粒度”语义的内涵逻辑中,完全标准化可能是不可能的。在这种逻辑中,例如,认为地球是圆的信念在语义上可能与认为地球是圆的信念以及月亮是平的或不平的信念不同,尽管这些信念在逻辑上是等价的。
概念标准化涉及更根本的变化:我们用较小的词汇库中的规范术语替换表面谓词(以及可能是表示性词汇的其他元素),并/或使用主题角色或框架槽进行分解。例如,在地理领域,我们可以用一个单一的规范关系(例如,borders-on)替换(国家之间的)is next to、is adjacent to、borders on、is a neighbor of、shares a border with 等关系。在物理、交流和心理事件领域,我们可能进一步将谓词分解为原始谓词的配置。例如,我们可以用 Schank 的方式来表达“x walks”。
∃ e, e′(ptrans(e, x, x) ∧ move(e′, x, feet-of(x)) ∧ by-means-of(e′, e)),
其中 ptrans(e, x, y)是一个原始谓词,表示事件 e 是由代理人 x 对物体 y 进行的物理运输,move 表示代理人的身体运动,by-means-of 表示移动事件和物理运输事件之间的工具行动关系。正如前面讨论的那样,这些多参数谓词可以进一步分解,将 ptrans(e, x, y)重写为 ptrans(e)∧agent(e, x)∧theme(e, y),等等。与逻辑规范化一样,概念规范化旨在简化推理,并最大程度地减少推理所依赖的公理的需求。
规范化提出的一个问题,尤其是涉及到还原为原始形式的更强版本,是在这个过程中是否丧失了重要的意义。例如,邻国的概念与仅仅相邻不同,它暗示了国家人口的并存,以一种类似于当地社区邻居并存的方式。更明显的是,将步行的概念还原为通过移动自己的脚来运输自己的概念无法区分步行和奔跑、跳跃、滑冰,甚至可能连骑自行车都无法区分。因此,将概念规范化视为重要蕴涵的推理,而不是将表面逻辑形式替换为更受限制的词汇中等价的形式,可能更可取。后一种立场的另一个论点是计算方面的:如果我们将复杂的行为,如在餐馆用餐,分解为原始谓词的组合,即使在回答“约翰在餐馆用餐了吗?”这样的简单问题时,我们也需要匹配这些组合的许多原始部分。我们将在下一小节的上下文中进一步讨论原始谓词。
3.2 心理学动机的意义方法
虽然许多人工智能研究人员对语义表示和推理感兴趣,将其视为实现机器语言和推理能力的实际手段,但其他人则从建模人类认知的角度来探讨这些问题。在 20 世纪 80 年代之前,自然语言处理和认知的计算建模几乎完全在一个表征主义范式内进行,即将所有智能行为视为可归约为符号操作(纽厄尔和西蒙的物理符号系统假设)。在 20 世纪 80 年代,连接主义(或神经)模型重新兴起,并被许多人视为与表征主义方法相媲美。我们在下面的两个小标题下简要总结了这些发展。
表征主义方法
"一个物理符号系统具有普遍智能行动的必要和充分手段。" - Allen Newell 和 Herbert Simon(1976 年:116)
在代表性主义范式内工作的一些认知动机研究人员特别关注认知架构,包括概念之间的联想链接,记忆类型和表示类型之间的区别(例如,情景记忆与语义记忆,短期记忆与长期记忆,陈述性知识与程序性知识),以及此类架构的可观察处理后果,例如意义消歧,相似性判断和在处理延迟中反映的认知负荷。其他人更关注揭示似乎潜在于语言和思维之下的实际内部概念词汇和推理规则。M. Ross Quillian 的语义记忆模型以及 Rumelhart,Norman 和 Lindsay(Rumelhart 等人,1972 年; Norman 等人,1975 年)以及 Anderson 和 Bower(1973 年)开发的模型代表了前一种观点,而 Schank 及其合作者(Schank 和 Colby,1973 年; Schank 和 Abelson,1977 年; Schank 和 Riesbeck,1981 年; Dyer,1983 年)代表了后一种观点。在关于语义表示的认知动机理论中的一个共同线索是使用图形语义记忆模型,旨在捕捉概念之间的直接关系以及更间接的关联,如图 3 所示:
这个特定的例子是基于 Quillian(1968)的松散基础上的。Quillian 提出,语义记忆的一个功能是通过扩散激活来实现词义消歧。例如,处理句子“他给植物浇水”会激活水和植物这两个词,这种激活会传播到与这些词直接关联的概念,并进一步传播到这些概念的邻居,以此类推。最初激活的词的首选意义将是导致来自不同词的激活信号早期“交叉”的意义。特别是,从植物的第一个意义(生物植物的意义)传播的激活信号将在四个步骤内到达与水这个概念对应的物质,沿着表示植物可能从水中获取食物的路径,而从作为动词使用的水这个词到达同样的概念只需要两个步骤,其语义表示将表达给某个目标对象供水的想法。虽然将植物理解为制造设备的意义最终可能也会导致对水概念的激活,但相应的激活路径会更长,因此植物作为生物的意义将“胜出”。
这种概念表示在几个方面与逻辑表示不同。如前所述,其中一个区别是 Schank 和其他研究人员(例如 Wilks 1978; Jackendoff 1990)对“深层”(规范)表示和基元的强调。一个经常被引用的心理学论证是人们很快忘记他们所读或所听的确切措辞,只记住“要点”;原始分解旨在推导出这个要点。然而,这涉及到一个可疑的假设,即在解释过程中,人们会简单地忽略走到公园、漫步到公园或者闲逛到公园之间的微妙区别,并且正如前面所提到的,它忽略了看似不重要的语义细节在短时间后被从记忆中剪除,而重要的蕴涵则被保留更长时间。
在关于概念表示的理论中,另一个常见的思路是对逻辑表示和指示语义的某种不确定性。据说语言的相关语义是从语言表达到内部表示的转换,而内部表示的相关语义是它们在理解和思考中的应用方式。对于外部语言和内部(心理语言)表示来说,语义框架是否为它们提供形式真值条件是无关紧要的。对逻辑语义的拒绝有时被总结为一个格言,即不能用可能世界进行计算。
然而,似乎概念语义学和逻辑语义学之间的任何感知冲突都可以通过注意到这两种语义学是完全不同的企业,具有完全不同的目的来解决。当然,概念语义学完全适合专注于从语言到符号结构的映射(在头脑中,最终以某种形式的神经集合或电路实现),以及这些结构在理解和思考中的功能。但是,逻辑语义学也有合法的角色要发挥,既要考虑词语(和更大的语言表达式)与世界的关系,也要考虑内部语义表示的符号和表达式与世界的关系。这个角色是元理论的,因为目标不是假设可以进行计算操作的认知实体,而是提供一个关于人们使用的符号在语言中外部以及在思维中内部与他们所生活的世界之间关系的理论框架。无疑,话语至少有时意图被理解为关于世界中的事物、属性和关系的陈述,因此至少有时是真实的或虚假的。如果语言和思维无法捕捉关于世界的真理,很难理解它们如何作为应对世界的有用手段而进化。
此外,逻辑语义学表明,某些句法操作导致真理到真理的转变,而不管这些操作中所涉及的符号的具体含义(尽管对于不确定推理,这些概念仅在很大程度上被理解)。因此,逻辑语义学为评估推理规则的正确性(或否)提供了基础。虽然人类推理以及实际的人工智能系统中的推理通常需要采用不正确的方法(诱导、默认推理、贝叶斯推理、类比等),但逻辑语义学仍然提供了一个重要的视角,用于对这些方法的属性进行分类和研究。一个强有力的迹象表明,以认知为动机的语言概念表示与以逻辑为动机的表示是可以协调的,这是因为所有提出的概念表示要么从一开始就有意借鉴了逻辑(在使用谓词、连接词、集合论概念和有时量词方面),要么可以在不太困难的情况下转化为逻辑表示,尽管它们是以认知为动机的。
连接主义方法
正如前面所提到的,20 世纪 80 年代,连接主义计算模型重新出现在主流认知科学理论中(例如,Feldman 和 Ballard 1982;Rumelhart 和 McClelland 1986;Gluck 和 Rumelhart 1990)。我们在连接主义解析的讨论中已经简要描述了连接主义模型。但是,连接主义范式被认为不仅适用于专门的功能,还适用于广泛的认知任务,包括在图像中识别对象,识别语音,理解语言,进行推理和指导物理行为。重点是学习,通过调整分层神经网络中单元之间的连接权重来实现,通常通过反向传播过程来分配成功或失败输出的功过给参与产生输出的单元(Rumelhart 和 McClelland 1986)。
从一个角度来看,对连接主义和神经建模的兴趣的复兴是对认知内容和功能的抽象概念进行深入阐述的自然步骤,以至于它们可以与脑理论和神经科学进行可测试的联系。但它也可以被看作是一种范式转变,因为对于高级符号处理的关注开始与对先前基于语义网络和规则的架构的心智模型的增长怀疑联系起来。例如,Ramsay 等人(1991)认为,连接主义模型表现出的认知有趣任务的能力削弱了当时盛行的将心智视为物理符号系统的观点。但其他人继续捍卫符号处理的基本作用。例如,Anderson(1983,1993)认为,虽然符号思维的理论需要以神经可行的处理为基础,而子符号过程非常适合利用环境的统计结构,但理解这些子符号过程的相互作用需要一个在符号层面上的表示和行为理论。
一个话语的语义内容在神经网络中被表示,例如,推理问答,这意味着什么?反表征主义(或“消除主义”)的观点是,没有特定的结构可以或需要被识别为编码语义内容。输入以分布式方式修改网络的活动和各种连接的强度,以便网络的后续行为有效地实现推理问答。然而,这完全没有解释网络如何学习这种行为。最成功的神经网络实验旨在将输入模式映射到类标签或其他非常受限的输出集,并且它们需要大量的标记示例(例如,用所描述对象的类标签标记的数千个图像)来学习它们的任务。相比之下,人类擅长“一次性”学习,并且可以基于这种学习执行复杂任务。
消除主义立场的一个较不激进的替代方案,被称为亚符号假设,由 Smolensky(1988)提出,其观点是,心理过程不能完全准确地用符号操作来描述,而需要在网络中以亚符号特征的层次上进行描述,其中这些特征以分布式方式表示在网络中。这种观点并不排除连接主义系统中的单元组合实际上编码符号和由符号构建的更复杂实体(例如预测和规则)。它只是否认这些组合引发的行为可以充分地建模为符号操作。实际上,过去二三十年来的大部分神经网络研究都致力于理解神经网络如何编码符号信息(例如,参见 Smolensky 等人 1992 年;Browne 和 Sun 2001 年)。
分布式方案将一组单元及其激活状态与特定的符号或值关联起来。例如,Feldman(2006)提出概念是由一簇神经元的活动表示的;这些簇的三元组表示概念、角色和填充物(值),通过三角形节点连接在一起,以表示对象的简单属性。语言理解被视为一种模拟,将语言映射到更具体的物理行动或经验领域,由时间贝叶斯网络形式的背景知识指导。
全局方案以重叠方式对所有单元进行符号编码。一个可能的全局方案是将单元的激活状态视为命题,每个单元生成一个介于-1 和 1 之间的实数值:如果状态 q 中每个单元 i 的激活 q i 满足 p i ≤ q i ≤ 0,或者 q i = 0,或者 0 ≤ q i ≤ p i,那么状态 p 蕴含状态 q(或者说 p 至少与 q 一样具体)。然后,可以根据这些状态来解释命题符号,并根据网络状态上执行的简单最大-最小操作和符号反转来解释真值函数。(参见 Blutner,2004;然而,Blutner 最终专注于一种局部主义方案,其中单元表示原子命题,连接表示双条件。)全息神经网络方案(例如,Manger 等人,1994;Plate,2003)也可以被视为全局方案;在最简单的情况下,它们使用一个“巨型神经元”,将由复数组成的输入向量乘以一个复值矩阵;结果复值输出向量的一个分量,用极坐标表示为 re**iθ,通过 θ 的值提供分类,通过 r 的值提供置信度。这种网络的一个独特特点是它们能够从部分或噪声输入中分类或重构模式。
对于子符号假设的地位仍然是一个有争议和需要进一步研究的问题。显然,符号方法如何与神经网络方法的某些特征相匹配仍不清楚,例如它们处理新实例的能力以及在面对错误或遗漏时的优雅退化。另一方面,一些用于存储知识和进行推理的神经网络架构已被证明(或设计)与“软逻辑”(例如模糊逻辑)密切相关(例如,Kasabov 1996; Kecman 2001)或“加权注释的 Poole 系统”(Blutner 2004),这表明神经网络认知模型最终可能可被描述为这些软逻辑的实现。更关注实际进展而非生物学可行建模的研究人员还探索了符号和子符号方法混合的可能性,以获得两者的优势(例如,Sun 2001)。一个相当正式的例子是 d'Avila Garcez(2004),它借鉴了 Dov Gabbay 的思想。
最后,我们应该评论一下在一些认知科学文献中表达的观点,即语言的心理表征主要是形象化的(例如,Damasio 1994; Humphrey 1992)。当然,有大量的证据证明心理意象的现实性和重要性(Johnson-Laird 1983; Kosslyn 1994)。此外,创造性思维似乎经常依赖于可视化,正如波恩卡雷(1913)和哈达玛尔(1945)在 20 世纪初观察到的那样。但正如前面所指出的,符号和形象化的表征很可能共存并协同作用。此外,详细研究人类语言能力的认知科学家,如史蒂文·平克(1994 年,2007 年)或任何上述引用的表征主义者或连接主义研究人员,似乎都得出结论,从语言中得出的内容(以及思维本身的内容)在很大程度上是符号性的,除了否认表征的消除主义者的情况。然而,很容易看出,原始直觉可能会导致意象作为图像的假设。似乎鲜明的意识主要与视觉皮层有关,特别是 V1 区域,这也是心理意象的关键所在(例如,巴尔斯 1997 年:第 6 章)。因此,完全有可能大量的非形象化的语言编码和处理被忽视,而任何唤起的形象化工件都成为我们的意识体验的一部分。此外,对于某个给定句子所唤起的意象,内省的行为本身可能促进意象的构建和意识的产生。
3.3 统计语义学
在最广义上,统计语义学关注的是词语、短语、句子和文本的语义属性,这些属性是由它们在大型文本语料库中的分布特征所引发的。例如,诸如 "愉快"、"热情洋溢" 和 "沮丧" 等术语可以被认为在语义上相似,因为它们倾向于与相同(或类似)的附近词语一起出现。(对于某些目的,如信息检索,文档的标签可以被用作出现上下文。)通过仔细区分各种出现上下文,还可以将相似性分解为更具体的关系,如同义、蕴涵和反义。逻辑语义关系(标准)和基于分布相似性的关系之间的一个基本区别是后者是一种程度问题。此外,底层的抽象概念非常不同,统计语义学不是将字符串与世界相关联,而是仅与它们的出现上下文相关联(这个概念类似于但比维特根斯坦的使用意义概念更狭窄)。然而,统计语义学确实允许优雅的形式化。各种相似性概念和其他语义关系可以通过将表达式的出现频率视为向量的分量值来捕捉,其中分量对应于不同的出现上下文。通过这种方式,可以得到一个基于向量空间中的度量和运算符的语义概念,其中向量运算符可以以各种方式模拟布尔运算符(Gärdenfors 2000;Widdows 2004;Clarke 2012)。
但这对自然语言句子和文本的意义表示有何影响呢?从本质上讲,统计语义学中句子的表示包括句子本身。句子可以直接与分布式知识结合使用,作为能够进行推理的对象的想法是最近才出现的,而这个想法在很多年来基于大型文本语料库的问答工作中已经有所预示。这个想法得到了认可,是因为最近的努力致力于设计基于统计的算法来确定文本蕴涵,这个项目是由 2005 年开始的一系列“识别文本蕴涵”挑战赛推动的,由 PASCAL 卓越网络和最近的美国国家标准与技术研究所(NIST)组织。识别文本蕴涵需要判断一个给定的语言字符串是否蕴涵第二个字符串,这种蕴涵的意义符合人类关于一个人自然推断的直觉(依赖于对词义、一般知识(例如,任何在公司分支工作的人也在该公司工作)和偶尔的众所周知的具体事实的了解)。例如,“约翰是一位流利的法语演讲者”在文本上蕴涵着“约翰会说法语”,而“法国的美食之都是里昂”并不蕴涵“法国的首都是里昂”。有些例子是中间的;例如,“约翰出生在法国”被认为增加了约翰会说法语的可能性,但并没有完全蕴涵它(Glickman 和 Dagan 2005)。最初的竞赛结果很差(远低于随机猜测的水平),但随着本体论和关于词义、词类、关系和短语模式的一些一般公理的推理注入,结果逐渐改善(例如,de Salvo Braz 等人 2005 年)。
值得注意的是,将句子视为意义表示的概念与蒙塔古(Montague)认为语言是逻辑的观点相呼应。当然,蒙塔古将“句子”理解为无歧义的句法树。但是,文本蕴涵研究似乎正在朝着类似的概念发展,正如 Dagan 等人(2008)的工作所示,其中基于句法树的统计蕴涵关系被推广为可以用类型变量替换子树的模板。此外,Clarke(2012)提出了一个非常通用的向量代数框架用于统计语义学,其中句子的“上下文”可能包括(多个)解析和甚至(多个)逻辑形式,而统计句子的含义可以从其适当的部分组合地构建起来。在这个框架中,解释蕴涵程度的一种方式是通过蕴涵概率来衡量前提句子的每个可能逻辑形式与所讨论的假设的每个可能逻辑形式之间的关系。
3.4 在实践中使用哪种语义学?
在调查了三种相当不同的语义学派之后,我们面临的问题是哪一种派别在计算语言学实践中最为有效。从上面所说的可以清楚地看出,语义学“工具”的选择将取决于从业者的计算目标。例如,如果目标是为电路故障诊断、紧急响应、医疗突发事件或度假计划创建基于对话的问题解决系统,那么基于逻辑(或至少是符号)表示对话、潜在意图以及相关约束和知识的方法目前是唯一可行的选择。在这种情况下,符号表示是基于某种被假定为语言逻辑语义或某种心理表示理论的并不重要,只要它们是可以进行推理的表示即可。对于这些目的来说,深度学习和统计学表示的最重要的限制是它们的推理能力和响应能力非常有限。它们提供的是分类或一次性推理,而不是推理链,并且它们不生成计划、理由或扩展的语言响应。然而,神经网络技术和统计技术都可以帮助改进对话系统中的语义处理,例如通过消除词义歧义,或者根据观察到的话语或行动识别出提出或遵循的多个标准计划中的哪一个。
另一方面,如果计算目标是在某种与语言相关的行为形式的生物学合理(或生物学有效!)模型中展示类似人类的表现,例如学习正确应用词语于感知对象或关系,学习判断概念相似性,或评估话语段的语气(潜在情感),那么符号表示在计算建模中不需要起任何作用。(然而,就语言而言,它是符号的,并且是一种认知现象,子符号理论最终必须解释语言是如何产生的。)在统计语义学的情况下,基于大量文本资源的问答、检索与查询相关的文档,或机器翻译等实际应用目前远远优于试图完全理解所面临的查询或文本以及他们在任务中所带来的知识的逻辑系统。但是,上述试图将子符号和统计表示与符号表示相连接的趋势表明各种语义方法正在逐渐趋同。
4. 语义解释
4.1 将句法树映射到逻辑形式
在接下来的几段中,我们将把语义解释理解为从词流中推导出意义表示的过程,假定先前或同时进行了解析阶段的操作。换句话说,我们将句法树映射到逻辑形式(或者我们的意义表示可能是什么)。因此,与将外部指示分配给符号的解释不同,这是一种“句法语义学”(Rapaport 1995)的形式。
在程序范式的全盛时期,语义解释通常是通过一组规则来完成的,这些规则将模式与句法树的部分匹配,并添加或修改输入句子的语义表示。完成的表示可能表达要记住的事实,或者可能是可执行的命令,例如对数据库的形式查询或在机器人(模拟或真实)世界中将一个块放在另一个块上的高级指令。
然而,早在 1980 年代初期,人们就意识到可以使用与短语结构规则相关的组合语义规则将句法树映射到语义表示,这种方法比纯粹的程序范式更受青睐。在我们之前在第 3.1 节中对逻辑主义框架内的意义表示的讨论中,我们已经预示了逻辑形式计算的要点。在那里,我们看到了一些短语结构规则和词汇的示例解释规则。语义规则,例如 NP′ = Det′(N′),清楚地指示了如何将较低级别成分的逻辑形式组合起来得到较高级别成分的逻辑形式。在下图中,句子“Thetis loves a mortal”通过将先前的一组词汇和解释规则应用于短语结构树的节点,进行了自下而上、从左到右的解释。
![a tree. Parent is S-prime = 图 4:图 1 的解析树的语义解释
解释规则在第 3.1 节的树节点上重复出现,并且还显示了应用组合规则的结果(在可能的情况下进行 λ 转换)。可以看到,将 NP 作为二阶谓词的蒙塔戈维安处理会导致一些复杂性,并且当我们试图考虑量词范围的歧义时,这些复杂性会加剧。我们在第 3.1 节中提到了蒙塔古的多重解析、库珀存储方法以及对这个问题的非范围量词方法。在非范围量词方法中,对动词的关系解释,图 4 中叶节点(单词)的相应解释将变为 Thetis,λyλx(loves(x,y),λP <⟨∃P⟩>),和 mortal,而根节点的 S'将变为 loves(Thetis,⟨∃mortal⟩),以唯一地作用于(∃x:mortal(x)loves(Thetis,x))。很容易看出,当将量词带到句子层面时,多个非范围量词将导致量词顺序的多个排列。因此,在诸如“每个男人都爱某个女人”的句子中,我们将有多个解读。
4.2 将语法的作用降至次要地位
在这一点上,我们应该停下来考虑一些不符合上述非常常见但并非普遍采用的基于语法的解释方法。首先,Schank 及其合作者强调了词汇知识的作用,特别是在动词分解中使用的原始动作,以及在解释过程中关于行为模式的刻板印象的知识,几乎排除了语法。例如,以“John went …”开头的句子将导致生成一个 ptrans 的概念化(因为 go 在词汇上是以 ptrans 的方式解释的),其中 John 填充了主体角色,并且期望有一个可解释为位置的短语,作为附加到 ptrans 行为的角色配置的一部分。如果句子继续为“… to the restaurant”,则期望得到确认,并且在这一点上,将触发餐厅脚本的实例化,从而对 John 和其他在餐厅中的代理人的可能行动序列产生期望(例如,Schank 和 Abelson 1977)。这些想法具有相当大的吸引力,并且在机器理解一些段落长度的故事方面取得了前所未有的成功。另一种将语法置于语义之下的解释方法是使用特定领域的语义语法(Brown 和 Burton 1975)。虽然这些语法类似于无上下文的句法语法(可能以 ATN 方式进行过程实现),但它们的组成部分被选择为在所选择的应用领域中具有意义。例如,一个电子教学系统可能会使用测量、假设或晶体管等类别,而不是 NP,以及故障规范或电压规范等类别,而不是 VP。这些方法的重要性在于它们认识到知识如何强大地塑造我们对文本和对话的最终解释,使我们能够在存在嘈杂、有缺陷和部分语言输入的情况下进行理解。 尽管如此,自 20 世纪 70 年代以来,大多数自然语言理解社区都将句法分析视为理解过程的重要方面,部分原因是因为这个复杂过程的模块化被认为对可扩展性至关重要,部分原因是基于非常有道理的乔姆斯基观点,即即使在没有明确含义的情况下,人类的句法直觉仍然能够可靠地运作,就像他著名的句子“无色的绿色思想疯狂地睡觉”一样。
统计自然语言处理(Statistical NLP)最近才开始关注推导出可用于推理和问答的解释(正如前一小节所指出的,该领域的一些文献假设自然语言文本本身可以和应该作为推理的基础)。然而,已经有一些值得注意的努力来构建统计语义解析器,这些解析器在训练过程中学习生成逻辑表达式(LF),训练语料可以是带有 LF 注释的句子语料库,或者是问题和答案(或其他交流)的语料库,其中学习是在数据库或其他补充模型的“基础”上进行的。我们将在第 8 节中提到这类工作的例子,并对其前景进行评论。
4.3 处理语义歧义和不完全指定
我们之前指出,语言在句法结构的各个层次上都存在潜在的歧义,语义内容也是如此,即使对于句法上明确的词语、短语和句子也是如此。例如,像 bank、recover 和 cool 这样的词语即使作为同一词汇类别的成员,也有多个意义;名词复合词如 ice bucket、ice sculpture、olive oil 或 baby oil 在名词之间的基础关系(如成分或目的)上没有明确说明。在句子层面上,即使有一个确定的解析,也可能存在量词范围的歧义(“每个男人都钦佩某个女人”——罗莎·帕克斯 vs. 他的母亲);习惯性和泛指句子通常涉及时间/非时间的歧义(“赛马(经常)胆小怕事”),等等。
已经提出了许多处理各种语义歧义的技术,从心理学动机的原则到基于知识的方法、启发式和统计方法。心理学动机的原则可以通过 Quillian 的扩散激活模型(前面描述过)和在词义消歧中使用选择偏好来说明。例如,在句子“The job took five hours”中,took 可以被消歧为占用时间的意义,因为该动词的这个意义更倾向于接受一个时间补语,而 job 可以被消歧为任务(而不是职业),因为任务的概念与其时间需求之间存在直接的联想链接。基于知识的消歧的例子包括根据雕塑可以由固体材料雕刻或构建的知识将冰雕消歧为构成关系,或者根据帽子通常戴在头上的知识将戴帽子的男人消歧为穿戴关系。(可能的意义可以首先通过关于名词复合或带有修饰语的限定类型关系的启发式来缩小范围。)在范围消歧中使用的启发式原则包括岛屿约束(诸如 every 和 most 这样的量词不能将其范围扩展到本地从句之外)以及不同量词的广泛范围倾向(例如,each 往往比 some 更倾向于假设更广泛的范围)。统计方法通常提取与一个有歧义的词或短语附近的各种特征,这些特征被认为会影响要做出的选择,然后使用在注释文本语料库上训练过的分类器进行选择。使用的特征可能是特定的附近词或它们的词性或语义类别、句法依赖关系、形态特征等。 这些技术具有可学习性和稳健性的优势,但最终还需要知识为基础的技术来补充。例如,在对比的句子对中正确地限定量词的范围,比如
(4.1)
野餐上的每个孩子都在烤香肠。
(4.2)
在野餐中,每个孩子都在观看头顶上的热气球,
似乎依赖于世界知识,这种依赖方式不太可能被作为词级统计规律捕捉到。
习惯性和泛指句子特别具有挑战性的消歧问题,因为它们可能涉及时间/非时间的歧义(如前所述),此外还可能需要使用量化副词进行增强,并对表面形式缺失的量化域进行约束。例如,
(4.3)
纯种赛马在纯种时(通常)会很胆怯
没有修饰副词 "通常" 时,句子明确地是非时态的,将持久的胆怯归因于纯种赛马的普遍特征。(因此,"通常" 似乎是隐含的默认修饰副词。)但是当修饰副词存在时,该句子既可以按照非时态的解读,即许多纯种赛马具有胆怯的特点,也可以按照时态的解读,即纯种赛马普遍会频繁出现胆怯的情况。如果我们将 "纯种" 替换为 "在起跑门口",那么只有 "偶尔" 的解读仍然可用,而 "通常" 可以修饰赛马,暗示许多赛马在起跑门口习惯性地胆怯,或者它可以修饰起跑门口的情境,暗示赛马普遍在这种情境中经常胆怯;此外,对于 "在起跑门口" 这个短语的形式上的理解显然取决于对赛马比赛场景的了解。
这些句子所带来的解释挑战(或应该是)计算语言学中的重要关注点,因为人们对世界的大部分常识最自然地表达为一般性和习惯性的句子形式。系统性地解释和消除这些句子的歧义将立即为将大量知识从词典、百科全书和众包的一般性陈述集合(例如 Open Mind Common Sense 中的陈述)等来源导入形式化知识库提供一种途径(例如,Singh 等人,2002 年;Lieberman 等人,2004 年;Havasi 等人,2007 年)。许多理论家认为,这些句子的逻辑形式应该是三分结构,其中量词量化对象或情境,限定词限制量化域,核心范围(主句)对域中的元素进行断言(例如,参见 Carlson,2011 年;Cohen,2002 年;或 Carlson&Pelletier,1995 年)。挑战在于将表面结构映射到这样的逻辑形式。虽然许多上述歧义的基本原则已经得到了合理的理解,但普遍的解释算法仍然缺乏。似乎这样的算法将涉及对最初不完整、模棱两可的逻辑形式逐步详细阐述,而不是直接的语法-语义转换,因为正确形式化所依赖的特征超越了语法:它们包括 Carlson 在动词短语中个体层次/阶段层次区分和动词论元中对象层次/种层次区分等特征(Carlson,1977 年,1982 年),以及语用特征,如给定/新的区分(受词组重音的影响),词汇预设,语言背景和背景知识。
5. 对文本的理解
语义解释(计算和消除逻辑形式)与语篇理解(理解文本的意义)之间的分界线是相当任意的。然而,理解过程中严重依赖于上下文和知识的方面,如解决指代、解释依赖于上下文的名词复合词、填充“缺失”的材料、确定隐含的时间和因果关系(以及其他“连贯关系”)、解释宽松或比喻性语言,当然,将语言学信息与先前的知识整合起来等,通常被视为语篇处理的方面。
5.1 处理指代和各种形式的“缺失材料”
语言已经演化成尽可能高效地传达信息,因此避免冗长的标识性描述和其他冗长的短语,而是使用较短的短语。这种“速记”倾向的一个方面可以在指代中看到,即较早的、可能更具描述性的名词短语与后面的指代代词或确定性名词短语(带有像 the 或 these 这样的限定词)之间的共指现象。 (反向排序,即前指,偶尔也会出现。)共指是语言中另一个引起歧义的来源,对人类语言使用者几乎不可察觉(除了在模棱两可的情况下,例如“当 77 航班撞击五角大楼的墙壁时,它解体了”),但对机器而言是有问题的。
确定指代词的(共同)指示对象可以通过多种方式进行,例如语义消歧。已提出的语言学和心理语言学原则包括指示对象的性别和数目一致性、C-命令原则(例如,如果指示对象是解析树中某个祖先的兄弟姐妹,则指代词必须是代词),(非)反身约束(例如,在简单从句中,主语和宾语不能是同一指示对象,如“约翰因为事故责怪了他”),最近性/显著性(更近期/显著的指示对象更受青睐),以及中心化(在话语中最有可能被代词化的术语是“注意力的中心”)。早期的启发式算法之一是 Hobbs(1979)提出的算法,该算法利用了这些特征的几个方面来解释指代词。但是,选择偏好也很重要。例如,在句子“他撞到了装有覆盆子糖浆的酱船,把它撒了出来”中,代词可以确定与覆盆子糖浆而不是酱船指代一致,因为“撒”偏好液体(或松散的聚合物)作为其宾语。在另一种可能的延续中,“...把它撞翻了”,指示对象的选择将被颠倒,因为“撞翻”偏好坚固且竖立的物体作为其宾语。还可能涉及更微妙的世界知识,例如特里·温纳格拉德(Terry Winograd)著名的例子:“市议会拒绝了妇女们的游行许可证,因为他们担心/倡导暴力”,其中“他们”可能指的是市议会或妇女,这取决于动词的选择和所唤起的相应刻板印象。另一个复杂之处涉及对实体集合、相关实体(例如部分)、命题和事件的指代,这些指代可以成为代词(例如 they、this 和 that)或确定性名词短语(例如 this situation 或 the door(of the house))的指示对象,即使它们没有明确出现作为名词短语。 像其他类型的歧义一样,共指歧义已经通过统计技术来解决。这些技术通常考虑到像前面提到的那些因素,以及额外的特征,比如先行词的生命力和先前出现的频率,并将它们作为概率证据来选择先行词(例如,Haghighi 和 Klein 2010)。模型的参数是从一个带有共指关系和必要的句法分析的语料库中学习得到的。
简要回顾一下形式为 N N 的名词复合词,需要注意的是,与传统的复合词(如冰桶或冰雕)不同,后者可以通过丰富的词汇、启发式规则或统计技术来理解,一些复合词在不同的语境下可以获得多种含义。例如,在一个关于一个穿着兔子服装的人的故事中,"兔子人" 可能指的是完全不同的事物,或者在一个关于养兔子的人的故事中,或者在一个关于外太空的大型智能兔科动物的故事中。这些例子揭示了复合名词解释和回指消解之间的某些相似之处:至少在更困难的情况下,N N 的解释取决于先前看到的材料,并且取决于对先前材料的关键方面的理解(在当前例子中,穿着兔子服装、养兔子或类似兔子的生物的概念)。换句话说,N N 的解释,就像回指消解一样,最终是依赖于知识的,无论这些知识是来自先前的文本,还是来自预先存在的背景知识库。这种观点的一个强烈版本可以在 Fan 等人的工作中看到(2009 年),他们认为在技术背景下,即使许多看似传统的复合词也需要基于知识的详细阐述。例如,在化学背景下,HCL 溶液被认为需要详细阐述为类似于“其基础是一种化学物质,其基本结构成分是 HCL 分子”的溶液。他们提供了算法(并进行了实证测试),用于从修饰 N 到被修饰 N 的关系路径中搜索,并选择这样的关系路径作为 N N 复合词的含义。正如作者所指出的,这本质上是一种扩散激活算法,并且他们建议更广泛地应用这种方法(参见第 5.3 节关于综合解释方法)。
虽然指代词和某些名词复合词可以被视为语义内容的缩写编码,但其他形式的“速记”完全省略了语义上必要的材料,需要读者或听者填补。这种类型的普遍现象当然是省略,正如前面在句子(2.5)和(2.6)中所示,或者以下示例所示。
(5.1)
莎士比亚创造了一些词语,你也可以。
(5.2)
费利克斯比我承受更大的压力。
在(5.1)中,so 是 VP 构成词(在倒装句中)的占位符,(5.2)含有一个类似于在 x 压力下的最终谓词的隐含,其中 x 的数量需要与 Felix 所经历的(更大的)压力数量相关联。解释省略需要填补缺失的材料;这通常可以在表面层次上找到,作为一系列连续的词语(如省略和裸省略示例 2.5 和 2.6 中所示),但如(5.1)和(5.2)所示,也可能(或者另外)需要将导入的材料适应到新的语境中的语义上。当导入的材料包含指称表达式时,会出现进一步的复杂情况,如下面的(5.2)变体:
(5.2')
Felix 受到老板的压力比我更大。
这里所缺失的材料可能指的是 Felix 的老板或者我的老板(分别称为严格阅读和松散阅读),这种区别可以通过将前提 VP 的逻辑形式视为仅包含一个或两个 lambda 抽象的主题变量的出现来捕捉,即示意图如下:
λx[x 受到 Felix 的老板更大的压力], 相对于 λx[x 受到来自 x 的上司的更大压力]。
这两种解读可以分别看作是先将他的上司放在范围内,然后填充省略的材料,以及这些操作的相反顺序(Dalrymple 等,1991 年; 另请参见 Crouch,1995 年; Gregory 和 Lappin,1997 年)。其他具有挑战性的省略形式包括事件省略,如(5.3)(其中 forgot 代表 forgot to bring),完全无动词的句子,如(5.4)和(5.5),以及无主语、无动词的句子,如(5.6)和(5.7):
(5.3)
我忘记了钥匙。
(5.4)
因此,这个提议
(5.5)
从罗切斯特到奥兰多的航班,5 月 28 日?
(5.6)
真可惜。
(5.7)
那么,换乘达美航空的航班怎么样?
在应用程序中,这些和其他形式的省略(在可能的情况下)通过以下方式处理:(a)强烈依赖于关于信息类型和言语行为在话语中可能发生的领域相关期望,例如在航空旅行顾问中请求航班信息;以及(b)将话语解释为对迄今为止建立的领域特定知识表示进行增强或修改的附加信息。迄今为止,基于语料库的省略方法主要集中于在文本中识别 VP 省略的实例,并找到相应的前文材料,作为与计算正确逻辑形式的问题分开的问题(例如,参见 Hardt 1997;Nielsen 2004)。
另一个难以处理的缺失材料现象是隐含论证。例如,在句子中
(5.8)
一些一氧化碳从排气管泄漏到汽车中,但其浓度太低,不会构成任何危险,
读者需要在概念上将其浓度扩展到汽车内部空气中的浓度,并将危险扩展到汽车乘客的危险。在这个例子中,至少可以提供浓度(在化学意义上)指的是某种物质在某种介质中的浓度的词汇知识,这些需要填充的“槽位”,类似的评论也适用于危险。然而,并非所有这些槽位的填充物都是通过文本明确提供的——所提到的一氧化碳提供了其中一个填充物,但汽车内部的空气以及潜在的乘客(以及他们而不是,比如说,车内的装饰物会有风险)是通过世界知识的推理得出的。
最后,在某些情境中常见的另一种简写形式是转喻,其中与预期指称物密切相关的术语代表该指称物。例如,在机场环境中,
(5.9)
这是 574 航班吗?
在适当的情境下,"might" 可能代表“这是 574 航班的候机室吗?”同样地,在适当的情境下,"cherry" 可以代表樱桃冰淇淋,"BMW" 可以代表宝马的股票市场指数:
(5.10)
我想要两球樱桃口味的。
(5.11)
宝马上涨了 4 点。
像其他类型的欠规范一样,转喻可以从基于知识和基于语料库的角度进行研究。可以利用的知识包括选择偏好(例如,一般公司不会真正上涨),词汇概念层次结构(例如,由 WordNet 提供的),关于常见转喻关系类型的通用知识,例如部分代替整体,地点代替事件,对象代替用户,生产者代替产品等(Lakoff 和 Johnson 1980),关于何时推测此类关系的规则(例如,Weischedel 和 Sondheimer 1983),命名实体知识以及关于相关实体的知识(例如,公司可能有一个股票市场指数,该指数可能上涨或下跌)(例如,Bouaud 等人 1996; Onyshkevych 1998)。基于语料库的方法(例如,参见 Markert 和 Nissim 2007)通常使用这些知识资源,以及诸如词性标记,依存路径和潜在转喻附近的搭配等语言和统计特征。至于解释过程的其他方面(包括解析),在足够狭窄的领域中,使用深度领域知识进行转喻处理可以非常有效,而基于语料库的浅层方法在更广泛的领域中扩展性更好,但往往达不到人类标准。
5.2 建立联系
文本和口语不是由孤立的句子组成,而是由相互连接、相互关联的话语组成的,形成一个连贯的整体——通常是一个在时间和因果上有结构的叙述、一个系统的描述或解释、一系列的指令,或者一个有结构的论证(或在对话中,如后面所讨论的,问题-回答交流、请求后跟确认、混合主动规划等)。
这种结构在连续子句对的层面上已经显现出来,比如
(5.12)
约翰望着天空。天空阴暗多云。
(5.13)
约翰朝天空望去,并决定带上他的雨伞。
在(5.12)中,我们理解约翰望向天空的行为在时间上与天空中的乌云同时发生(即,乌云情况至少包含了望向事件的结束)。在更深层次上,我们还理解约翰感知到天空阴暗多云,并自然地假设约翰将乌云视为即将到来的暴风雨的先兆,就像我们自己一样。在(5.13)中,这两个从句似乎报告了连续发生的事件,而且第一个事件被理解为因果关系,约翰的决定是由他望向天空时所看到的东西驱动的;基于我们对天气和雨伞功能的了解,以及“每个人”都具备这种知识的事实,我们进一步推断约翰感知到了潜在的雨云,并打算在即将进行的行程中用雨伞防雨。
这些例子表明,解释扩展的多从句篇章依赖于叙事惯例和世界知识;(类似的情况也适用于描述性、指导性或辩论性文本)。特别是,一个动作句后面跟着一个静态观察,如(5.12)中所示,通常暗示了我们所注意到的动作-情境重叠的类型,并且连续发生的动作或事件,如(5.13)中所示,通常暗示了时间顺序和可能的因果关系,尤其是如果两个从句中的一个不是自愿行动。这些提示性推理可能反映了叙述者遵循格赖斯原则的有序性,尽管从计算的角度来看,这样的观察帮助甚少。具体任务是为叙事和其他形式的篇章制定连贯性原则,并以可用的形式阐明在各个层次上有助于连贯性的特定句法-语义属性。
因此,文献中提出了各种类型的修辞或连贯关系(在从句或更大的话语片段之间),例如,由霍布斯(1979),格罗兹和西德纳(1986)以及曼恩和汤普森(1988)提出。提出的连贯关系包括详述、举例、平行和对比等。我们将进一步讨论修辞结构,见第 6 节(关于语言生成)。
5.3 处理比喻语言
“我在困境中,超前于潮流,顺势而为,躲避危险,突破极限。我专注,任务在身,信息准确,远离毒品……我活在当下,处于边缘,超越极限,低调行事。一个高概念,低调,中程弹道的传教士。” - 乔治·卡林(“人生值得失去”,2005 年 11 月 5 日首播于 HBO)
我们已经评论了处理转喻的问题,它通常被视为修辞手法之一——一个词语或短语代表其字面意义以外的东西。然而,虽然转喻本质上是一种缩减设备,其他比喻模式,如隐喻、明喻、习语、讽刺、拟人或夸张(夸大)传达的意义,尤其是内涵意义,不容易以其他方式传达。我们在这里重点关注隐喻,因为它在某种意义上是几种其他修辞手法的一种更一般的形式。此外,它受到计算语言学家最多的关注,因为可以提出这样的论点:隐喻渗透了语言,没有明确的字面和隐喻用法之间的分界线(例如,Wilks 1978; Carbonell 1980; Lakoff and Johnson 1980; Barnden 2006)。例如,虽然“温度下降”可以被视为涉及与减少同义的下降意义,但也可以被视为一种常规隐喻,将温度下降比作物体下落。为了允许这种类型的例子,Wilks 提出了一种处理范式,其中选择性约束(例如对下降主语的物体约束)被视为仅仅是偏好而不是严格要求。
然而,处理隐喻需要更多的是放松偏好;它既依赖于上下文,也依赖于深厚的知识。例如,
(5.14)
他丢了毛巾
可以是在洗衣店环境中对平凡行为的文字描述,可以是对拳击手助手进行象征性行为的文字描述,也可以是对在任何困难的努力中承认失败的股票隐喻。但要完全理解隐喻的意义,包括惩罚性、注定失败的斗争的内涵,需要对拳击比赛的生动概念有一个清晰的理解。
在计算语言学中,一些作者(例如 Dedre Gentner,参见 Falkenhainer 等人,1989 年)将隐喻视为依赖于共享属性和关系结构(同时允许不一致的属性),直接附加到所比较的概念上。例如,当将原子与太阳系进行比较时,我们观察到电子与原子核之间的旋转关系,以及行星与太阳之间的旋转关系。但其他人指出,隐含的比较可能依赖于间接获得的属性。在这种观点中,找到一个概念的隐喻是一个在知识网络中远离原始概念的过程,通过一系列步骤将某些当前特征转化为相关特征。这是 Hofstadter 等人(1995 年)所称的“滑动”过程。其他人(例如 Martin,1990 年,借鉴 Lakoff 和 Johnson,1980 年)强调对从一个概念到另一个概念进行隐喻桥接的常规方式的预先存在的知识,例如将非生物事物视为生物事物。
鉴于隐喻对上下文和广泛知识的依赖以及语言理解各个方面仍然面临的无数困难,不令人惊讶的是,在上下文中处理隐喻的通用系统不存在,更不用说创造性地使用隐喻了。然而,马丁的 MIDAS 程序能够在基于语言的 Unix 顾问的上下文中解释各种隐喻,依赖于在 KODIAK 知识表示语言中手动编码的关于领域和隐喻映射的知识。此外,还有几个其他程序展示了分析或生成各种隐喻的能力,包括结构映射引擎(SME)(Falkenhainer 等,1989 年),Met*(Fass,1991 年),ATT-Meta(Barnden,2001 年),KARMA(Narayanan,1997 年)等。最近,Veale 和 Hao(2008 年)进行了一项关于基于滑动的隐喻方法的实证研究,使用从 WordNet 和网络收集的属性。在类似的精神下,但以 SME 为灵感,Turney(2008 年)实施了一个“潜在关系映射引擎”(LRME),以找到两个可能可比较描述的元素之间的最佳映射(大小相等);这个想法是使用基于网络的共现统计来衡量任意两个给定概念(如电子和行星)的属性相似性,以及任意两个给定概念对(如电子:核和行星:太阳)的关系相似性,将其作为优化映射的度量标准。
5.4 综合方法
显然,前面几节列举的句法、语义和语用的多种歧义和不完全规定性相互作用,并与世界知识相互作用。例如,词义消歧、指代消解和隐喻解释在句子中是相互依赖的。
(5.15)
内布拉斯加州最高法院驳回了这个椅子,因为它认为电刑是一种残忍的死刑方式。
首先要注意的是,它在句法上可以指代内布拉斯加州最高法院或椅子,但世界知识排除了中性性别的椅子表现出心理态度的可能性。还要注意,如果它被替换为他,那么椅子就被重新解释为一个人,并成为代词的指称对象;同时,"驳回" 也被重新解释为一种意味着无情的将某人免职的隐喻。
因此,似乎有必要找到一个统一的框架来共同解决所有形式的歧义和不完全规定性,至少在它们的解决对推理产生影响的程度上。一些已经提出的框架包括加权推理、约束求解和“宽松语言”解释。加权推理(Hobbs 等,1993 年)的基本思想是,听者或读者的任务是通过将句子的含义视为一般和语境知识以及一些假设的逻辑结果来解释句子的词序列,而这些假设应尽可能“轻量级”。约束求解方法将语法、语义、语用、语境和世界知识视为对需要同时满足的解释提供约束。通常,约束被视为可废除的或者有优先级的,这样的话目标就是最小化约束违反,特别是相对强约束的违反。(这与认知语言建模中的最优理论有关。)宽松语言解释(Fan 等,2009 年,在名词复合解释方面之前引用过)放弃了句法歧义,但试图处理名词复合、转喻和其他语言设备中普遍存在的语义松散性。它通过扩展语义三元组(从初步逻辑形式中得到)的方式来实现,类型为 ⟨Class1,关系,Class2⟩,其中关系不能正确地将指定的类关联起来,而是将其扩展为包含该关系并以这些类为终点的更长的链。找到这样的链条取决于关于在感兴趣领域中可能存在的关系的背景知识。
前景展望
刚才提到的方法已经应用于受限任务中,但并未解决全面语言解释的问题。它们都面临效率问题,并且由于它们都依赖于丰富的语言和世界知识基础,因此存在知识获取瓶颈。我们在这里评论效率问题,但将知识获取的讨论留给第 8 节。
鉴于人们消除歧义和理解语言的速度,可以推测这些过程更接近于将观察到的文本或话语与熟悉的模式相匹配,而不是解决复杂的推理或约束满足问题。例如,在句子中:
(5.16)
他把切菜板掉在玻璃上,但它没有破碎,
尽管世界知识会预测玻璃会破裂,而切菜板不会,但代词被理解为指向玻璃。(沟通关注意外的观点在这里没有帮助,因为如果我们将 "didn't break" 改为 "broke",指代物仍然不变。)这在解释过程中是可以预期的,只要概念上脆弱物体破裂与玻璃破裂相匹配(无论确切的逻辑结构如何),并在选择指代物时使用该匹配。Winograd 在第 5.1 节中的例子处理,涉及拒绝一群妇女的游行许可证,可能也部分取决于人们熟悉的观念,即(寻求)游行的人可能会支持某种事业。请注意,
(5.17)
市议会授予妇女游行许可证,因为她们没有提倡暴力
尽管通常来说,像市议员这样的社会支柱不会提倡暴力,但妇女仍然被优先选择为 "they" 的指代物。
如果在语言理解中,消歧和(至少初步的)解释的过程更多地受到学习模式的引导而不是形式化知识的指导,那么类似于基于特征的统计自然语言处理中使用的方法可能适用于它们的有效机械化。
6. 语言生成
由于语言生成是一种受内部目标驱动的有目的的活动,很难在目标导向的思维和随之而来的语言产出之间划定界限。通常,这个过程被分为内容规划、微观规划、表层实现和物理呈现。虽然后三个阶段可以被认为是在相对较小的信息块上操作(例如,导致一两个句子或其他话语类型),但内容规划通常被视为一个连续的目标导向的交际规划过程,适当时会将一小簇思想逐个交给剩余的阶段进行实际生成。我们首先讨论后者的转换过程,以突出它与理解的关系。
将一小组内部表示的思想转化为书面或口头文本的过程,在明显意义上是理解过程的逆过程,正如我们在前面的 2-5 节中所概述的那样。换句话说,从要传达的一些内部表示的思想开始,我们需要按照有序的线性排列这些思想,形成一个以表面为导向的逻辑形式,该形式简洁、不重复且适当地使用指示性词(例如,使用 I、you、here、now 和指代表达式),最后将其实际表现和物理呈现为口头或书面文本。在理解中涉及的大部分或全部知识在生成中也会发挥作用,无论这些知识是关于词和短语结构的,还是关于结构和意义表示之间的关系的,或者是关于表达思想的常规(或创造性)方式的,或者是关于话语结构和关系的,或者是关于世界的。
尽管存在这种逆向关系,但与语言理解相比,语言生成在计算语言学家中传统上受到的关注较少,因为如果要转化为语言的内容在一个明确的、形式化的表示中是可用的,标准的输出模板通常可以用于生成,至少在足够狭窄的领域中是如此。即使对于无限制的领域,从明确的、无歧义的内部语义表示到词序列的转换也比从模糊的词序列中重建明确的语义表示要容易得多。在语音识别和生成的层面上也存在类似的不对称性,这解释了为什么可用的语音生成器(例如盲人阅读机)比可用的语音识别器(大约在 1999 年左右出现)出现得早得多。
从一些内部思想到表面导向的指示性表示的微观规划过程通常从识别“块”开始,这些块预计将被表达为特定类型的句法成分,例如名词短语(NPs)、动词短语(VPs)或介词短语(PPs)。接下来通常会选择更加表面导向的概念(或直接选择词汇头),用于表达这些块。这些过程的性质在很大程度上取决于内部表示。例如,如果表示以非常抽象的原语、主题关系和实体的属性-值描述为基础,那么这些块可能是围绕一个动作的主题关系集合,以及要引用的实体的显著属性集合。如果内部表示更类似于语言,那么块将相对较小,通常是单个命题,词汇选择过程将类似于逻辑形式的内部释义。如果有多个思想正在被表达,就需要做出排序决策。例如,报告一个持枪的强盗进入了一家当地的酒店,可以按照这个顺序报告,或者作为“一个强盗进入了一家当地的酒店,持枪”。在对话中,如果一个贡献既涉及提供信息又涉及请求信息,请求应该放在最后。在其他情况下,可能需要进行转换,以使所代表的思想在风格上更接近表面形式。例如,从表示约翰吃了一个含有鸡肉的墨西哥卷饼和玛丽吃了一个含有鸡肉的墨西哥卷饼的逻辑形式中,可以生成一个更紧凑的表面导向逻辑形式,即约翰和玛丽各自吃了一个鸡肉卷饼。还可以做出更微妙的风格选择,例如,在非正式的话语中,吃可能被描述为“吃光”(假设内部表示允许这种表面导向的区别)。 此外,正如已经提到的,表面导向的逻辑形式需要引入上下文适当的指称表达,如确定描述和代词,以符合对这些表达使用的语用约束。
上述概述简化了话语和语境的某些微妙之处。一个句子或其他话语类型通常涉及新信息和旧信息(已知、预设),而且,所涉及的一些概念可能比其他概念更加强调。例如,在句子“你订购的物品价格是九十美元,而不是九美元”中,物品的存在和身份,以及它被订购的事实,被假定为当前语境中的共同基础(旧信息),而收信人相信物品的价格是 90 美元是新信息。对九十的强调引起了对被纠正的假设信念的关注。因此,在微观规划阶段,不仅需要提供概念内容,还需要指示什么是新信息和旧信息,以及哪些方面需要强调或聚焦。规划者至少需要应用关于新信息和旧信息的短语化的知识(例如,不定冠词与定冠词的使用),关于所使用项目的词汇预设和蕴涵的知识(例如,后继预设尝试,后悔 φ 预设 φ,或者一些蕴涵不是全部),关于重音模式的预设,以及关于聚焦装置(如重音和置前)的知识。应用这些类型的语用知识的效果将是适当配置表面导向的逻辑形式,这些逻辑形式将被传递给表面实现器,或者对于无法合并到逻辑形式中的语用特征,用这些特征对逻辑形式进行注释(例如,重音标记)。
倒数第二步是表层实现,利用关于句法-语义界面的知识。在针对受限领域的系统中,这种知识可能包括启发式规则和模板(可能是树模式),用于将逻辑形式转化为表层形式。更广泛的生成器可能会使用可逆的语法,以规则对规则的方式进行表达,并允许从逻辑形式到表层形式的转换,就像从表层短语结构到逻辑形式的“正向”转换一样。复杂的生成器还需要考虑语用注释,如上面提到的重音。最后,语言表达的内容需要以口头或书面文本的形式呈现出来,要注意发音、重音和语调,或者对于书面文本来说,要注意标点符号、大写、选择不定冠词 a 或 an、斜体、换行等等。
现在回到内容规划,这个过程可能是扩展的,也可能非常有限;例如,它可能旨在提供复杂对象、事件集或论证的细节,或者只是提供一个事实、问候或确认。我们将对强交互类型的内容规划的讨论留给下一节,而在这里我们将评论更为广泛的文本生成。在这种情况下,要呈现的信息的组织是核心关注点。例如,叙述的事件或步骤通常按照时间顺序排列;为了支持该步骤的假设,论证可能会按照任何预期的子论证(立即)在其前面排列;对于对象的描述可能会从主要特征和部分到细节进行。
早期的一种产生组织良好、段落长度的描述和比较的方法是由 McKeown(1985)的 TEXT 系统开创的,该系统使用类似 ATN 的组织模式来对对象类型的描述进行分段排序,例如对象的更一般类型、主要部分和独特属性以及说明性示例。后来,Hovy(1988)和 Moore 和 Paris(1988)的工作更加紧密地将内容规划与交际目标联系起来,依赖于修辞结构理论(RST)(Mann 和 Thompson 1987)。RST 提出了 20 多种可能的文本连贯关系(通常是相邻的)。例如,某种主张的陈述可能后面跟着对该主张的假设证据,从而在主张(称为核心,因为它是主要观点)和引用的证据之间建立了一个证据关系(称为卫星,因为它是辅助角色)。另一个例子是意愿结果关系,其中核心文本跨度描述了一个感兴趣的情况或事件,而卫星描述了导致该情况或事件的故意行动。通常,这些关系由话语标记(提示词和短语)来表示,例如但是、当、然而或毕竟,对于文本生成来说,适当使用这些标记非常重要。例如,以下句子中使用的 when 增强了连贯性,
(6.1)
约翰在电话要求他的社会安全号码时挂断了电话,
通过发出可能的意愿结果关系的信号。由修辞关系链接的文本跨度可以由单个或多个句子组成,可能导致递归(尽管不一定严格嵌套)的结构。修辞关系可以服务于沟通目标,如概念理解(例如,通过对定义的阐述)、信念(通过提供证据)或因果理解(例如,通过意愿结果关系,如(6.1)中所示),从而加强内容规划和沟通目标之间的联系。
7. 理解和参与对话
“我们可以询问修辞学如何以某种方式感动我们...亚里士多德将修辞学的本质定位在所追求的目标上,而不是纯粹的形式属性。” -丹尼尔·N·罗宾逊,《意识与心理生活》,(2007: 171–2)
对话是一种互动的目标导向(有目的)行为,在这个意义上是最自然的语言形式。与叙述性或描述性语言相比,表面话语的流动和说话人的交替更能反映潜在说话人目标和意图的相互作用。然而,单独看来,对话中的话语在目的上是模糊的,需要理解话语背景和话语领域才能制定或理解它们。例如,
(7.1)
你知道今天是什么日子吗?
可以理解为请求回答,比如“6 月 24 日,星期四”,也可以理解为提醒这一天的重要性,或者作为对被称呼者心理警觉性的测试。
这样一种话语的直接目标是改变听者(尤其是信念、欲望和意图)的心理状态,言语行为理论涉及特定类型的言语行为如何直接或间接地实现这种改变(奥斯汀 1962 年;格赖斯 1968 年;西尔 1969 年)。为了明智地选择言语行为,每个参与者还需要考虑其他人的心理状态;特别是,每个人都需要认识到对方的信念、欲望和意图。合作对话中的话语约定被调整以促进这个过程:发言者使用表达其预期效果的措辞,他们的确认和轮流发言巩固了相互理解。通过这种方式,实现了混合主动对话和潜在的合作领域行动。
在前面关于语言生成中内容规划的讨论中,我们很少提到在这个过程中如何形成交际意图。但在目的对话的背景下,考虑对话代理人如何产生传达某些想法的意图是至关重要的,比如情节性、指导性或描述性信息,请求,对请求的确认和接受,对问题的回答,支持结论的论证等。
正如在生成扩展描述、叙述、论证等方面使用 RST 一样,这里的自然视角是以目标导向的规划为中心。事实上,将这种视角应用于对话的历史先于将其应用于扩展篇章。特别是,科恩和佩罗(1979 年)提出了一种推理、规划和计划识别框架,将言语行为表示为其前提和效果。例如,一个简单的 INFORM 言语行为可能具有以下前提(从第一人称发言者的角度理解):
听者(我的对话伙伴)不知道某个命题 X 是否为真;
听者希望我告诉他 X 是否为真;和
我确实知道 X 是否为真。
实施 INFORM 作为话语的效果是听者知道 X 是否为真。这种框架的一个重要特点是它可以解释间接言语行为(Allen 和 Perreault 1980)。例如,问题(7.1)作为对日期或星期几的间接请求,可以被视为表明说话者意识到只有在满足该行为的知识前提条件时,听者才能执行所请求的信息传达行为。此外,由于听者意识到质疑潜在行为的前提条件是请求该行为的一种间接方式,所以(除非上下文提供相反的证据),听者会推断说话者希望听者执行信息传达言语行为。请注意,推理和规划框架必须允许迭代的模态,例如“我相信你想让我告诉你今天的日期”,或者“我相信(因为我刚刚提出的请求)你知道我想让你把盐瓶递给我”。重要的是,还必须允许相互的信念和意图,以便可以维持共同基础作为上下文的一部分,并进行协作。如果每个参与者都持有信念,并且参与者相互相信彼此持有该信念,则信念是相互的。对话参与者的相互知识可以假定包括他们话语的明显内容和共同的一般知识,包括对话约定的知识。
由于对话的最终目的可能是在世界上实现某些事情,而不仅仅是在参与者的思想中,因此推理、目标导向的规划和行动也需要在领域层面上发生。言语行为的目标不仅仅是自身的目的,而是领域中其他目标的手段,也许可以通过物理行动(如设备维修)来实现。因此,面向任务的对话往往以与领域实体的结构和有目的的行动方式相一致或“回应”方式来构建。这些考虑导致了 Grosz 和 Sidner 在面向任务的对话中提出的对话结构理论(Grosz 和 Sidner 1986)。他们的理论围绕着通过推送和弹出堆栈上的“焦点空间”来实现注意力转移的思想。焦点空间中包含了对领域行动的结构化表示。例如,设定一个协作目标,将某个零件连接到某个设备上,将会将相应的焦点空间推送到堆栈上。根据对物理任务的了解,参与者可能会接下来口头承诺使用螺丝刀和螺丝来实现目标的步骤,这部分对话将通过将相应的子空间推送到焦点堆栈上来进行。当子任务完成时,相应的焦点空间将从堆栈中弹出。
实现涵盖基于计划的对话行为所需的迭代模态和任务领域的现实的推理和规划框架已被证明在受限领域的受限对话中是可行的(例如,Smith 等人,1995 年),但是当语言的覆盖范围和话语领域的范围扩大时,很快就会遇到复杂性障碍。规划通常是 NP 难的,甚至在命题规划形式中也是 PSPACE 完全的(Bylander,1994 年),即使所有可用于实现目标的计划都事先已知,计划识别也可能是指数级的(Geib,2004 年)。
针对这一困难,致力于构建可用系统的研究人员尝试了各种策略。其中一种策略是预先为对话系统配备一套适用于要处理的对话类型(如辅导、修复、旅行计划或日程维护)的精心设计的计划层次结构,并选择在 NLU/NLG 中使用的逻辑词汇,以使其与规划操作符和针对目标领域的表面实现模式相协调(作为这一流派的一个值得注意的例子,参见 Moore 和 Paris,1993 年)。通过这种方式,领域和文本规划以及表面实现变得相对简单,至少与试图从头开始合成计划或对世界、对话者、上下文以及在表面层面上表达一个想法的最佳方式进行广泛推理的系统相比。但是,尽管这种方法对于旨在说明计划和意图在专门领域中的作用的实验系统来说是完全可辩护的,但它仍然存在一个问题,即如何将大量的语言知识和世界知识纳入对话系统,并在规划交流(和其他)行为中进行推理使用。
实现更接近实际表现的另一种策略是预编码(在某种程度上学习)更多“反应性”(相对于思考性)的对话参与方式。反应性技术包括:(i)基于公式和模式的响应(类似于 ELIZA),在这种情况下,这些响应可能是合适的;(ii)基于规则的意图和计划识别;例如,自动旅行代理面对“奥兰多的航班”这样的省略输入时,通常可以假设用户希望得到从用户当前所在城市到奥兰多的航班选择,时间范围可能是之前确定的;(iii)基于概率建模的统计领域计划识别,该模型对追求领域特征目标的典型步骤序列进行建模;以及(iv)通过将言语行为(或话语行为)和对话状态分类为相对较少的类型,并将对话状态之间的转换视为由当前状态和当前言语行为类型确定的事件来进行话语状态建模。例如,在对话系统没有即时义务的状态下,当用户提问时,系统会承担回答问题的义务,并转换到一个尝试履行该义务的状态。
然而,主要依赖反应性技术的系统往往缺乏深入的理解和行为灵活性。基本上,基于知识的推理和规划被机械行为所取代,这些机械行为受当前话语状态和世界观察的各种特征所制约。此外,深思熟虑的推理和计划合成似乎对于能够自主获取有效目标导向计划和行为的代理人是必要的。尽管随机试错(如强化学习)、监督学习和模仿学习是其他学习选择,但它们的潜力有限。随机试错在语言和常识行为的巨大状态空间中往往不切实际;监督学习(基于上下文特征的适当选择)最多只能诱导机械计划识别和话语状态转换(上述类型(iii)和(iv)的反应性行为);而模仿只有在相关的、容易观察到的示范行为可以呈现给学习者时才可能,并且仅靠模仿本身只能导致机械而非理性的行为。
将反应性方法与深思熟虑的推理和规划相结合,可以通过将由反应性方法得出的意图和行动视为暂定的,如果时间允许,通过更深思熟虑的推理进行验证和可能的修改。通过对达成共同信念的假设加强,也可以避免过度使用迭代模态的推理。例如,我们可以假设说话者和听话者都会根据话语事件和共同知识自发地对世界和彼此的心理状态进行前向推理,并且这种前向推理直接成为共同知识(基于“思维方式相似”的假设),从而简化了许多模态嵌套推理。
8. 为语言获取知识
我们已经注意到语言理解和使用对于广泛的浅层和深层知识的依赖,包括关于世界的知识、词汇和短语的意义,以及关于话语和对话结构和惯例的知识。如果机器要具备语言能力,我们需要将这些知识传授给它们。
理想情况下,机器的初始预编程知识应该限制在被认为是先天的人类知识类型上(例如,物体持久性、运动连续性、动物性和心智的基本模型、语言普遍性、对世界进行分类/分类的方法、对时间进行事件组织的方法、从经验中抽象出来的方法,以及其他类似的知识和技能)。其余的知识应该以类似人类的方式进行学习。不幸的是,我们没有具备类似人类感官和运动设备或类似人类先天心智能力的具体化代理人;因此,除了像机器人进行简单的语言学习,例如对物体或行为进行语言标记,或使用空间介词或两个词的句子(例如,Fleischman 和 Roy 2005;McClain 和 Levinson 2007;Cour 等人 2008 年)之外,目前大部分关于知识获取的工作要么使用(1)手工编码,要么使用(2)从文本语料库中提取知识,要么使用(3)众包加上某种将收集到的口头表达的“事实”转换为可用格式的方法。本节重点讨论获取支持语言理解和产生所需的一般背景知识,将语言知识获取的讨论留到第 9 节。
8.1 手动知识编码
最著名的人工创建的常识知识体系是 Cyc 或 ResearchCyc 知识库(Lenat 1995)。它包含了几十万个概念和数百万个事实和规则的本体论,支持推理引擎。它已经应用于商业、教育和军事领域的分析、决策支持和其他类型的项目。然而,Cyc 本体论和知识库内容主要是出于知识工程的考虑(通常是为了特定项目),而不是为了应用于语言理解,这在其对非常具体的谓词的严重依赖上得到了体现,这些谓词由英语单词的连接组成,并且依赖于高阶运算符。例如,杀戮和死亡之间的关系使用谓词 lastSubEvents、KillingByOrganism-Unique 和 Dying 来表示,并依赖于一个可以展开为量化条件语句的高阶关系 relationAllExists。这种与语言的疏远使得将 Cyc 知识库应用于语言理解变得困难,特别是如果目标是从该知识库中提取相关概念和公理,并将它们与以更具语言导向的表示形式形式化的概念和公理集成在一起(而不是采用 CycL 语言、Cyc 知识库、关于英语的公理和推理机制的整体)(例如,Conesa 等人 2010 年)。
其他手工编码知识库的示例包括组件库(CLib)(Barker 等,2001 年)以及 Hobbs 和 Gordon(2005 年)的常识心理公理集合。 CLib 提供了几百个概念的广泛上位(即高级)本体论,以及关于基本动作(传达,进入,破坏等)和结果变化的公理。然而,CLib 中使用的基于框架的 Kleo 知识表示与语言不接近,英语词汇表的覆盖范围有限。 Hobbs 和 Gordon 的心理公理在自然上是狭窄的(记忆,信念,计划和目标),尚不清楚它们是否可以与语言派生的逻辑形式(Hobbs 偏爱的“平坦”类型)有效地结合使用,以进行话语环境中的推理。
从半正式化的来源进行知识适应,例如,可以提取词性和子范畴信息,以及适当字典中的固定短语和习语。它还可能涉及将超义词层次结构,部分词(部分)或反义词,如 WordNet 中所记录的,映射为可用于消歧和推理的某种形式。手工编码的词汇知识的主要局限性在于其基于语言直觉而没有直接考虑其在语言理解中的作用,以及其不可避免的不完整性,鉴于所有活语言中词汇,行话和表达风格的不断扩大和变化。
除了这些词汇知识的来源外,还有半正式形式的世界知识的来源,例如各种类型的表格和地名词典,以及在线知识资源(例如维基百科)中的“信息框”(例如,著名人物的条目包含有关出生日期、死亡日期、居住地、国籍、种族、事业领域、奖项等摘要属性的框)。但是,只有对于命名实体(例如人物、组织、地点和电影)和少数实体类型(例如生物物种和化学化合物),这些来源才能以有条理且易于获取的形式提供知识。此外,关于普通概念(例如树木或驾驶汽车的概念)的大部分知识不容易以属性-值对的形式捕捉,并且通常不以那种形式提供。
8.2 从文本中提取知识
近年来,从无约束文本中提取知识被称为通过阅读学习。提取方法可以是直接的或间接的。直接方法从一些可靠来源(例如 WordNet 中的词义注释或百科全书中的描述性和叙述性文本)中获取句子信息,并将此信息映射到用于表达通用知识的(更)形式化的语法中。间接方法从杂志报告、故事、论文、博客等中找到的语言模式中抽象出(或多或少)形式化的通用知识。
通过直接方法可靠地提取知识需要相对深入的语言理解,因此远未成熟。Ide 和 Véronis(1994)对从词典定义中获取知识的早期工作进行了调查,并指出了该企业面临的困难。迄今为止,以这种方式获得的知识在数量或质量上大多较低(从推理角度来看)。最近一些有希望的工作包括 Moldovan 和 Rus(2001)的工作,旨在解释 WordNet 中名词概念的注释,以及 Allen 等人(2013)的工作,旨在通过解释它们的 WordNet 注释来形成与动词相关的小群集的逻辑理论(例如,睡觉,醒来等)。
在过去的二十年中,从文本中提取知识的最活跃研究方法是间接方法,始于 Marti Hearst 的一篇论文,该论文证明了通过使用词汇句法提取模式(Hearst 1992)可以相当简单和有效地发现下义关系。例如,寻找由“例如”或“和其他”分隔的名词短语的提取模式将匹配诸如“像企鹅和信天翁这样的海鸟”或“豆类、坚果和其他豆科植物”之类的词序列,从而得出海鸟是企鹅和信天翁的上义词,豆类和坚果是豆科植物的下义词的假设。通过寻找已知的下义词-上义词对的紧密关联,Hearst 能够扩展初始的提取模式集合和假设集合。此后,已经开发了许多变体,其中包括引入机器学习技术来自动化引导和模式发现方法,并应用于选择、加权和组合与感兴趣的关系对象紧密相关的局部特征。除了下义关系之外,还针对与语言理解相关的部分关系、因果关系和目的关系(例如使用牛奶是为了饮用)等其他关系。
虽然使用类似 Hearst 模式的知识提取仅针对特定预定类型的知识,但其他方法则针对开放信息提取(OIE)。这些方法旨在发现广泛的关系知识,有时包括不同关系之间的蕴涵(在相当宽松的意义上)。这一类型的早期且相当成功的系统是 Lin 和 Pantel 的 DIRT 系统(从文本中发现推理规则),该系统使用词汇统计数据构建了一个“推理规则”数据库(Lin 和 Pantel 2001)。一个规则的例子可能是“X 找到了 Y 的解 ≈X 解决了 Y”。所使用的统计技术包括将名词聚类成相似组,基于它们在相同动词的相同论元位置中出现的倾向,并找到类似的关系短语(例如“找到了 Y 的解”和“解决了 Y”),基于它们连接相同或相似的名词对的倾向。许多规则后来通过对变量添加类型约束进行了进一步改进,这些约束通过从 WordNet 中抽象出特定名词来获得(Pantel 等人,2007 年)。
一种旨在实现最大速度的 OIE 方法的例子是 TextRunner 系统(Banko 等,2007)。TextRunner 基于提取模式,但不是使用针对少数选定关系的模式,而是使用从句法分析的训练语料库中自动获取的一系列模式,通过贝叶斯机器学习方法进行加权,逐句从文本中提取各种关系。另一种不同的方法是称为“开放知识提取”(OKE),它从解析的句子中推导出逻辑形式,并简化和抽象这些形式,以反映世界的一般属性。这可以通过 Knext 系统(KNowledge EXtraction from Text)来说明(例如,Schubert 和 Tong,2003)。例如,句子“I read a very informative book about China”允许 KNEXT 将“事实”抽象为一个人偶尔会读一本书,书籍偶尔会有信息量,偶尔会是关于一个国家的。(请注意,对说话者和中国的具体引用已被抽象为类别。)另一个有趣的发展是通过搭配方法从大型语料库中提取类似脚本的关系序列(参见 Chambers 和 Jurafsky,2009)。例如,关于犯罪分子被逮捕和起诉的大量新闻报道可以被挖掘出涉及的典型事件类型,按照时间顺序,如逮捕、提审、辩护、审判等。所有这些工作的一个困难是,大部分获得的知识都表达得太模糊和不完整,无法提供推理链的基础(但参见 Van Durme 等,2009;Gordon 和 Schubert,2010;Schoenmackers 等,2010)。
8.3 众包
众包方法用于获取一般知识,包括从大量网络用户那里征求口头表达的信息或对这些信息的注释,有时使用小额财务奖励或参与简单游戏的挑战作为诱因(Havasi 等人,2007 年; von Ahn,2006 年)。众包在简单的注释/分类任务中被证明非常可靠(例如,Snow 等人,2008 年; Hoffmann 等人,2009 年)。然而,非专家用户提供的一般知识通常比百科全书条目或词义词汇中的词义注释更不仔细,如果要抽象出正式陈述,仍然需要自然语言处理。尽管如此,Open Mind Common Sense 项目已经产生了一个基于全球贡献者的简单英语陈述的非正式常识知识关系网络(ConceptNet),该网络对于改进语音识别和其他领域的解释非常有用(Lieberman 等人,2004 年; Faaborg 等人,2005 年)。
总体上看,大规模的语言知识资源,无论是词汇还是关于世界的知识,仍然过于稀缺和不精确,无法使狭领域的自然语言理解(NLU)和对话系统扩展到广泛的理解。但是,这种知识最终预计在一般语言理解中将变得至关重要,因此获取这种一般知识的探索仍然非常活跃。
9. 统计自然语言处理
“你已经听过成千上万次的句末助动词未缩写,这加强了它们不允许缩写的可能性。” –Geoff Pullum (2011)
我们已经提到了在各种计算任务中使用的各种统计模型和技术,例如(在第 2 节中)在词性标注中使用的 HMM,概率语法建模和解析,统计语义学,语义消歧(词义,量词范围等),计划识别,语篇建模和从文本中提取知识。在这里,我们试图提供一种简要但稍微更系统的任务类型分类法,以及最常用且使统计自然语言处理在最近几年中如此占主导地位的建模技术和算法的一些感觉,这挑战了计算语言学的传统观点。
这种传统观点侧重于推导意义,并基于这样一个假设,即在这个推导中使用的句法,语义,语用和世界知识是“清晰的”,而不是概率的;即语言的分布特性只是语言交流的副产品,而不是语言理解,使用甚至学习的重要因素。因此,在这种观点中,重点是制定非概率的句法,语义,语用和知识表示理论,以在语言理解和使用中部署。当然,歧义问题一直是构建解析器和语言理解系统的一个核心问题,但普遍的假设是,通过补充解释性例程与一些精心制定的表达句法和语义偏好的启发式方法,可以解决歧义问题。
然而,经验表明,困扰所需映射的模糊性太多、微妙且相互关联,无法通过启发式仲裁来解决。相反,语言现象需要被有效地视为随机的,并且需要系统地利用这些随机过程产生的分布特性,以得出关于潜在结构的合理可靠的假设。(上面的 Geoff Pullum 的引用与此观点相关:在“I'd rather be hated for who I am, than loved for who I am not”中,将 I am 的第一次出现缩写为 I'm 是不可接受的,这不容易归因于任何语法原则,然而——仅基于积极证据——它成为我们对英语用法的知识的一部分。)因此,至少暂时,重点已经转移到将 NLP 视为一个不确定推理和学习问题的随机环境中。
从哲学的角度来看,这种转变是重要的,不仅仅是实践上的:它表明传统的语言思维可能过于依赖内省。内省的局限性在于,当我们理解或思考语言时,我们大脑中发生的事情很少能够被意识所感知(例如,参见 Baars 1997 中关于“双通道实验”的讨论)。我们有意识地记录我们理解和思考的结果,显然以符号形式,但并不记录理解和思考的过程本身;而这些符号抽象,如果缺乏定量或概率维度,可能会使我们认为底层处理也是非定量的。但是,统计 NLP 的成功以及认知科学的最新发展(例如 Fine et al. 2013;Tenenbaum et al. 2011;Chater and Oaksford 2008)表明,语言和思维不仅仅是符号化的,而且是深度定量的,特别是概率性的。
在最初的二十年左右,统计自然语言处理的主要目标是使用在大规模语料库上训练的统计语言模型,为语言输入分配标签、标签序列、句法树或翻译。更具体地说,所处理的任务类型可以大致分为以下几类(附加的关键词表示典型应用):
文本/文档分类:作者身份、路透社新闻类别、情感分析;
在句子或更广泛的上下文中对选定的单词或短语进行分类:词义消歧、命名实体识别、多词表达式识别;
序列标注:声学特征 → 电话 → 音素 → 单词 → 词性标记;
句子结构分配:解析、语义角色标注、量词作用域;
句子转换:机器翻译、逻辑形式计算;
对多句文本进行结构分配:话语关系、指代、计划识别;
大规模关系抽取:知识提取、释义和蕴涵关系。
这些群体看起来可能是随意的,但正如我们将进一步讨论的那样,其中许多群体都有共同的技术和区别,特别是
在建模中:数值和离散特征,向量模型,对数线性模型,马尔可夫模型;生成模型与判别模型,参数化与非参数化模型;
在从数据中学习中:最大似然估计,最大熵,期望最大化,动态规划;有监督学习与无监督学习;
在输出计算中:动态规划;唯一输出与输出分布。
我们现在试图对上述七组任务中涉及的最重要的技术和区别提供一些直观的洞察。为此,我们不需要进一步评论量词作用域(第四组)或第六和第七组中的任何项目,因为这些大部分在本文的其他地方已经涵盖了。在所有情况下,两个主要要求是开发(通过学习辅助)将语言输入与期望输出相关联的概率模型,并在对以前未见过的输入进行标记或结构分配时使用该模型的算法。
文本和文档分类:在对实质性文档进行分类时,所使用的特征可能是特定词语(或词类)和标点符号的归一化出现频率。特别是对于较短的文本,还可以包括各种离散特征,例如表示某些关键词或结构特征的存在或缺失的 0、1 值函数。通过这种方式,文档被表示为数值向量,其值位于高维空间中,不同类别在该空间中可能形成相对独立的聚类。对于学习将新文档(作为向量)分配到适当类别的问题,可以应用各种经典的模式识别技术(例如 Sebestyen 1962;Duda 和 Hart 1973)。也许最简单的方法(在特征为二进制时最容易应用)是朴素贝叶斯方法,它假设每个类别生成的特征值彼此独立。生成频率是从训练数据中估计得到的,对于未知文档(向量),通过贝叶斯规则计算类别成员概率(可以使用先验类别概率的连续更新来完成)。然后选择具有最高后验概率的类别作为决策准则。对于实值特征的常见生成模型,允许特征之间的相互作用,将给定类别的已知成员视为多元正态(高斯)随机变量的样本。在这种情况下,学习包括估计每个类别的均值和协方差矩阵(最大似然估计的一个示例)。
一种传统的区分方法,不依赖于任何生成模型,涉及计算将已知类实例的聚类分割开的超平面(优化涉及类内和类间方差的某些度量);新实例被分配到其所属分割的类中。感知器提供了一种相关的技术,因为它们基于特征值的线性组合来决定类成员资格;它们的特殊优点在于它们可以逐步学习(通过调整特征权重),随着越来越多的训练数据变得可用。另一种持久的区分方法——不依赖于类的线性可分性——是 k 最近邻(kNN)方法,它将未知的文本或文档分配给在向量空间中其 k(例如,1-5)个最近邻中最普遍的类。虽然之前提到的所有方法都依赖于参数估计(例如,生成概率、高斯参数或分离平面的系数),kNN 不使用这些参数——它是非参数的;然而,找到一个合适的接近度或相似度度量可能是具有挑战性的,并且由于特征空间中随机局部数据点配置而导致的错误很难避免。值得一提的另一种非参数区分方法是使用决策树,可以使用信息论技术进行学习;它们通过遵循从根到叶的路径,并通过对给定输入向量的特征进行测试来选择分支,从而选择类别。一个潜在有用的特性是学习到的决策树可以提供哪些最重要的特征(这种洞察力也可以由降维方法提供)。 然而,决策树往往会收敛到非全局最优解(全局优化是 NP 难问题),并且通过分割数据,往往会阻碍特征交互的建模;通过使用决策森林,可以在一定程度上缓解这个缺陷。
在提到一些传统的分类方法之后,我们现在概述两种自 1990 年代以来在统计自然语言处理中变得特别突出的技术。第一种是最大熵(MaxEnt),它具有从 1950 年代开始的数学基础,也被称为(多项式)逻辑回归(例如,Ratnaparkhi 1997)。在这种情况下,特征是给定的语言输入和可能的类别的任何所需的 0、1 值(二进制)函数。(对于连续特征,可以应用有监督或无监督的离散化方法,例如基于熵的分区成一定数量的区间。)训练数据提供了这些特征的出现频率,并且可以得到一个分布,用于给定语言输入的条件概率的类别。(因此,它是一种判别方法。)正如其名称所示,这个条件概率函数是一个最大熵分布,受限于符合训练数据中观察到的二进制特征频率的约束。它的形式(除了一个常数乘子)是一个指数,其指数是给定输入和给定类别的二进制特征值的线性组合。因此,它是一个对数线性模型(其对数在特征上是线性的)——这是现在在许多统计自然语言处理任务中普遍存在的一种模型类型。请注意,由于其对数是给定输入和给定类别的二进制特征值的线性组合,为给定输入选择最大概率类别相当于线性决策,就像一些经典方法中的情况一样;然而,最大熵通常提供更好的分类性能,并且它提供的分类概率在进一步的计算(例如,期望效用)中是有用的。
在统计自然语言处理的出现和成功中,另一种重要方法是支持向量机(SVM)方法(Boser 等,1992; Cortes 和 Vapnik,1995)。这种方法的巨大优势在于,它原则上可以区分任意配置的类别,通过将原始向量隐式投影到一个更高(或无限)维空间中,在这个空间中,类别是线性可分的。投影是通过核函数来实现的,核函数是一种用于对向量对进行相似度度量的指标,例如两个向量的点积的多项式。粗略地说,高维向量的分量对应于核函数的项,如果将其展开为原始未展开的向量对特征的乘积之和。但实际上并不进行任何展开,而且从给定的训练语料库中得到的分类准则只需要计算给定特征向量(表示待分类的文档)与某些特殊的“支持向量”配对的核函数,并将结果值的线性组合与阈值进行比较。支持向量属于训练语料库,并定义了两个平行的超平面,尽可能地将所讨论的类别(在扩展空间中)分开。(因此,这是一种“最大间隔”判别方法。)SVM 通常提供出色的准确性,部分原因是它们允许在原始空间中进行非线性特征交互,部分原因是最大间隔方法侧重于类别分离,而不是对类别的条件概率建模。另一方面,最大熵分类器比 SVM 更容易训练,并且通常提供令人满意的准确性。我们概述的分类方法的一般参考文献有(Duda 等,2001; Bishop,2006)。
在句子或更广泛的上下文中对所选词语或短语进行分类:正如前面所提到的,例子包括词义消歧(WSD)、命名实体识别和句子边界检测。与文本/文档分类的唯一区别在于,它不是将整个文本块作为一个整体进行分类,而是将一个词语或短语与这样一个文本块的上下文相关联。因此,选择的特征既反映了目标词语或短语的特征(如形态),又反映了它与上下文的关系,例如周围的词语或词类、(可能的)局部句法依赖关系,以及具有更广泛范围的特征,如词频或文档类别。除了特征选择的差异之外,上述相同的(监督式)学习和分类方法也可以应用。然而,构建足够大的训练语料库可能很困难。例如,在统计词义消歧中(例如 Yarowsky 1992;Chen 等,2009),由于成千上万的词语在 WordNet 等来源中具有多个意义,很难构建一个包含足够多这些意义的词义标注训练语料库以进行统计学习。因此,注释通常仅限于几个多义词的意义,统计词义消歧已被证明对于所选词语是可行的,但广覆盖的词义消歧工具仍然难以实现。
序列标注:在前面的任务和序列标注之间存在一条相对任意的界线。例如,可以将词性标注视为将文本中的单词根据其上下文进行分类的任务。然而,这种方法未能充分利用相邻单词的分类是相互依赖的事实。例如,在句子(来自网络)“我不像大多数人那样钓鱼”中,don't 的出现应该有利于将 fish 分类为动词,进而有利于将 like 分类为介词。(至少对于陈述句而言,将“我”替换为“为什么”会改变情况——见下文。)这种级联影响不容易通过连续的独立分类来捕捉,因此激发了生成式序列模型(如 HMMs)。对于词性标注,标记化的训练语料库可以提供给定当前单词的词性的下一个单词的概率估计。如果语料库足够大,还可以提供给定词性标签的文本中通常出现的大部分单词的“发射”概率估计,即它们出现的概率。 (使用平滑技术填充未知单词的非零概率,给定一个词性标签。)我们之前提到过维特比算法作为一种高效的动态规划算法,用于将经过训练的 HMM 应用于将最大概率的词性标签序列分配给文本中的单词的任务。两个相关的算法,前向算法和后向算法,可以用于推导出每个单词位置 i 可能标签的概率,这可能比“最佳”标签序列对于后续的高级处理更有用。前向算法实际上(通过动态规划)对到达位置 i 并以指定标签 X 结束的所有标签序列的概率进行求和,并生成到(包括)该单词的输入。 反向算法对以标签 X 在位置 i 开始的所有标签序列的概率进行求和,并生成从位置 i+1 到末尾的输入。前向和后向概率的乘积经过归一化,使得位置 i 处备选标签的概率之和为 1,给出了在整个输入条件下标签 X 在位置 i 的概率。
到目前为止,所提到的所有学习方法都是监督学习方法——假设有一个正确标记的文本语料库可用于推断模型参数。但是也已经开发出了无监督(或半监督)学习的方法。一种重要的无监督方法是用于序列标注的 HMM 模型的前向-后向(或 Baum-Welch)算法。在词性标注的情况下,这个算法的一个简单版本依赖于一个包含每个词可能的标签的词典(可以从标准词典中轻松获得)。然后,根据训练语料库,基于一些最初的、或多或少是任意选择的 HMM 转移和发射概率的值进行迭代优化。迭代过程的一个夸张描述是这样的:我们使用当前的 HMM 参数猜测来标记训练语料库;然后,我们重新估计这些参数,就像语料库是手动标记的一样。我们重复这两个步骤直到收敛。实际使用的方法在使用当前的 HMM 参数的方式上更加微妙(它是 EM——期望最大化的特例)。它不是根据当前“最佳”标签序列中的出现频率重新估计参数,而是使用特定连续状态(标签)对的预期出现次数除以该对的第一个成员的预期出现次数。这些预期值由给定训练语料库和当前 HMM 参数的条件概率分布来确定,并且可以使用上述的前向和后向概率(因此,以整个语料库为条件)获得。对于任何 X → w,修订后的发射概率可以计算为在语料库中出现单词 w 的所有位置上 X 标签的概率之和,除以所有位置上 X 标签的概率之和,同样使用(乘积)前向和后向概率。
不幸的是,EM 算法不能保证找到全局最优模型。因此,只有通过使用“合理”的初始 HMM 才能取得良好的结果,例如对某些转换(如决定词→决定词,决定词→动词,形容词→动词)分配非常低的概率。半监督学习可以从相对较小的标记训练语料库开始,并使用相应的 HMM 参数估计作为从进一步的无标签文本进行无监督学习的起点。
HMM 本身的一个弱点是文本中存在长程依赖,违反了马尔可夫假设(给定邻居,非邻居之间的独立性)。例如,在相对子句的上下文中(由在该子句之前的名词标志),及物动词可能缺乏 NP 补语(“我收集了他扔在桌子上的钱。”),结果,动词后面的词可能被错误标记(down 作为名词)。克服这个困难的一种判别方法是使用条件随机场(CRFs)。与 HMM(它们包含)类似,CRFs 允许隐藏状态的局部相互依赖,但使用的特征不仅依赖于这些状态的相邻对,还依赖于整个输入的任何所需属性。从数学上讲,该方法与 MaxEnt 非常相似(如上所述)。特征系数可以通过梯度上升或与 Baum-Welch 算法相关的增量动态规划方法(称为改进的迭代缩放)从训练数据中学习(Della Pietra 等,1997 年; Lafferty 等,2001 年)。CRFs 在除了词性标注之外的许多应用中都取得了成功,例如句子和词边界检测(例如,用于中文),WSD,从文本中提取表格,命名实体识别,以及在自然语言处理之外的基因预测和计算机视觉领域。
句子的结构分配:在第 2 节中简要讨论了概率上下文无关文法(PCFGs)的使用。PCFGs 的有监督学习可以像对词性标注的隐马尔可夫模型(HMMs)进行有监督学习一样实现。如果有一个用短语括号标注(树库)的大型语料库可用,那么短语扩展的所需条件概率可以很容易地估计出来(尽管 POS → word 扩展概率的估计最好补充额外数据)。一旦学习完成,可以使用第 2 节提到的图表解析方法(再次是一种动态规划方法)使用 PCFG 来为句子分配概率加权的短语结构。
此外,使用 EM 方法可以进行无监督学习的 PCFG。这一点非常重要,因为它等同于语法的发现。从理论上讲,我们唯一的假设是存在一些非终结符的最大数量,每个非终结符可以扩展为任意两个非终结符或任意一个词(乔姆斯基范式)。此外,我们还将一些相对随意的初始扩展概率与这些规则关联起来。这些概率通过基于当前 PCFG 模型和语料库条件下的可能扩展发生频率的期望值进行迭代修正。计算这些期望值的类似于前向-后向算法的算法是内外算法。内部概率指定了给定句子的某个正确段落从指定的非终结符符号派生的概率。外部概率指定了除了给定句子的某个段落之外的所有内容都是从起始(句子)符号派生的概率,其中“缺失”的段落仍然需要从指定的非终结符符号生成。内部和外部概率在概念上分别起到了 HMM 学习中的后向概率和前向概率的作用。从概念上讲,它们需要对给定句子的指数级可能的解析树进行求和,但实际上内部概率可以通过 CYK 算法(第 2 节)高效计算,而外部概率也可以通过使用先前计算的内部概率的自顶向下递归“分而治之”算法高效计算。
通过这种方式在学习语法方面取得了一些适度的成功。复杂性很高(与训练语料库的大小以及非终结符的数量成立方),正如已经指出的,EM 算法通常无法找到全局最优模型。因此,在初始语法上施加一些约束非常重要,例如,允许非终结符生成非终结符对或单词,但不能同时生成两者,并且还严格限制允许的非终结符数量。一种偏好小规则集而不设定固定上限的方法是使用 Dirichlet 过程,它为无限数量的规则提供概率分布。(该方法是非参数的,即在建模中不承诺任何固定数量的构建块或参数。)无论使用何种规则约束方法,如果要学习到一个相当好的、有意义的规则集,初始 PCFG 必须经过精心选择。一种方法是从语言学上有动机的语法开始,并使用“符号分裂”(也称为“状态分裂”)来生成在扩展规则和概率上有所不同的非终结符的变体。最近的谱算法提供了一种相对高效且全局最优的替代方法(Cohen 等人,2013),它们可以与符号分裂相结合使用。
与 HMM 类似,PCFG 也是生成模型,并且与它们一样,由于局部选择对更大的上下文缺乏足够的敏感性而受到影响。CRF 可以提供更大的上下文敏感性(例如在 POS 标注和其他类型的序列标注中);尽管它们不直接适用于文本的结构分配,但可以用于学习浅层解析器,该解析器仅将短语类型分配给非递归短语(核心 NP、PP、VP 等)(Sha 和 Pereira,2003)。
在当前的语法学习背景下,我们还应该再次提到连接主义模型。这些模型已经显示出一定的能力,可以从一组训练示例中学习解析,但是通过这种方式实现全面的解析仍然是一个挑战。非符号化神经网络展示出在无监督学习中展示系统性的能力,即展示出从未标注的示例中进行泛化的能力,这也是一个有争议的问题。这需要例如接受或生成动词论元出现在与训练集中不同位置的句子的能力。根据 Brakel 和 Frank(2009)的说法,可以通过简单的循环网络(SRNs)实现系统性。然而,计算演示通常仅限于非常简单的类似英语的人工语言,至少在输入是未标注的词流时如此。
一个可以视为迈向语义解释的步骤的结构分配任务是语义角色标注(Palmer 等,2010)。目标是将诸如施事者、主题、接受者等语义角色分配给与动词(以及可能是其他带补足语的词)相关的核心短语或短语头。虽然这可以作为一个序列标注问题来处理,但实验证据表明,计算解析树并使用由此产生的结构特征进行角色分配(或同时计算解析树和角色)可以提高精度。用于此类工作的经常使用的训练语料库是 PropBank,这是 Penn Treebank 的一个版本,其中标注了“中性”角色 arg0、arg1、arg2 等。
到目前为止,最深入研究的统计句子转换类型是统计机器翻译(SMT)(例如,Koehn 2010; May 2012)。自 20 世纪 80 年代末和 90 年代初以来,它的成功对自然语言处理(NLP)社区来说有些出乎意料,因为自从 Bar-Hillel(1960)的报告和 ALPAC 报告(Pierce 等,1966)以来,对机器翻译前景的评估一直相当悲观,这两份报告都对美国政府在二战后大规模资助机器翻译的结果给予了负面评价。机器翻译被视为一个大规模的工程企业,直到能够与语义和基于知识的推理充分整合之前,它不会产生广泛的影响。统计方法在 20 世纪 70 年代末和 80 年代期间成功应用于语音识别的“噪声信道”模型之后出现,并受到机器学习的新发展和大规模机器可读的语言语料库的日益丰富的推动,其中包括多种语言的平行文本。
最早、也是最简单的翻译方法是基于词的。这是建立在以下这种模型的基础上,即外语句子 f(比如法语)是如何从英语句子 e(我们希望恢复的目标语言是英语)生成的:首先,根据一种简单的英语模型生成 e,例如基于二元频率的模型。然后假设 e 的每个单词以一定的概率生成 f 的每个单词,允许任意的单词顺序混乱(或者以某种方式有偏差)。在学习这样的模型时,可以从手工对齐或统计技术对齐的英法平行语料库中估计可能的对应关系和单词翻译概率。然后,可以使用这样的模型通过贝叶斯推断将给定的法语句子 f 解码为英语句子 e——我们将 e 作为具有最高后验概率的英语句子,给定其法语“编码”为 f。这可以通过动态规划算法实现,并且可以使用一个中间阶段,在该阶段计算出 e 的 n 个最佳选择(对于某个预定的 n),然后使用生成模型忽略的 e 和 f 的特征进行判别性重新排序。
然而,目前主流的 SMT 系统(如 Google Translate 或 Yahoo! Babel Fish)是基于短语而不是基于单词的。这里的“短语”指的是倾向于相邻出现的单词或词组。其思想是将短语映射到短语,例如,将英语词对 "red wine" 翻译为法语短语 "vin rouge"、"du vin rouge" 或 "le vin rouge"。此外,短语翻译方法使用重新排序模型,而不是假设任意的单词顺序混乱。根据重新排序模型,给定的短语可能倾向于与左侧或右侧相邻的短语交换位置,或者与相邻的短语分离。此外,与基于单词的方法直接依赖贝叶斯模型不同,基于短语的方法通常使用对数线性模型,允许引入反映语言模型(如三元频率)、短语翻译模型(如短语翻译频率)和重新排序模型的特征,以及其他杂项特征,如生成的单词数量、使用的短语翻译数量和短语重新排序数量(对于较大的位移,惩罚更大)。
虽然基于短语的统计机器翻译模型取得了相当大的成功,但它们仍然容易产生句法不流畅或语义奇怪的翻译,因此最近的研究大多致力于利用语言结构和意义模式来提高翻译质量。在句法转换方面,有两种主要方法:分层短语翻译和树到字符串(TTS)转换模型。分层短语翻译方法使用同步语法规则,同时扩展两种语言中相应句子的部分推导。这些规则是从对齐语料库中自动归纳得出的,最低的分层层次对应于普通短语翻译中的短语到短语的翻译规则。虽然这种方法非常成功,但它很少能保证结果同步语法中的“短语”在语言学意义上是语义连贯的单元。TTS 模型通过使用在短语括号化文本语料库(树库)上训练的解析器来获得更好的连贯性。将英语句子编码成法语(与我们先前假设的语言对相符)被构想为从解析的英语句子开始,然后通过(学习得到的)规则逐步扩展原始或部分转换的短语和单词模式,直到所有叶子节点都是法语单词。
除了机器翻译之外,另一种重要的句子转换类型是语义解析,即将某个领域的句子映射到可用于问答的逻辑形式。(需要注意的是,前面讨论的语义角色标注也可以看作是迈向语义解析的一步。)在这个相对较新的领域中,有几项研究采用了基于带有逻辑形式标注的训练语料库的监督学习方法(例如,Mooney 2007;Zettlemoyer & Collins 2007),或者可能是基于句法树和逻辑形式的训练(例如,Ge and Mooney 2009)。典型的领域包括地理问答(其中逻辑形式是数据库查询)、Robocup 足球或旅行预订。甚至在受限领域中也已经证明了无监督学习的可行性,例如基于医学摘要的问答(Poon and Domingos 2009)或旅行预订领域(Poon 2013)。在这项工作中使用的思想包括形成名词术语和动词关系的同义词聚类,类似于 Lin 和 Pantel 的 DIRT 系统,为这些概念和关系创建反映它们词源的逻辑名称;以及通过马尔可夫逻辑(Markov logic,马尔可夫网络的推广)学习,根据旅行预订对话语料库的数据(旅行代理人回答所需的数据已知存在于数据库中),用数据库实体、类型和关系注释依赖解析树的节点。这些方法是否可以推广到更广泛的领域和语言形式,还有待观察。最近创建的一个带有“抽象意义表示”(AMR)的通用语料库可能会促进在这个方向上的进展(Banarescu 等,2013)。
在本节中,我们涉及的主题在技术上是复杂的,因此我们的讨论必然是浅显的。统计语言处理的一般参考资料有 Manning 和 Schütze 1999 以及 Jurafsky 和 Martin 2009。此外,统计自然语言处理社区已经为研究人员开发了非常全面的工具包,例如 MALLET(MAchine Learning for LanguagE Toolkit),其中包括对许多技术的简要解释。
在机器中实现类似人类语言学习的前景如何?人们越来越认识到,统计学习必须与对世界的感知和概念建模相结合。最近在基于实体语言学习领域的工作正在朝着这个方向发展。例如,Kim 和 Mooney(2012)描述了使用与基于图形的动作和上下文描述配对的句子来假设 PCFG 规则,以将自然语言指令解析为动作表示,并使用内外算法学习规则概率的方法。然而,他们假设了一个非常受限制的领域,问题仍然是,为了支持无限制的语言学习,感知、概念形成以及语义和情节记忆的建模需要走多远。与机器的世界知识获取一样(参见前一节),建模能力可能需要达到与新生儿相当的水平,允许以符号和形象思维语言对感知和思想进行编码,对实体类型进行分类,识别生命力和意图,组织和抽象空间关系和因果事件链等等。提供这样的能力可能需要在我们对认知架构的理解上取得进展的同时,解决与语言、语义和世界知识的表示和使用有关的问题,这些问题一直是计算语言学的传统关注点。
10. 应用
正如一开始所指出的,计算语言学技术的应用范围从那些最小程度依赖语言结构和意义的应用,如文档检索和聚类,到那些在理解和使用语言方面达到一定水平的应用,如在个人日程安排、航班预订或帮助台等有限领域提供帮助和信息的对话代理和智能辅导系统。接下来,我们列举了一些这些应用。在几种情况下(尤其是机器翻译),我们已经提供了相当详细的信息,但这里的意图是提供一个整体的概览,而不是技术解释。
随着普适计算的出现,系统地对自然语言处理应用进行分类变得越来越困难:基于关键词的文档(或片段)检索和数据库访问已经整合到一些对话代理和许多基于语音的服务中;动画对话代理在辅导系统和游戏中与用户进行交互;聊天机器人技术作为后端被纳入各种有用或有趣的代理中;而具备视觉、行动和语言能力的语言机器人,虽然在结合视觉和行动与语言方面有所不同,但逐渐配备了网络访问、问答能力、教程功能,毫无疑问最终还将具备协作解决问题的能力。因此,下面的小节中的应用类别不是相互独立的,而是在实践中越来越相互交织。
10.1 机器翻译(再次)
最古老的机器翻译系统之一是 SYSTRAN,它是从 1960 年代开始作为基于规则的系统开发的,并且被美国和欧洲政府机构广泛使用,还在 Yahoo! Babel Fish 和(直到 2007 年)Google Translate 中使用。2010 年,它与统计机器翻译技术混合使用。正如前面提到的,Google Translate 目前使用基于短语的机器翻译,其中英语作为大多数语言对的中间语。微软的必应翻译器结合了依赖结构分析和统计机器翻译。其他非常全面的翻译系统包括 Asia Online 和 WorldLingo。也存在许多针对小语言群体的系统,例如用于旁遮普语和印地语之间的翻译(直接机器翻译系统),或者用于几种欧洲语言之间的翻译(例如 OpenLogos,IdiomaX 和 GramTrans)。
翻译仍然容易出错,但其质量通常足以使读者理解源内容的大致意思。在许多情况下可能只需要这样,例如国际网络浏览(这是几十年的机器翻译研究中很少预料到的应用)。此外,设计用于帮助国际旅行者的手持设备上的机器翻译应用程序可以足够准确地用于有限的目的,例如询问方向或紧急帮助,与交通人员互动,或进行购买或预订。当需要高质量的翻译时,可以使用自动方法作为人工翻译的辅助工具,但微妙的问题仍可能占据翻译人员大部分时间。
10.2 文档检索和聚类应用
信息检索长期以来一直是信息科学的核心主题,涵盖了对结构化数据(例如在关系数据库中找到的数据)以及非结构化文本文档的检索(例如,Salton 1989)。这两种类型数据的检索标准并不无关,因为结构化和非结构化数据通常都需要内容导向的检索。例如,虽然员工数据库的用户有时可能希望通过员工的唯一姓名或 ID 检索员工记录,但其他时候他们可能希望检索某个就业类别中的所有员工,可能还有进一步的限制,例如符合某个薪资范围。这是通过使用“倒排文件”来实现的,倒排文件基本上是根据实体的属性和值而不是标识符对实体进行索引。同样,文本文档可以通过某个唯一标签来检索,或者根据其与某个查询或主题标题的相关性来检索。相关性的最简单概念是文档应包含查询的术语(单词或短语)。然而,对于一个文档来说,具有独特性的术语应该给予更高的权重。因此,给定一个特定的查询术语,相关性的标准度量是该术语的 tf-idf(词频-逆文档频率),该度量随着术语在文档中出现的频率增加(例如,对数增长),但在整个文档集中频繁出现时会打折。将查询术语的 tf-idf 相加可以得到一个简单的文档相关性度量。
这种方法的缺点首先是低估了术语的共现,如果每个术语在文档集合中都常见(例如,对于查询“眼的杆和锥”,杆、锥和眼的共现可能很好地描述相关文档,尽管这三个术语在非生理背景中都很常见),其次是相关文档可能只包含很少的查询术语出现次数,但却包含许多语义相关的术语。在与文档聚类相关的一些向量方法中提到的一些方法可以用来减轻这些缺点。我们可以使用 LSA 来降低基于术语的向量空间的维度,获得一个更小的“概念空间”,在这个空间中,许多在文档中倾向于共现的术语将被合并到相同的维度(概念)中。因此,共享概念而不是共享特定术语成为衡量相关性的基础。
当需要对大量文档进行组织以便轻松访问相关主题的项目时,文档聚类非常有用,例如在专利描述、医疗历史或摘要、法律先例或带标题的图像集合中,通常以分层方式组织。聚类在探索性数据分析中也很有用(例如,在探索未知语言中的标记出现情况),并且间接支持各种自然语言处理应用,因为它在改进语言模型方面非常有用,例如提供用于在数据稀疏性情况下从特定词语中回退的词群。
聚类在其他领域广泛应用,例如生物医学研究和流行病学、市场研究和商品推荐、教育研究、社交网络分析、地质分析等等。
文档检索和聚类通常作为信息提取(IE)或文本挖掘的初步步骤,这两个重叠的领域关注从文档中提取有用的知识,例如命名实体的主要特征(类别、与其他实体的关系角色、位置、日期等)或特定类型事件的特征,或推断关系术语之间类似规则的相关性(例如,购买一种产品与购买另一种产品相关)。
我们不打算全面调查 IE/文本挖掘应用,但下面的两个小节,即摘要和情感分析,是特别感兴趣的子领域,因为它们强调文本的语义内容。
10.3 知识提取和摘要
从非结构化文本中提取知识或生成摘要是越来越重要的应用,考虑到新闻媒体、各种组织和个人发布的大量文件。这种不断涌现的信息流使得很难对与某个特定目的相关的项目有一个全面的了解,比如有关个人、组织和消费品的基本数据,或者事故、地震、犯罪、公司收购、产品维护和修理活动、医学研究结果等的详细信息。
在知识提取和某些类型的“机械”摘要中,常用的方法之一是使用提取模式;这些模式旨在匹配作者通常用来表达所关注信息的传统语言模式。例如,可以通过在已知的公司名称和术语(如“Corp.”、“.com”、“总部位于”、“年收入”)以及词性和依存关系上进行关键词匹配,从文本语料库或新闻中提取有关公司的信息,并通过与包含关键短语或靠近关键短语的本地文本段落进行正则表达式模式匹配。另一个例子是地震报告的摘要,可以提取预期的信息,如震中位置、里氏震级、事件的时间和持续时间、受影响的人口中心、死亡人数、受伤人数和财产损失、火灾和海啸等后果。提取模式通常可以被视为针对预定属性-值框架中的特定属性(例如公司信息框架或地震事实框架)的目标,填充的框架本身可以被视为摘要,或者用于生成自然语言摘要。这种类型的早期系统包括 FRUMP(DeJong 1982)和 JASPER(Andersen 等,1992)。在数百种更现代的提取系统中,一个在竞赛中特别成功的系统是 SRI 的“Fastus”(Hobbs 等,1997)。
请注意,将基于模式的系统视为知识提取系统还是摘要系统取决于其应用于的文本。如果所有感兴趣的信息都捆绑在一个单独的扩展文本段中(如地震报告的情况),那么提取出的知识可以被视为该段落的摘要。相反,如果信息是从大型文本集合中零散的句子中有选择地提取出来的,而大部分材料被忽略为与提取目的无关,则我们将视系统的活动为信息提取而不是摘要。
当无法假设要总结的文件属于某种可预测的类别,并且内容以一种模式化的方式进行结构化和表达时,通常通过从文件中选择和组合“中心句子”来进行总结。一个句子在很大程度上是中心的,因为在文档中有许多其他句子与之相似,无论是在共享的词内容方面还是在一些更复杂的相似度度量上,例如基于词项的 tf-idf 度量或在降维向量空间中的余弦度量(因此,我们将单个句子视为文档,并找到一些与其余句子的“相关性”最大的句子)。然而,仅仅返回一系列中心句子通常不能产生一个足够的摘要。例如,这些句子可能包含未解决的代词或其他指代表达式,其指代物可能需要在非中心句子中寻找。此外,中心的“句子”实际上可能是包含不重要的补充信息的较长句子中嵌入的从句。需要应用启发式技术来识别和删除额外的材料,并且提取的从句需要流畅而连贯地组合。在其他情况下,复杂的描述应该更简单和抽象地改写。例如,对于像“龙卷风把当地一座农舍的屋顶吹走,并将其墙壁和内容物变成了碎石”这样的句子,适当的概括可能是“龙卷风摧毁了一座当地的农舍。”但是,尽管当前的系统在某种程度上部分解决了这些问题,但类似人类的总结将需要比目前可达到的更深入的理解。在这个领域的另一个困难(甚至比机器翻译更加如此)是对摘要的评估。即使是人类的判断也会有很大的差异,这取决于评估者对语法缺陷和内容不足的敏感性,例如。
10.4 情感分析
情感分析是指对文章或博客作者对商业产品、电影、组织、个人、意识形态等的态度(或更具体的态度,如信仰或蔑视)进行积极或消极的检测。由于其对产品营销和排名、社交网络分析、政治和情报分析、基于写作样本的人格类型或障碍分类以及其他领域的潜在重要性,这已成为应用计算语言学中非常活跃的领域。所使用的技术通常基于情感词典,对词汇项目的情感极性进行分类,并应用于从中提取了词语和短语特征,并手动标记为对某个主题表达积极或消极态度的文本的监督式机器学习。除了手动标记外,现有数据有时可以用于提供先验分类信息。例如,博客作者对消费品或电影的平均数值评级可以用于学习对属于相同或类似类型的未评级材料进行分类。事实上,情感词汇类别和对比关系可以从这些数据中学习到;例如,在涉及评分高、中、低的电影的博客中频繁出现 "great movie"、"pretty good movie" 或 "terrible movie" 等短语,可能表明 "great"、"pretty good" 和 "terrible" 属于从非常积极到非常消极的对比谱。这种术语知识反过来可以提高通用情感词典的覆盖范围。 然而,基于词汇和短语特征的情感分析存在明显的局限性,比如对讽刺和讽刺的无视(“这是自德州电锯杀人狂以来最微妙和敏感的电影”),引用与作者相反的观点(“根据广告,Siri 是自 iTunes 以来最棒的应用程序,但实际上…”),以及对蕴涵的理解不足(“与购买这个物品相比,你买一双羊毛内衣会好得多”)。因此,研究人员正在尝试将基于知识和语义分析与基于词汇和短语的情感分析相结合。
10.5 聊天机器人和友好对话代理
当前的聊天机器人是 Weizenbaum 的 ELIZA 的后代(见第 1.2 节),通常用于娱乐,或者吸引某些“点卡”网站的访客的兴趣(通常带有一个动画的“说话头像”角色)。它们可以配备大型手工制作的脚本(关键字索引的输入-响应模式),使它们能够回答关于公司和产品的简单查询,并具有一定的能力回应各种话题并交换问候和客套话。一个不那么良性的应用是将聊天机器人伪装成社交网络站点的访客,或者互动游戏站点,目的是从不知情的人类参与者那里获取私人信息,或向他们推荐网站或产品。因此,许多社交网络站点已经加入其他针对机器人的站点,使用 CAPTCHA 来阻止机器人进入。
随附性对话代理(也称为关系代理)迄今为止相当依赖于聊天机器人技术,即编写的输入模式和相应的输出。但目标是超越这些技术,创建具有个性特征、能够表现情感和同理心的代理(通常具有说话头或其他动画角色);它们应该具有语义和情节记忆,长期了解用户并为用户提供服务。这些服务可能包括除了陪伴和支持之外的生活、健康和健身、日程维护、提醒、问题解答、辅导(例如语言)、游戏和互联网服务的建议。Yorick Wilks 建议这样的角色理想情况下应该类似于“维多利亚时代的伴侣”,具有礼貌、谨慎、谦逊、快乐和博学的特点(Wilks 2010)。
然而,这些目标远未实现,因为语音识别、语言理解、推理和学习的进展还远远不够。作为现有技术的一个值得注意的例子,我们可以提到 Pulman 等人(2010)的 HWYD(“你今天过得怎么样”)系统,在一个自治代理会议上获得了最佳演示奖。该系统的自然语言处理相对复杂。浅层句法和语义处理用于查找约 30 个“事件模板”的实例,例如“X 和 Y 之间的工作争论”或“关于 Y 与 X 的会议”。解释过程包括参照和省略解析,依赖于对话管理器维护的信息状态表示。对话管理器生成的目标通过规划导致响应,其中涉及响应范例的实例化和排序。作者报告了该系统在超过 20 分钟的对话中保持一致的能力。
一种完全不同的系统,旨在进行临床基础健康咨询,也在不断发展中。例如,(Bickmore 等人,2011)中描述的系统依赖于临床证明的咨询策略和知识的广泛、精心设计的形式化表达,表达在一个描述逻辑(OWL)和一个目标导向的任务描述语言中。这样的系统已经证明能够以与人类顾问相媲美的方式执行。然而,尽管对话是计划驱动的,但最终由系统脚本化的话语与提供给客户的多项选择列表的回应组成。
因此,伴侣系统在处理对话主题、理解语言以及在对话中运用广泛的常识,甚至运用这种知识进行推理方面都受到非常严格的限制。
10.6 虚拟世界、游戏和交互式小说
在 20 世纪 70 年代早期和中期开始开发基于文本的冒险(任务)游戏,例如《地下城与巨龙》、《猎杀瓦普斯》(原始版本)和《冒险》。这些游戏通常以文本描述游戏环境和玩家面临的挑战为特色,并允许玩家通过简单的命令行输入选择可用的动作(例如“打开箱子”、“拿起剑”或“读取便条”)。虽然游戏环境的描述(通常附有图片)可以非常详细,就像冒险小说一样,但玩家可用的输入选项一直受到限制,这些选项可以在游戏程序员的预发布测试中预料到或收集,并且可以手动准备响应。当然,更灵活地使用自然语言(例如“用剑击退小妖精!”、“如果我给你金币,你会为我打开大门吗?”)将使玩家与游戏世界及其中的角色之间的互动更加生动。在 20 世纪 80 年代和 90 年代,基于文本的游戏逐渐被以图形和动画为主的游戏所取代,尽管多年来在线交互式小说社区不断发展,推动了有效的交互式小说开发软件的演进。在 2000 年,一款备受赞誉的程序是 Emily Short 的《加拉泰亚》,它可以与一个动画雕塑进行对话。然而,这仍然是一个精心编写的程序,只允许输入可以启发式地映射到各种预编程响应之一。这个类型的许多游戏还利用类似聊天机器人的输入-输出响应模式,以获得对意外用户输入的一定程度的鲁棒性。
20 世纪 90 年代及以后最受欢迎的个人电脑游戏是罗宾和兰德·米勒的《谜》(Myst),这是一款第一人称冒险游戏,以及 Maxis Software 的《模拟人生》(The Sims),这是一款生活模拟游戏。《谜》主要依靠书籍和期刊中的信息,基本上是非语言的,而《模拟人生》的首席开发人员威尔·赖特通过让 SimCity 的居民用 Simlish(一种包含乌克兰语、法语和塔加洛语元素的无意义语言)胡言乱语来解决自然语言对话的问题。
商业冒险游戏和视觉小说继续依赖于脚本对话树,即对话可能转向的分支方向,其中类似 ELIZA 的技术支持这些选择。在各个研究实验室中,正在开发更复杂的用户与虚拟角色之间的交互方法,例如宾夕法尼亚大学人体建模与仿真中心以及与南加州大学相关的创新技术研究所。虽然这些场景中的对话仍然基于精心设计的脚本,但用户口头表达的解释利用了语音识别、对话管理和推理等多种基于良好基础的技术。正在进行的研究可以在 IVA(智能虚拟代理)、AIIDE(人工智能和互动数字娱乐)和 AAMAS(自治代理和多代理系统)等会议上进行跟踪。
10.7 自然语言用户界面
NL 用户界面的主题涵盖了各种各样的 NL 应用,从最小程度依赖理解的基于文本的系统到在文本或语音交互中具有重要理解和推理能力的系统。以下小节简要概述了一系列传统和当前的应用领域。
基于文本的问答
基于文本的问答在实践中是可行的,前提是被问的问题类型可以在 QA 系统访问的文本语料库中找到现成的答案。在互联网内容蓬勃发展的时代,这变得更加可行,而几十年前则不太可能,尽管问题仍然需要是直接的、事实性的问题(例如,“谁杀了林肯总统?”),而不是需要推理的问题(例如,“叶卡捷琳娜大帝生活在哪个世纪?”),更不用说“我需要多少个 8 英尺长的 2x4 木材来建造一个 4 英尺高、15 英尺长的尖顶围栏?”这样的问题了。
基于文本的问答(QA)从问题分类开始(例如,是非问题、谁的问题、什么问题、何时问题等),然后根据确定的问题类型进行信息检索,然后缩小搜索范围到可能包含问题答案的段落和句子。连续的缩小通常使用词语和其他特征匹配,最终使用依赖关系和角色匹配,以及可能的有限文本推理来验证答案候选项。文本推理可以使用 WordNet 上位词知识,例如尝试确定给定的候选答案句子是否支持问题的陈述版本的真实性。由于所选句子可能包含无关材料和指代,因此需要提取相关材料(可能还包括支持上下文)并生成一个形式良好、适当的答案。许多早期的基于文本的 QA 系统直到 1976 年都在 Bourne&Hahn 2003 中讨论。后来的调查(例如 Maybury 2004)倾向于包括 QA 方法的完整范围,但 TREC 会议记录(https://trec.nist.gov/)中有许多关于基于文本的 QA 实施系统的论文。
在开放领域的问答中,许多问题涉及到命名实体的属性,例如出生日期、出生地、职业以及其他著名现代和历史人物的个人属性,各种公司的所有权、产品,消费品的相关事实,地理事实等等。为了回答这些问题,将相关的事实预先组织成一个大型知识库是有意义的,可以使用类似第 8 节中的知识获取方法。包含大量关于命名实体事实的系统的示例包括在华盛顿大学开发的几个系统,将事实存储为文本片段,以及将收集到的事实映射到 RDF(资源描述框架)三元组的各种系统(参见其他互联网资源中的参考文献)。其中一些系统不仅从开放信息提取和有针对性的关系提取中获取知识,还从维基百科的“信息框”和(受控的)众包等来源获取知识。在这里,我们也在扩展问答的概念,因为其中几个系统需要使用关键词或查询模式来检索事实。
从一般用户的角度来看,构建这样的知识库能够带来多少附加好处还不清楚,因为谷歌和其他搜索引擎具有出色的能力,可以快速回答诸如“哪些欧洲国家是内陆国?”(不带引号输入,谷歌会使用 True Knowledge 找到最佳答案),或者“肯尼迪任命了多少位最高法院大法官?”等问题。尽管如此,谷歌和微软最近都推出了庞大的“知识图谱”,其中包含数千个实体之间的关系。其目的是提供直接答案(而不仅仅是检索到的网页片段)以回答查询词和自然语言问题,并推断用户的意图,例如购买某种类型的物品或服务。
数据库前端
长期以来,自然语言处理技术一直被认为是数据库的有吸引力的应用之一,从 LUNAR(Woods 等,1972 年)和 REL(Thompson 等,1969 年;Thompson 和 Thompson,1975 年)等系统开始。其吸引力在于,从关系(或其他统一结构)数据库中检索和操作信息可以假定由现有的数据库查询语言和过程处理。这个特性严格限制了用户可能提出的自然语言问题的种类,例如旨在检索满足给定关系约束的对象或对象元组的问题,或者提供关于它们的摘要或极值属性(最长的河流,最低的成本等)。它还极大地简化了解释过程和问答过程,因为目标逻辑形式——形式化的数据库查询——具有已知的精确语法,并且由数据库管理系统自动执行,只需将计算结果以适当的语言、表格或图形形式显示出来。
自那时以来,已经建立了许多系统,旨在应用于海军舰船及其部署的数据(Ladder:Hendrix 等,1978 年),土地利用规划(Damerau,1981 年),地理问答(Chat-80:Pereira&Warren,1982 年),检索保险公司、石油公司、制造商、零售商、银行等的公司记录和产品记录(Intellect:Harris,1984 年),编制有关公司的客户、服务、资产等的统计数据(Cercone 等,1993 年),以及更多(例如,请参见 Androutsopoulos&Ritchie,2000 年)。然而,这些系统的商业影响仍然有限,因为它们通常缺乏传统数据库访问的可靠性和某些功能。
推理(基于知识的)问答
我们已经注意到文本问答系统和用于数据库的自然语言前端具有某些有限的推理能力,例如使用涉及的术语之间的简单语义关系来确认候选答案和问题之间的蕴涵关系,以及对数据库中的数据集进行排序或分类,并计算平均值甚至创建统计图表的能力。
然而,这种有限的、专门的推理方法远远不能满足基于符号知识的一般推理的要求,而这一要求在人工智能问答中一直是目标。最早创建真正推理问答系统的努力之一是 L. Stephen Coles(Coles 1972)的 ENGLAW 项目。ENGLAW 旨在成为一种科学家和工程师获取有关物理定律信息的系统原型。它具有一个包含 128 个重要物理定律的公理知识库(使用一本参考文本的帮助手动编码的一阶逻辑)。问题(例如“在佩尔蒂耶效应中,产生的热量是否取决于电流的方向?”)通过转换语法解析器转化为逻辑形式,并通过将短语模式映射到逻辑表达式的产生式(借助各种 Lisp 函数)进行处理。该系统并未发展到实际可用的程度,但它在推理和自然语言处理技术的整合以及有选择地检索公理进行推理问答的方法方面做出了值得注意的贡献。
一个后来针对实际目标的大规模系统的例子是 BBN 的 JANUS 系统(Ayuso 等,1990 年)。该系统旨在用于海战管理应用,并能够回答关于船只位置、准备情况、速度和其他属性的问题,允许随着时间的推移进行变化。它将英文查询映射到一个非常表达能力强的初始表示语言,其中包含一个“内涵”运算符来将公式与时间和可能世界相关联,然后将其映射到 NIKL 描述逻辑,这对于目标类型的大多数推理来说是足够的。
跳跃到未来,我们注意到基于网络的 Wolfram|Alpha(或 WolframAlpha)答案引擎,由 Wolfram Research 开发,包含 1500 万行基于策划数据、模型和算法的 Mathematica 代码,适用于数千个不同领域。(Mathematica 是由英国科学家 Stephen Wolfram 开发的面向数学的高级编程语言。)该系统主要针对定量问题(例如,“法国的国内生产总值是多少?”或“月球的表面积是多少?”),通常提供图表和图形以及更直接的答案。将英语查询解释为应用于各种已知对象的函数是通过 Mathematica 的模式匹配和符号操作能力实现的。然而,目前英语的理解能力并不特别强大。例如,“林肯去世时多大?”、“林肯去世时几岁?”和其他变体都无法理解,尽管在许多误解的情况下,Wolfram|Alpha 显示了足够的检索信息以允许推断出一个答案。一个相关的缺点是,Wolfram|Alpha 的定量技能没有得到重要的定性推理技能的补充。例如,“苏格拉底是人吗?”(同样,在撰写本文时)会显示关于苏格拉底的摘要信息,包括一张图片,但没有直接回答这个问题。尽管如此,Wolfram|Alpha 的定量能力不仅在独立模式下很有趣,而且作为搜索引擎(如 Microsoft Bing)和基于语音的个人助手(如 Apple 的 Siri)的增强也很有用(见下文)。
另一个因其在《危险边缘》问答节目中取得电视胜利而广受认可的 QA 系统是 IBM 的“沃森”(Ferrucci 2012; Ferrucci et al. 2010; Baker 2011)。与 Wolfram|Alpha 类似,这在某种意义上是一个蛮力程序,由 20 名研究人员和软件工程师核心团队在三年时间内编写了约一百万行 Java、C++、Prolog 和其他语言的代码。该程序在九十台 IBM Power 750 服务器上并行运行 3000 个进程,并可以访问来自 Wordnet、维基百科(以及其结构化衍生物 YAGO 和 DBpedia)、词库、新闻稿和文学文本等来源的 2 亿页内容,总计几 TB 的人类知识。(这相当于大约 1010 个从句块,这个数字可能比任何一个人所掌握的基本事实数量大两个数量级。)
与依赖于任何单一的语言或语义分析方法,或判断检索段落和文本“要点”相关性的方法不同,Watson 应用多种方法来处理问题和候选答案,包括问题分类方法、焦点实体检测、解析、分块、词法分析、逻辑形式计算、指代确定、关系检测、时间分析,以及针对包含 Jeopardy!中常见的双关语、变位词和其他变化的问题-答案对的特殊方法。不同的问题分析被分别用于检索相关文档,并从这些文档中的段落和句子中推导、分析和评分潜在答案。通常情况下,一个问题会产生多个候选答案,它们的分析提供了数百个特征,这些特征的权重用于通过应用于过去 Jeopardy!问题和答案(或者根据 Jeopardy!协议的奇特假设,答案和问题)的语料库来学习获得排名答案及其相应置信水平的机器学习方法。Watson 的赌注基于其潜在答案的置信水平和复杂的回归模型。
沃森在我们的推理、基于知识的问答系统中的适应程度如何?它是否真正理解问题和产生的答案?尽管在与《危险边缘》冠军的比赛中表现出色,沃森只能以非常有限的方式推理和理解英语。该程序利用了《危险边缘》问题的目标通常是一个命名实体,例如吉米·卡特、伊斯兰堡或加尔各答黑洞,尽管偶尔也会针对其他类型的短语。沃森很可能会找到多个提到所需类型的特定实体的句子,其句法和语义特征与问题的特征接近,从而使命名实体成为一个合理的答案,但并不真正理解问题。例如,一个“最近的历史”问题询问美国在哪位总统任期内对共产主义中国给予了全面承认(Ferrucci 2012),可能会将注意力集中在以下句子上:
尽管他是 1978 年恢复与中国全面外交关系的总统,吉米·卡特从未访问过那个国家...(《纽约时报》,1981 年 6 月 27 日)
或者
1978 年,吉米·卡特总统正式承认中国后不久,两国核科学家之间的交流就开始了。(《纽约时报》,2001 年 2 月 2 日)
尽管这些句子与正确答案之间的联系是间接的(例如,依赖于将“他”和“谁”解释为吉米·卡特,并将“恢复外交关系”与“承认”联系起来,将“共产主义中国”与“中国”联系起来),但对这些联系的正确分析并不是成功的必要条件——只要那些支持吉米·卡特答案的句子群(通过它们的词汇和短语内容以及其他许多特征)比任何竞争的句子群提供更大的净权重,就足以使其成为答案。基于存储文本的这种统计证据组合似乎不太可能为人们在回答简单的常识问题时所表现出的理解提供一条路径,比如“下雨时人们如何不被淋湿?”或者“如果你吃了一个饼干,饼干会发生什么?”与此同时,以类似沃森的方式利用大量数据库可以弥补各种应用中的推理弱点,IBM 正在积极重新开发沃森,将其作为医生的资源,这样即使专家们可能没有的诊断和治疗可能性也能提供。总之,基于真正的理解和基于知识的推理的开放领域问答的目标仍然基本上没有实现。
基于语音的网络服务和助手
基于语音的服务,尤其是在移动设备上,是一个快速扩展的应用领域。这些服务范围从组织者(用于杂货清单、会议日程、提醒、联系人列表等),到车载“信息娱乐”(路线规划、交通状况、危险警告、iTunes 选择、附近餐厅和其他场所的查找等),再到启用其他杂项应用程序,如电子邮件口述、拨打联系人、金融交易、预订和下订单、维基百科访问、帮助台服务、健康咨询和一般问题回答。其中一些服务(如拨号和 iTunes 选择)属于免提控制的范畴,这样的控制在交通(包括无人驾驶或无人驾驶车辆)、物流(资源部署)和制造业中变得越来越重要。此外,聊天机器人技术和可交谈的对话代理人(如第 10.5 节所讨论的)正在作为更具体的基于语音的服务的通用后端。
这些服务中的关键技术当然是语音识别,其准确性和适应性逐渐增强。最便宜、针对性较窄的系统(例如简单的组织者)利用对用户输入的强烈期望来识别、解释和响应这些输入;因此它们类似于菜单驱动的系统。更多功能的系统,例如可以处理路由、音乐请求、场所搜索等的车载对话系统,依赖于更先进的对话管理能力。这些能力允许主题切换,并且可能考虑到用户的注意状态(例如,如果驾驶员需要注意转弯,可以延迟回答驾驶员的问题)。目前最受关注的是先进的基于语音的助手,尤其是 iPhone 的 Siri(其次是 Android 的 Iris、True Knowledge 的 Evi、Google Now 等)。虽然之前的语音控制和听写系统(如 Android 的 Vlingo)具有许多相同的功能,但 Siri 增加了个性化和改进的对话处理和服务集成——用户感觉自己正在与一个活泼的合成角色而不是一个应用程序进行交互。除了 Nuance SR 技术,Siri 还结合了复杂的技术,这些技术在 2003 年至 2008 年由 SRI International 和多所大学进行的 Calo(学习和组织的认知助手)项目推动下得到了一定程度的发展(Ambite 等人,2006 年;CALO [参见其他互联网资源])。这些技术包括 NLU、ML、目标导向和不确定推理、本体论、规划和服务委派的方面。但是,尽管委派给 Web 服务(包括 Wolfram|Alpha QA)或聊天机器人技术提供了相当大的鲁棒性,并且对于日程安排、购买和其他有针对性的服务进行了重要的推理,但总体理解仍然非常浅显,用户很快就会发现这一点。 严重误解的轶事性例子是“叫救护车”引发的回应是“从现在开始我会叫你‘救护车’”。然而,用户社区对这些早期(有点)智能、非常多才多艺的助手的浓厚兴趣和需求很可能会加剧和加速对越来越逼真的虚拟代理人的研究,这些代理人具有越来越多的理解力和常识。
10.8 协作问题解决者和智能导师
我们将协作问题解决系统(也称为“混合主动”或“任务导向”对话系统)和教程对话系统(即对话在其中起关键作用的教程系统)放在一个共同的标题下进行讨论,因为两者都依赖于对其目标领域以及与之互动的用户的心理状态的相当深入的表示或模型。
然而,我们应立即注意到,协作解决问题的系统通常处理的领域情况和用户输入比教学系统要不可预测得多,因此前者比后者更加注重灵活的对话处理。例如,紧急疏散中的合作者(Ferguson 和 Allen 1998, 2007)需要处理一个动态变化的领域,同时处理可能发生的许多对话状态,这取决于参与者在任何给定点上的共享和私人信念、目标、计划和意图。相比之下,在物理教学领域(例如,Jordan 等人 2006;Litman 和 Silliman 2004),学习者可以通过网络学习目标和编写的指导进行引导,并且可以设计有限状态对话模型,以对话中的每个点对学生输入进行分类,并生成一个准备好的响应,该响应可能适用于该输入。
因此,不足为奇的是,教程对话系统比用于实际应用的协作问题解决系统更接近商业实用性,并在各种评估中展示了相对于传统教学的学习效益。教程对话系统已经应用于多个领域和潜在客户群,包括 K-12 科目、计算机素养和初学者编程、定性和定量物理学、电路分析、机械操作、心血管生理学、船舶火灾控制、谈判技巧等(例如,参见 Boyer 等人 2009 年;Pon-Barry 等人 2006 年)。最成功的教程系统之一是阅读辅导系统(例如,Mostow 和 Beck 2007 年;Cole 等人 2007 年),因为在这种情况下,向学习者呈现的材料(以“脚手架”方式)相对容易设计,并且学习者的反应,特别是当它们主要是朗读呈现的文本时,相对容易评估。对于更具雄心壮志的阅读理解目标,核心问题是设计对话以使学习者的贡献可预测,同时也使互动具有教育效果(例如,Aist 和 Mostow 2009 年)。
一些辅导系统,特别是针对儿童的系统,使用动画角色来增强学习者的参与感。这样的增强措施对于针对听力障碍(学习者可以通过观察虚拟代理人的口腔和舌头运动来帮助发音)、自闭症或失语症等残障学习者的系统实际上是必不可少的(Massaro 等人 2012 年;Cole 等人 2007 年)。此外,如果辅导的目标是培养人际交往技巧,那么实现逼真角色(虚拟人)将成为系统开发中不可或缺的一部分(例如,Core 等人 2006 年;Campbell 等人 2011 年)。
在辅导系统中对用户心态进行建模主要是确定用户已经掌握或尚未掌握的目标概念和技能,并根据会话记录诊断可能发生的误解。一些最近的实验系统还可以根据用户的明显情绪(如沮丧或无聊)来调整策略,这可以通过用户的输入、语调,甚至通过计算机视觉分析的面部表情或手势来揭示。其他原型系统可以被视为朝着更一般的心理建模努力,通过将任务导向的对话系统中关于对话状态、对话行为和更深层次的语言理解的思想和技术进行整合(例如,Callaway 等人,2007 年)。
如前所述,在任务导向的对话系统中,对话建模更具挑战性,因为这些系统不仅被期望为解决领域问题做出贡献,还要理解用户的话语、信念和意图,并在人类般的混合主动对话中保持自己的立场。这需要领域模型、一般增量协作规划方法、模拟理性的交流互动的对话管理以及对所选择领域的彻底语言理解(尤其是意图识别)。已经成功构建了原型系统,用于领域如路径规划、航空旅行规划、驾驶员和行人导航、外部设备的控制和操作、紧急疏散和药物咨询(例如,Allen 等人,2006 年;Rich 和 Sidner,1998 年;Bühler 和 Minker,2011 年;Ferguson 和 Allen,1998 年,2007 年),这些系统具有非常重要的实际应用前景。然而,能够处理各种相当复杂的问题,特别是需要关于人类认知和行为的广泛常识知识的问题,目前似乎仍然难以实现。
10.9 语言启用的机器人
正如第 10 节开头所指出的,机器人开始配备网络服务、问答能力、聊天机器人技术(用于备用和娱乐)、辅导功能等。将这些技术转移到机器人上的过程一直很缓慢,主要是因为仅仅为机器人配备基本的视觉感知、语音识别、探索和目标导航(对于移动机器人而言)以及物体操作所需的硬件和软件是非常困难的挑战。然而,公众对智能机器人的浓厚兴趣以及它们在家庭帮助、老年护理、医疗、教育、娱乐、农业、工业、搜救、军事任务、太空探索等领域的巨大经济潜力,必将继续推动对更强大的机器人智能和语言能力的追求。
从(Scheutz et al. 2011)可以获得对人机对话的最新技术和困难的良好了解。其中一些关于盒子和积木的对话示例让人想起了 Winograd 的 shrdlu,但它们也展示了真实交互中所涉及的挑战,如机器人移动时的场景变化、语音识别错误、不流畅和复杂的多句子话语、依赖视角的话语(“红盒子在蓝盒子的左边吗?”)以及指示性话语(“往下走”)。此外,所有这些都必须与物理行动相结合,以便按照机器人理解的指令来执行。尽管最近的机器人在某种程度上能够处理这些困难,但仍然存在许多未解决的问题,例如在噪声环境中的语音识别问题、更好、更广泛的语言覆盖、解析和对话处理、适应新问题、对话者和环境中其他人的心理建模,以及对世界的更广泛的知识和使用它进行推理和规划的能力(无论是在领域层面还是对话层面)。
虽然面向任务的机器人对话涉及所有这些挑战,但我们应该注意到,与“说话”的机器人进行的一些潜在有用的交互对于语言技能要求很少。例如,(Movellan 等人,2009)描述的 Rubi 机器人在配备屏幕的“胸部”上展示物体给幼儿,要求他们触摸并命名物体。尽管交互的简单性,这导致幼儿的词汇学习得到了改善。另一个没有真正语言技能但非常成功的说话机器人的例子是“博物馆导游”Rhino(Burgard 等人,1999)。与 Rubi 不同,它能够在不可预测的移动人群中导航,并通过屏幕上显示的当前目标和预先录制的信息吸引观众。同样,世界各地的许多人形机器人(例如本田的 Asimo)在过去和现在的开发中仍然对语言了解很少,主要依赖于脚本输出。毫无疑问,由于上述技术(游戏、伴侣代理系统、基于语音的应用程序、导师等)的存在,它们的实用性和吸引力将继续增长;这些发展也将推动对感知、运动、操作和有意义对话的更深层次的进展。
Bibliography
Aist, G. & J. Mostow, 2009, “Predictable and educational spoken dialogues: Pilot results,” in Proceedings of the 2009 ISCA Workshop on Speech and Language Technology in Education (SLaTE 2009). Birmingham, UK: University of Birmingham. [Aist & Mostow 2009 available online (pdf)]
Allen, J.F., 1995, Natural Language Understanding, Redwood City: Benjamin/Cummings.
Allen J., W. de Beaumont, L. Galescu, J. Orfan, M. Swift, and C.M. Teng, 2013, “Automatically deriving event ontologies for a commonsense knowledge base,” in Proceedings of the 10th International Conference on Computational Semantics (IWCS 2013), University of Potsdam, Germany, March 19–22. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Allen et al. 2013 available online (pdf)]
Allen, J., G. Ferguson, N. Blaylock, D. Byron, N. Chambers, M. Dzikovska, L. Galescu, and M. Swift, 2006, “Chester: Towards a personal medical advisor,” Biomedical Informatics, 39(5): 500–513.
Allen, J.F. and C.R. Perreault, 1980, “A plan-based analysis of indirect speech acts,” Computational Linguistics, 6(3–4): 167–182.
Ambite, J.-L., V.K. Chaudhri, R. Fikes, J. Jenkins, S. Mishra, M. Muslea, T. Uribe, and G. Yang, 2006, “Design and implementation of the CALO query manager,” 21st National Conference on Artificial Intelligence (AAAI-06), July 16–20, Boston, MA; Menlo Park, CA: AAAI Press, 1751–1758.
Andersen, P.M., P.J. Hayes, A.K. Huettner, L.M. Schmandt, I.B. Nirenburg, and S.P. Weinstein, 1992, “Automatic extraction of facts from press releases to generate news stories,” in Proceedings of the 3rd Conference on Applied Natural Language Processing (ANLC '92), Trento, Italy, March 31–April 3. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 170–177. [Andersen et al. 1992 available online (pdf)]
Anderson, J., 1983, The Architecture of Cognition, Mahwah, NJ: Lawrence Erlbaum.
–––, 1993, Rules of the Mind, Hillsdale, NJ: Lawrence Erlbaum.
Anderson, J. & G. Bower, 1973, Human Associative Memory, Washington, DC: Winston.
Androutsopoulos, I. and G. Ritchie, 2000, “Database Interfaces,” R. Dale, H. Somers, and H. Moisl (eds.), Handbook of Natural Language Processing, Chapter 9, Boca Raton, FL: CRC Press.
Asher, N. and A. Lascarides, 2003, Logics of Conversation (Studies in Natural Language Processing), New York: Cambridge University Press.
Auer, S., C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, and Zachary Ives, 2007, “DBpedia: a nucleus for a web of open data,” in Proceedings of the 6th International Semantic Web Conference (ISWC 2007), Nov. 11–15, Busan, Korea. [Auer et al. 2007 available online (pdf)
Austin, J.L., 1962, How to Do Things with Words: The William James Lectures Delivered at Harvard University in 1955, J.O. Urmson (ed.), Oxford: Clarendon Press.
Ayuso, D., M. Bates, R. Bobrow, M. Meteer, L. Ramshaw, V. Shaked, and R. Weischedel, 1990, “Research and development in natural language understanding as part of the strategic computing program,” BBN Report No. 7191, BBN Systems and Technologies, Cambridge, MA.
Baars, B.J., 1997, In the Theater of Consciousness: The Workspace of the Mind, New York: Oxford University Press.
Bach, E., 1976, “An extension of classical transformational grammar,” in Proceedings of the 1976 Conference on Linguistic Metatheory, Michigan State University, 183–224. [Bach 1976 available online]
Bach, E., R. Oehrle, and D. Wheeler (eds.), 1987, Categorial Grammars and Natural Language Structures, Dortrecht: D. Reidel.
Baker, S., 2011, Final Jeopardy, Boston: Houghton Mifflin Harcourt.
Banarescu, L., C. Bonial, S. Cai, M. Georgescu, K. Griffitt, U. Hermjakob, K. Knight, K. Koehn, M. Palmer, and N. Schneider, 2013, “Abstract Meaning Representation for Sembanking”, in Proceedings of the 7th Linguistic Annotation Workshop & Interoperability with Discourse, Sofia, Bulgaria, Aug. 8–9. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Banarescu et al. 2013 available online (pdf)]
Banko, M., M.J. Cafarella, S. Soderland, M. Broadhead, and O. Etzioni, 2007. “Open information extraction from the Web,” in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI-07), Hyderabad, India, January 6–12. [Banko et al. 2007 available online (pdf)]
Bar-Hillel, Y., 1960, “The present status of automatic translation of languages,” Advances in Computers, 1: 91–163.
Barker, C., 2004, “Continuations in natural language”, in Hayo Thielecke (ed.), Proceedings of the 4th ACM SIGPLAN Continuations Workshop (CW'04), Venice, Italy, Jan. 17. Birmingham, UK: University of Birmingham. [Barker 2004 available online]
Barker, K., B. Porter, and P. Clark, 2001, “A library of generic concepts for composing knowledge bases,” in Proceedings of the 1st International Conference on Knowledge Capture, Victoria, B.C., Canada, October 21–23. New York, NY: ACM, pp. 14–21. [Barker, Porter, and Clark 2001 preprint available online]
Barnden, J.A., 2001, “Uncertainty and conflict handling in the ATT-Meta context-based system for metaphorical reasoning,” in Proceedings of the 3rd International Conference on Modeling and Using Context, V. Akman, P. Bouquet, R. Thomason, and R.A. Young (eds.), Lecture Notes in Artificial Intelligence, Vol. 2116, Berlin: Springer, pp. 15–29.
–––, 2006, “Artificial intelligence, figurative language, and cognitive linguistics,” in G. Kristiansen et al. (eds.), Cognitive Linguistics: Current Applications and Future Perspectives, Berlin: Mouton de Gruyter, 431–459.
Barwise, J. and R. Cooper, 1981, “Generalized quantifiers and natural language,” Linguistics and Philosophy, 4(2): 159–219.
Barwise, J., and J. Perry, 1983, Situations and Attitudes, Chicago: University of Chicago Press.
Bengio, Y., 2008, “Neural net language models,” Scholarpedia, 3(1): 3881. [Bengio 2008 available online]
Bickmore, T., D. Schulman, and C. Sidner, 2011, “Modeling the intentional structure of health behavior change dialogue,” Journal of Biomedical Informatics, 44: 183–197.
Bishop, C.M., 2006, Pattern Recognition and Machine Learning, New York: Springer.
Blutner, R., 2004, “Nonmonotonic inferences and neural networks”, Synthese, 141(2): 143–174.
Bobrow, D.G., 1968, “Natural language input for a computer problem-solving system,” in M. Minsky (ed.), Semantic Information Processing, Cambridge, MA: MIT Press, 146–226.
Boser, B.E., I.M. Guyon, and V.N. Vapnik, 1992, “A training algorithm for optimal margin classifiers,” in D. Haussler (ed.), 5th Annual ACM Workshop on COLT, Pittsburgh, PA: ACM Press, 144–152.
Bouaud, J., B. Bachimont, and P. Zweigenbaum, 1996, “Processing metonymy: a domain-model heuristic graph traversal approach,” in Proceedings of the 16th International Conference on Computational Linguistics (COLING'96), Center for Sprogteknologi Copenhagen, Denmark, Aug. 5–9. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 137–142. [Bouaud, Bachimont, and Zweigenbaum 1996 available online (pdf)]
Bourne, C.P. and T.B. Hahn, 2003, A History of Online Information Services, 1963–1976, Cambridge, MA: MIT Press.
Boyer, K.E., E.Y. Ha, M.D. Wallis, R. Phillips, M.A. Vouk, and J.C. Lester, 2009, “Discovering tutorial dialogue strategies with Hidden Markov Models”, in Proceedings of the 14th International Conference on Artificial Intelligence in Education (AIED 2009), Brighton, U.K.: IOS Press, pp. 141–148.
Brakel, P. and S.L. Frank, 2009, “Strong systematicity in sentence processing by simple recurrent networks,” in N.A. Taatgen and H. van Rijn (eds.), Proceedings of the 31st Annual Conference of the Cognitive Science Society, July 30 – Aug. 1, VU University Amsterdam; Red Hook, NY: Curran Associates, Inc., pp. 1599–1604.
Brown, J.S. and R.R. Burton, 1975, “Multiple representations of knowledge for tutorial reasoning,” in D.G. Bobrow and A. Collins (eds.), Representation and Understanding, Academic Press, New York, 311–349.
Browne, A. and R. Sun, 2001, “Connectionist inference models”, Neural Networks, 14: 1331–1355.
Browne, A. and R. Sun, 1999, “Connectionist variable binding”, Expert Systems, 16(3): 189–207.
Bühler, D. and W. Minker, 2011, Domain-Level Reasoning for Spoken Dialogue Systems, Boston, MA: Springer.
Bunt, H.C., 1985, Mass Terms and Model-Theoretic Semantics, Cambridge, UK and New York: Cambridge University Press.
Burgard, W., A.B. Cremers, D. Fox, D. Hahnel, G. Lakemeyer, D. Schulz, W. Steiner, and S. Thrun, 1999, “Experiences with an interactive museum tour-guide robot,” Articial Intelligence, 114(1–2): 3–55.
Bylander, T., 1994, “The computational complexity of propositional STRIPS planning,” Artificial Intelligence, 69: 165–204.
Callaway, C., M. Dzikovska, E. Farrow, M. Marques-Pita, C. Matheson, and J. Moore, 2007, “The Beetle and BeeDiff tutoring systems,” in Proceedings of the 2007 Workshop on Spoken Language Technology for Education (SLaTE), Farmington, PA, Oct. 1–3. Carnegie Mellon University and ISCA Archive. [Callaway et al. 2007 available online]
Campbell, J., M. Core, R. Artstein, L. Armstrong, A. Hartholt, C. Wilson, K. Georgila, F. Morbini, E. Haynes, D. Gomboc, M. Birch, J. Bobrow, H.C. Lane, J. Gerten, A. Leuski, D. Traum, M. Trimmer, R. DiNinni, M. Bosack, T. Jones, R.E. Clark, and K.A. Yates, 2011, “Developing INOTS to support interpersonal skills practice,” in Proceedings of the 32nd Annual IEEE Aerospace Conference (IEEEAC), Big Sky, MT, March 5–12, Institute of Electrical and Electronics Engineers (IEEE), 3222–3235.
Carbonell, J., 1980, “Metaphor—a key to extensible semantic analysis,” in N.K. Sondheimer (ed.), Proceedings of the 18th Meeting of the Association for Computational Linguistics (ACL'80), University of Pennsylvania, PA, June 19–22. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 17–21. [Carbonell 1980 available online (pdf)]
Carlson, G.N., 1977, Reference to Kinds in English, Doctoral Dissertation, University of Massachusetts, Amherst, MA. Also New York: Garland Publishing, 1980.
–––, 1982, “Generic terms and generic sentences,” Journal of Philosophical Logic, 11: 145–181.
–––, 2011, “Generics and habituals,” in C. Maienborn, K. von Heusinger, and P. Portner (eds.), Semantics: An International Handbook of Natural Language Meaning, Berlin: Mouton de Gruyter.
Carlson, G.N. and F.J. Pelletier 1995, The Generic Book, Chicago: University of Chicago Press.
Carpenter, B., 1997, Type-Logical Semantics, Cambridge, MA: MIT Press.
Cercone, N., P. McFetridge, F. Popowich, D. Fass, C. Groeneboer, and G. Hall, 1993, “The systemX natural language interface: design, implementation, and evaluation,” Tech. Rep. CSS-IS TR 93-03, Centre for Systems Science, Simon Fraser University, Burnaby, BC, Canada.
Chambers, N. and D. Jurafsky, 2009, “Unsupervised learning of narrative schemas and their participants,” in Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics (ACL-09), Singapore, Aug. 2–7. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Chambers and Jurafsky 2009 available online (pdf)]
Chater, N. and M. Oaksford (Eds.), 2008, The Probabilistic Mind: Prospects for Rational Models of Cognition, Oxford University Press.
Chen, P., W. Ding, C. Bowes, and D. Brown, 2009, “A fully unsupervised word sense disambiguation method using dependency knowledge,” in Proceedings of the Annual Conference of the North American Chapter of the ACL (NAACL'09), Boulder, CO, June. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 28–36. [Chen et al. 2009 available online (pdf)]
Chomsky, N., 1956, “Three models for the description of language,” IRE Transactions on Information Theory, 2: 113–124. [Chomsky 1956 available online (pdf)]
–––, 1957, Syntactic Structures, Paris: Mouton.
Clark, A., C. Fox, and S. Lappin (eds), 2010, The Handbook of Computational Linguistics and Natural Language Processing, Chichester, UK: Wiley Blackwell.
Clarke, Daoud, 2012, “A context-theoretic framework for compositionality in distributional semantics,” Computational Linguistics, 38(1): 41–71.
Cohen, A., 2002, “Genericity”, in F. Hamm and T.E. Zimmermann (eds.), Semantics, vol. 10, Hamburg: H. Buske Verlag, 59–89.
Cohen, S.B., K. Stratos, M. Collins, D.P. Foster, and L. Ungar, 2013, “Experiments with spectral learning of Latent-Variable PCFGs,” Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2013), June 9–13, Atlanta, GA. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Cohen et al. 2013 available online (pdf)]
Cohen, P.R. and R. Perreault, 1979, “Elements of a plan based theory of speech acts,” Cognitive Science, 3(3): 177–212.
Cole, R., B. Wise, and S. van Vuuren, 2007, “How Marni teaches children to read,” Educational Technology, 47(1): 14–18.
Coles, L.S., 1972, “Techniques for Information Retrieval Using an Inferential Question-Answering System with Natural-Language Input”, Technical Note 74, SRI Project 8696, SRI International.
Conesa, J., V.C. Storey, and V. Sugumaran, 2010, “Usability of upper-level ontologies: the case of ResearchCyc,” Data & Knowledge Engineering, 69(4): 343–356.
Copestake, A., D. Flickinger, I. Sag, and C. Pollard, 2005, “Minimal Recursion Semantics: An introduction,” Research in Language and Computation, 3(2–3): 281–332.
Core, M., D. Traum, H.C. Lane, W. Swartout, S. Marsella, J. Gratch, and M. van Lent, 2006, “Teaching negotiation skills through practice and reflection with virtual humans,” Simulation: Transactions of the Society for Modeling and Simulation, 82: 685–701.
Cortes, C. and V.N. Vapnik, 1995, “Support-vector networks”, Machine Learning, 20(3): 273–297.
Cour, T., C. Jordan, E. Miltsakaki, and B. Taskar, 2008, “Movie/Script: alignment and parsing of video and text transcription,” European Conference on Computer Vision (ECCV), October, Marseille, France.
Crocker, M.W., 2010, “Computational Psycholinguistics”, in A. Clark, C. Fox, and S. Lappin (eds), The Handbook of Computational Linguistics and Natural Language Processing, Chichester, UK: Wiley Blackwell.
Crouch, R., 1995, “Ellipsis and quantification: a substitutional approach,” in Proceedings of the European Chapter of the Association for Computational Linguistics (EACL'95), University College Dublin, March 27–31. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 229–236. [Crouch 1995 available online (pdf)]
Dagan, I., R. Bar-Haim, I. Szpektor, I. Greental, and E. Shnarch, 2008, “Natural language as the basis for meaning representation and inference,” in A. Gelbukh (ed.), Computational Linguistics and Intelligent Text Processing, Lecture Notes in Computer Science 4919, Berlin: Springer, 151–170.
Dalrymple, M., S.M. Shieber, and F.C.N. Pereira, 1991, “Ellipsis and higher-order unification,” Linguistics and Philosophy, 14: 399–452.
Damásio, A.R., 1994, Descartes' Error: Emotion, Reason, and the Human Brain, Kirkwood, NY: Putnam Publishing.
Damerau, F.J., 1981, “Operating statistics for the Transformational Question Answering System,” American Journal of Computational Linguistics, 7(1): 30–42.
Davidson, D., 1967a, “The logical form of action sentences”, in N. Rescher (ed.), The Logic of Decision and Action, Pittsburgh, PA: University of Pittsburgh Press.
d'Avila Garcez, A.S., 2004. “On Gabbay's fibring methodology for Bayesian and neural networks”, in D. Gillies (ed.), Laws and Models in Science, workshop sponsored by the European Science Foundation (ESF), King's College Publications.
DeJong, G.F., 1982, “An overview of the FRUMP system,” in W.G. Lehnert and M.H. Ringle (eds.), Strategies for Natural Language Processing, Erlbaum, 149–176.
Della Pietra, S., V. Della Pietra, and J. Lafferty, 1997, “Inducing features of random fields,” Machine Intelligence, 19(4): 380–393.
de Salvo Braz, R., R. Girju, V. Punyakanok, D. Roth, and M. Sammons, 2005, “An inference model for semantic entailment and question answering,” in Proceedings of the American Association for Artificial Intelligence (AAAI-05), Pittsburgh, PA, July 9–13. Menlo Park, CA: AAAI Press, pp. 1043–1049.
Dowty, D., 1991, “Thematic proto-roles and argument selection,” Language, 67(3): 547–619.
Duda, R.O. and P.E. Hart, 1973, Pattern Classification and Scene Analysis, New York: Wiley.
Duda, R.O., P.E. Hart, and D.G. Stork, 2001, Pattern Classification, New York: Wiley.
Dyer, M.G., 1983, In-Depth Understanding, Cambridge, MA: MIT Press.
Earley, J., 1970, “An efficient context-free parsing algorithm,” Communications of the ACM, 13(2): 94–102.
Faaborg, A., W. Daher, H. Lieberman, and J. Espinosa, 2005, “How to wreck a nice beach you sing calm incense,” in R.St. Amant, J. Riedl, and A. Jameson (eds.), Proceedings of the International Conference on Intelligent User Interfaces (IUI-05), San Diego, CA, January 10–13. ACM Press. [Faaborg et al. 2005 preprint available (pdf)]
Falkenhainer, B., K.D. Forbus, and D. Gentner, 1989, “The Structure-Mapping Engine: algorithm and examples,” Artificial Intelligence, 41: 1–63.
Fan, J., K. Barker, and B. Porter, 2009, “Automatic interpretation of loosely encoded input,” Artificial Intelligence 173(2): 197–220.
Fass, D., 1991, “Met*: a method for discriminating metonymy and metaphor by computer,” Computational Linguistics, 17(1): 49–90.
Feldman, J.A., 2006, From Molecule to Metaphor: A Neural Theory of Language, Cambridge, MA: Bradford Books, MIT Press.
Feldman, J.A. and D.H. Ballard ,1982, “Connectionist models and their properties,” Cognitive Science, 6: 205–254.
Ferguson, G. and J.F. Allen, 1998, “TRIPS: An integrated intelligent problem-solving assistant,” in Proceedings of the 15th National Conference on Artificial Intelligence (AAAI-98). Menlo Park, CA: AAAI Press, pp. 567–573.
–––, 2007, “Mixed-initiative systems for collaborative problem solving,” AI Magazine, 28(2): 23–32.
Ferrucci, D.A., 2012, “This is Watson,” IBM Journal of Research and Development, 56(3–4).
Ferrucci, D., E. Brown, J. Chu-Carroll, J. Fan, D. Gondek, A.A Kalyanpur, A. Lally, J.W. Murdock, E. Nyberg, J. Prager, N. Schlaefer, and C. Welty, 2010, “Building Watson: An overview of the DeepQA project,” AI Magazine, 31(3): 59–79.
Fine, A.B., T.F. Jaeger, T.A. Farmer, and T. Qian, 2013, “Rapid expectation adaptation during syntactic comprehension,” PLoS ONE, 8(1): e77661.
Fleischman, M., and D. Roy, 2005, “Intentional context in situated language learning,” in 9th Conference on Computational Natural Language Learning (CoNLL-2005), Ann Arbor, MI, June 29–30. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Fleischman and Roy 2005 available online (pdf)]
Gärdenfors, P., 2000, Conceptual Spaces: The Geometry of Thought, Cambridge, MA: MIT Press.
Ge, R. and R.J. Mooney, 2009, “Learning a compositional semantic parser using an existing syntactic parser,” in Proceedings of the Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing (ACL-IJCNLP 2009), Suntec, Singapore, August. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 611–619. [Ge and Mooney 2009 available online (pdf)]
Geib, C.W., 2004, “Assessing the complexity of plan recognition,” in Proceedings of the 19th National Conference on Artifical intelligence (AAAI'04), San Jose, CA, July 25–29. Menlo Park, CA: AAAI Press, pp. 507–512.
Glickman, O. and I. Dagan, 2005, “A probabilistic setting and lexical cooccurrence model for textual entailment,” in Proceedings of ACL Workshop on Empirical Modeling of Semantic Equivalence and Entailment, Ann Arbor, MI, June 30. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Glickman and Dagan 2005 available online (pdf)].
Gluck, M.A. and D.E. Rumelhart, 1990, Neuroscience and Connectionist Theory, Hillsdale, NJ: Lawrence Erlbaum.
Goldberg, A.E., 2003, “Constructions: a new theoretical approach to language,” Trends in Cognitive Sciences, 7(5): 219–224.
Goldman, R.P. and E. Charniak, 1991, “Probabilistic text understanding,” in Proceedings of the 3rd International Workshop on AI and Statistics, Fort Lauderdale, FL. Also published in D.J. Hand (ed.), 1993, Artificial Intelligence Frontiers in Statistics: AI and Statistics III, London, UK: Chapman & Hall.
Gordon, J. and L.K. Schubert, 2010, “Quantificational sharpening of commonsense knowledge,” Common Sense Knowledge Symposium (CSK-10), AAAI 2010 Fall Symposium Series, November 11-13, Arlington, VA, AAAI Technical Report FS-10-02, Menlo Park, CA: AAAI Press.
Gregory, H. and S. Lappin, 1997, “A computational model of ellipsis resolution,” in Proceedings of the Conference on Formal Grammar (Linguistic Aspects of Logical and Computational Perspectives on Language), 9th ESSLLI, Aix-en-Provence, France: European Summer School, August 11–27.
Grice, H.P., 1968, “Utterer's meaning, sentence meaning and word meaning,” Foundations of Language, 4: 225–242.
Groenendijk, J. and M. Stokhof, 1991, “Dynamic predicate logic,” Linguistics and Philosophy, 14(1): 39–100.
Grosz, B.J. and C.L. Sidner, 1986, “Attention, intentions, and the structure of discourse,” Computational Linguistics, 12(3, July-September): 175–204.
Hadamard, J., 1945, The Psychology of Invention in the Mathematical Field, Princeton, NJ: Princeton University Press.
Haghighi, A. and D. Klein, 2010, “Coreference resolution in a modular, entity-centered model,” in Proceedings of the Annual Conference of the North American Chapter of the ACL (HLT-NAACL 2010), Los Angeles, June. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 385–393. [Haghighi and Klein 2010 available online (pdf)]
Hardt, D., 1997, “An empirical approach to VP ellipsis,” Computational Linguistics, 23(4): 525–541.
Harris, L.R., 1984, “Experience with INTELLECT: Artificial Intelligence technology transfer,” AI Magazine, 5(2): 43–50.
Havasi, C., R. Speer, and J. Alonso, 2007, “ConceptNet 3: a flexible, multilingual semantic network for common sense knowledge,” in N. Nicolov, G. Angelova, and R. Mitkov (eds.), Proceedings of Recent Advances in Natural Language Processing (RANLP-07), Borovets, Bulgaria, Sept. 27–29. Amsterdam:John Benjamins.
Hearst, M., 1992, “Automatic acquisition of hyponyms from large text corpora,” in Proceedings of the 14th International Conference on Computational Linguistics (COLING-92), Nantes, France, Aug. 23–28. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 539–545. [Hearst 1992 available online (pdf)]
Heim, I.R., 1982, The Semantics of Definite and Indefinite Noun Phrases, Doctoral dissertaton, University of Massachusetts, Amherst.
Henderson, J., 1994, “Connectionist syntactic parsing using temporal variable binding,” Journal of Psycholinguistic Research 23(5): 353–379.
Hendrix, G.G., E.D. Sacerdoti, D. Sagalowicz, and J. Slocum, 1978, “Developing a natural language interface to complex data,” ACM Transactions on Database Systems, 3(2): 105–147.
Hewitt, C., 1969, “PLANNER: A language for proving theorems in robots,” in D.E. Wlaker and L.M. Norton (eds.), Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI'69), Washington, D.C., May 7–9. Los Altos, CA: William Kaufmann, pp. 295–301.
Hobbs, J.R., 1979, “Coherence and coreference,” Cognitive Science, 3(1): 67–90.
–––, 2003, “The logical notation: Ontological promiscuity,” in J.R. Hobbs, Discourse and Inference (in progress). [Hobbs 2003 preprint available online].
Hobbs, J.R., D.E. Appelt, J. Bear, M. Kameyama, M.E. Stickel, and M. Tyson, 1997, “FASTUS: A cascaded finite-state transducer for extracting information from natural-language text,” in E. Roche and Y. Schabes (eds.), Finite-State Language Processing, Cambridge, MA: MIT Press, 383–406.
Hobbs, J.R. and A. Gordon, 2005, “Encoding knowledge of commonsense psychology,” in 7th International Symposium on Logical Formalizations of Commonsense Reasoning (Commonsense 2005), Corfu, Greece, May 22–24. [Hobbs and Gordon 2005 available online (pdf)]
Hobbs, J.R., M.E. Stickel, D.E. Appelt, and P. Martin, 1993, “Interpretation as abduction,” Artificial Intelligence, 63: 69–142.
Hoffmann, R., S. Amershi, K. Patel, F. Wu, J. Fogarty, and D. Weld, 2009, “Amplifying community content creation with mixed-initiative information extraction,” ACM Conference on Human Factors in Computing Systems (CHI 2009), Boston, MA, April 4–9. New York: ACM Press.
Hofstadter, D. R. and the Fluid Analogy Research Group, 1995, Fluid Concepts and Creative Analogies: Computer Models of the Fundamental Mechanisms of Thought, New York: Basic Books.
Hovy, E., 1988, “Planning coherent multisentential text,” in Proceedings of the 26th Annual Meeting of the ACL (ACL'88), Buffalo, NY. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 179–186. [Hovy 1988 available online (pdf)]
Humphrey, N., 1992, A History of the Mind: Evolution and the Birth of Consciousness, New York: Simon & Schuster.
Ide, N. and J. Véronis, 1994, “Knowledge extraction from machine-readable dictionaries: An evaluation”, in P. Steffens (ed.), Machine Translation and the Lexicon, Berlin: Springer-Verlag.
Jackendoff, R.S., 1990, Semantic Structures, Cambridge, MA: MIT Press.
Johnson-Laird, P.N., 1983, Mental Models: Toward a Cognitive Science of Language, Inference and Consciousness, Cambridge, MA: Harvard University Press.
Johnston, B. and M.-A. Williams, 2009, “Autonomous learning of commonsense simulations,” in Proceedings of Commonsense 2009, Toronto, Canada, June 1–3. Commonsense Reasoning. [Johnston and Williams 2009 available online (pdf)]
Jordan, P., M. Makatchev, U. Pappuswamy, K. VanLehn, and P. Albacete, 2006, “A natural language tutorial dialogue system for physics,” in G.C.J. Sutcliffe and R.G. Goebel (eds.), Proceedings of the 19th International Florida Artificial Intelligence Research Society (FLAIRS-06). Menlo Park, CA: AAAI Press.
Jurafsky, D. and J.H. Martin, 2009, Speech and Language Processing, 2nd edition. Upper Saddle River, NJ: Pearson Higher Education, Prentice-Hall; original edition, 2000, Upper Saddle River, NJ: Pearson Higher Education, Prentice-Hall.
Kamp, H., 1981, “A theory of truth and semantic representation,” in J. Groenendijk, T. Janssen, and M. Stokhof (eds.), Formal Methods in the Study of Language, Mathematics Center, Amsterdam.
Kasabov, N., 1996, Foundations of Neural Networks, Fuzzy Systems and Knowledge Engineering, Cambridge, MA: MIT Press.
Kecman, V., 2001, Learning and Soft Computing, Cambridge, MA: MIT Press.
Kim, J. and R.J. Mooney, 2012, “Unsupervised PCFG induction for grounded language learning with highly ambiguous supervision,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing and Natural Language Learning (EMNLP-CoNLL ‘12), July 12–14, Jeju, Korea. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Kim and Mooney 2012 available online (pdf)]
Koehn, Philipp, 2010, Statistical Machine Translation, Cambridge, UK: Cambridge University Press.
Kosslyn, S.M., 1994, Image and Brain: The Resolution of the Imagery Debate, Cambridge, MA: MIT Press.
Kuhlmann, M., 2013, “Mildly non-projective dependency grammar,” Computational Linguistics, 39(2): 355–387.
Lafferty, J., A. McCallum, and F. Pereira, 2001, “Conditional random fields: Probabilistic models for segmenting and labeling sequence data,” in C.E. Brodley and A. Pohoreckyj Danyluk (eds.), International Conference on Machine Learning (ICML), Williams College, MA, June 28–July 1. San Francisco: Morgan Kaufmann.
Lakoff, G. and M. Johnson, 1980, Metaphors We Live By, Chicago: University of Chicago Press.
Landman, F., 1991, Structures for Semantics, SLAP 45, Dordrecht: Kluwer.
Landman, F., 1989, “Groups I & II”, Linguistics and Philosophy, 12(5): 559–605 and 12(6): 723–744.
–––, 2000, Events and Plurality, Dortrecht: Kluwer.
Lenat, D., 1995, “CYC: A large-scale investment in knowledge infrastructure,” Communications of the ACM, 38(11): 33–38.
Lewis, D.K., 1970, “General semantics,” Synthese, 22: 18–67. Reprinted in D. Davidson and G. Harman (eds.), 1972, Semantics of Natural Language, Dortrecht: D. Reidel.
Lieberman, H., H. Liu, P. Singh, and B. Barry, 2004. “Beating some common sense into interactive applications,” AI Magazine, 25(4): 63–76.
Lin, D. and P. Pantel, 2001, “DIRT—Discovery of Inference Rules from Text,” in Proceedings of the 7th ACM Conference on Knowledge Discovery and Data Mining (KDD-2001), San Francisco, CA, August 26–29. New York: ACM Digital Library, pp. 323–328.
Lindsay, R., 1963, “Inferential memory as the basis of machines which understand natural language”, in E. Feigenbaum and J. Feldman (eds.), Computers and Thought, New York: McGraw-Hill.
Link, G. 1983, “The logical analysis of plurals and mass terms: a lattice-theoretical approach”, in R. Bauerle, C. Schwarze, and and A. von Stechow (eds.), Meaning, Use, and Interpretations of Language, Berlin: de Gruyter.
Litman, D.J. and S. Silliman, 2004, “ITSPOKE: An intelligent tutoring spoken dialogue system,” in Proceedings of the Human Language Technology Conference: 4th Meeting of the North American Chapter of the Association for Computational Linguistics (HLT/NAACL-04). Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 233–236. [Litman and Silliman 2004 available online (pdf)]
MacCartney, B. and C.D. Manning, 2009, “An extended model of natural logic,” in Proceedings of the 8th International Conference on Computational Semantics (IWCS-8), Tilburg University, Netherlands. Stroudsburg, PA: Association for Computational Linguistics (ACL). [MacCartney and Manning 2009 available online (pdf)]
Manger, R., V.L. Plantamura, and B. Soucek, 1994, “Classification with holographic neural networks,” in V.L. Plantamura, B. Soucek, and G. Visaggio (eds.), Frontier Decision Support Concepts, New York: John Wiley and Sons, 91–106.
Mann, W. and S.A. Thompson, 1987, “Rhetorical structure theory: description and construction of text structures,” in G. Kempen (ed.), Natural Language Generation: Recent Advances in Artificial Intelligence, Psychology, and Linguistics, Dortrecht: Kluwer Academic Publishers, 85–96.
Mann, W.C. and S.A. Thompson, 1988, “Rhetorical Structure Theory: toward a functional theory of text organization.” Text, 8(3): 243–281.
Manning, C.D. and H. Schütze, 1999, Foundations of Statistical Natural Language Processing, Cambridge, MA: MIT Press.
Markert, K. and M. Nissim, 2007, “SemEval-2007 Task 08: metonymy resolution at SemEval-2007,” in Proceedings of SemEval 2007, Prague. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Markert and Nissim 2007 available online (pdf)]
Martin, J.H., 1990, A Computational Model of Metaphor Interpretation, New York: Academic Press.
Massaro, D.W., M.M. Cohen, M. Tabain, J. Beskow, and R. Clark, 2012, “Animated speech: Research progress and applications,” in G. Bailly, P. Perrier, and E. Vatiokis-Bateson (eds.), Audiovisual Speech Processing, Cambridge, UK: Cambridge University Press, 309–345.
May, A., 2012, “Machine translation,” chapter 19 of A. Clark, C. Fox, and S. Lappin (eds.), The Handbook of Computational Linguistics and Natural Language Processing, Chichester, UK: Wiley Blackwell.
Mayberry, III, M.R. and R. Miikkulainen, 2008, “Incremental nonmonotonic sentence interpretation through semantic self-organization,” Technical Report AI08-12, Dept. of Computer Science, University of Texas, Austin, TX.
Maybury, M.T. (ed.), 2004, New Directions in Question Answering, Cambridge, MA: AAAI and MIT Press.
McCarthy, J., 1990, “First order theories of individual concepts and propositions,” in J. McCarthy and V. Lifschitz (eds.), 1990, Formalizing Common Sense: Papers by John McCarthy, 119–141. (Note: An earlier version appeared in J.E. Hayes, D. Michie, and L. Mikulich (eds.), 1979, Machine Intelligence 9, Chichester/Halsted, New York: Ellis Norwood, 129–148. [See also the [most recent version, 2000.]
McClain, M. and S. Levinson, 2007, “Semantic based learning of syntax in an autonomous robot,” International Journal of Humanoid Robotics, 4(2): 321–346.
McCord, M., 1986, “Focalizers, the scoping problem, and semantic interpretation rules in logic grammars,” in M. Van Caneghem and D.H.D. Warren (eds.), Logic Programming and its Applications, Norwood, NJ: Ablex, 223–243.
McKeown, K.R., 1985, Text Generation: Using Discourse Strategies and Focus Constraints to Generate Natural Language Text, Cambridge, UK: Cambridge University Press.
Minsky, M., 1968, Semantic Information Processing, Cambridge, MA: MIT Press.
Moldovan, D.I. and V. Rus, 2001, “Logic form transformation of WordNet and its applicability to question answering,” in Proceedings of ACL 2001, Association for Computational Linguistics, Toulouse, France, July 6–11. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 402–409. [Moldovan and Rus 2001 available online (pdf)]
Montague, R., 1970, “English as a formal language,” in B. Visentini et al. (eds.), Linguaggi nella società e nella tecnicà, Milan: Edizioni di Comunita, 189–224.
–––, R., 1973, “The proper treatment of quantification in ordinary English,” in K.J.J. Hintikka, J.M.E. Moravcsik, and P. Suppes (eds.), Approaches to Natural Language, Dortrecht: D. Reidel.
Mooney, R.J., 2007, “Learning for semantic parsing,” in A. Gelbukh (ed.), Proceedings of the 8th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2007), Mexico City, February. Berlin: Springer, pp. 311–324.
Moore, J.D. and C.L. Paris, 1988, “Constructing coherent texts using rhetorical relations,” in Proceedings of the 10th Annual Conference of the Cognitive Science Society (COGSCI-88), Montreal, Canada, August 17–19. New York: Taylor & Francis, pp. 199–204.
–––, 1993, “Planning texts for advisory dialogues: capturing intentional and rhetorical information,” Computational Linguistics, 19(4): 651–694.
Mostow, J. & J. Beck, 2007, “When the rubber meets the road: Lessons from the in-school adventures of an automated reading tutor that listens,” in B. Schneider & S.-K. McDonald (eds.), Scale-Up in Education (Vol. 2), Lanham, MD: Rowman & Littlefield Publishers, 183–200.
Movellan, J.R., M. Eckhardt, M. Virnes, and A. Rodriguez, 2009, “Sociable robot improves toddler vocabulary skills,” in Proceedings of the International Conference on Human Robot Interaction (HRI2009), San Diego, CA, March 11–13. New York: ACM Digital Library.
Narayanan, S., 1997, KARMA: Knowledge-based Action Representations for Metaphor and Aspect, Doctoral thesis, U.C. Berkeley, CA.
Newell, A. and H.A. Simon, 1976, “Computer science as empirical inquiry: symbols and search,” Communications of the ACM, 19(3): 113–126.
Nielsen, L.A., 2004, “Verb phrase ellipsis detection using automatically parsed text”, in Proceedings of the 20th International Conference on Computational Linguistics (COLING'04), Geneva, Switzerland. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Nielsen 2004 available online (pdf)]
Norman, D.A., D.E. Rumelhart, and the LNR Research Group, 1975, Explorations in Cognition, New York: W.H. Freeman and Company.
Onyshkevych, B., 1998, “Nominal metonymy processing,” COLING-ACL Workshop on the Computational Treatment of Nominals, Aug. 10–14, Quebec, Canada. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Onyshkevych 1998 available online (pdf)]
Paivio, A., 1986, Mental representations: a dual coding approach, Oxford, England: Oxford University Press.
Palmer, M., D. Gildea, and N. Xue, 2010, Semantic Role Labeling, San Rafael, CA: Morgan & Claypool.
Palmer-Brown, D., J.A. Tepper, and H.M. Powell, 2002, “Connectionist natural language parsing,” Trends in Cognitive Sciences 6(October): 437–442.
Pantel, P., R. Bhagat, B. Coppola, T. Chklovski, and E. Hovy, 2007, “ISP: Learning Inferential Selectional Preferences,” in Proceedings of North American Association for Computational Linguistics / Human Language Technology (NAACL-HLT'07), Rochester, NY. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 564–571. [Pantel et al. 2007 available online (pdf)]
Parsons, T., 1990, Events in the Semantics of English: A Study in Subatomic Semantics, Cambridge, MA: MIT Press.
Pereira, F.C.N. and D.H.D. Warren, 1982, “An efficient easily adaptable system for interpreting natural language queries,” American Journal of Computational Linguistics, 8(3–4): 110–122.
Pierce, J.R., J.B. Carroll, et al., 1966, Language and Machines—Computers in Translation and Linguistics. ALPAC report, National Academy of Sciences, National Research Council, Washington, DC.
Pinker, S., 1994, The Language Instinct, New York: Harper.
–––, 2007, The Stuff of Thought, New York: Penguin Group.
Plate, T.A., 2003, Holographic Reduced Representation: Distributed Representation for Cognitive Structures, Stanford, CA: CSLI Publications.
Poincaré, H., 1913, “Mathematical creation,” in H. Poincaré (with an introduction by J. Royce), The Foundations of Science: Science and Method, Book I (Science and the Scientist), chapter III, New York: The Science Press.
Pon-Barry, H., K. Schultz, Owen E. Bratt, B. Clark, and S. Peters, 2006, “Responding to student uncertainty in spoken tutorial dialogue systems,” International Journal of Artificial Intelligence in Education, 16(2): 171–194.
Poon, H., 2013, “Grounded unsupervised semantic parsing,” in Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL-13), Sofia, Bulgaria, Aug. 4–9. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Poon 2013 available online (pdf)]
Poon, H. and P. Domingos, 2009, “Unsupervised semantic parsing,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore, Aug. 6–7. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Poon and Domingos 2009 available online (pdf)]
Pullum, G., 2011, “Remarks by Noam Chomsky in London”, Linguist, November 14, 2011, 22.4631. [Pullum 2011 available online]
Pulman, S., J. Boye, M. Cavazza, Smith and C. R. Santos de la Cámara, 2010, “How was your day?” in Proceedings of the 2010 Workshop on Companionable Dialogue Systems, Uppsala, Sweden, July. Stroudsburg, PA: Association for Computational Linguistics, 37–42.
Quillian, M.R., 1968, “Semantic memory,” in M. Minsky (ed.) Semantic Information Processing, Cambridge, MA: MIT Press, 227–270.
Ramsay, W., S.P. Stich, and J. Garon, 1991, “Connectionism, eliminativism and the future of folk psychology,” in W. Ramsay, S.P. Stich, and D.E. Rumelhart (eds.), Philosophy and Connectionist Theory, Hillsdale, NJ: Lawrence Erlbaum.
Rapaport, W.J., 1995, “Understanding understanding: Syntactic semantics and computational cognition,” in J.E. Tomberlin (ed.), AI, Connectionism, and Philosophical Psychology, Philosophical Perspectives, Vol. 9, Atascadero, CA: Ridgeview Publishing, 49–88.
Raphael, B., 1968, “SIR: A computer program for semantic infomation retrieval,” in M. Minsky (ed.) Semantic Information Processing, Cambridge, MA: MIT Press, 33–145.
Ratnaparkhi A., 1997, “A simple introduction to maximum entropy models for natural language processing”, Technical Report 97–08, Institute for Research in Cognitive Science, University of Pennsylvania.
Reichenbach, H., 1947, Elements of Symbolic Logic, New York: MacMillan.
Rich, C. and C.L. Sidner, 1998, “COLLAGEN: A collaboration manager for software interface agents,” User Modeling and User-Adapted Interaction, 8(3–4): 315–350.
Robinson, D.N., 2007, Consciousness and Mental Life, New York, NY: Columbia University Press.
Rumelhart, D.E., P.H. Lindsay, and D.A. Norman, 1972, “A process model for long-term memory,” in E. Tulving and W. Donaldson, Organization and Memory, New York: Academic Press, 197–246.
Rumelhart, D.E. and J. McClelland, 1986, Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Cambridge, MA: MIT Bradford Books.
Salton, G., 1989, Automatic Text Processing: The Transformation, Analysis and Retrieval of Information by Computer, Boston, MA: Addison-Wesley.
Scha, R., 1981, “Distributive, collective and cumulative quantification,” in J. Groenendijk, T. Janssen, and M. Stokhof (eds.), Formal Methods in the Study of Language, Amsterdam: Mathematical Centre Tracts.
Schank, R.C. and R.P. Abelson, 1977, Scripts, Plans, Goals and Understanding, Hillsdale, NJ: Lawrence Erlbaum.
Schank, R.C. and K.M. Colby, 1973, Computer Models of Thought and Language, San Francisco: W.H. Freeman and Co.
Schank, R.C. and C.K. Riesbeck, 1981, Inside Computer Understanding, Hillsdale, NJ: Lawrence Erlbaum.
Scheutz, M., R. Cantrell, and P. Schermerhorn, 2011 “Toward human-like task-based dialogue processing for HRI,” AI Magazine 32(4): 77–84.
Schoenmackers, S., J. Davis, O. Etzioni, and D.S. Weld, 2010, “Learning first-order Horn clauses from Web text,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2010), MIT, MA, Oct. 9–11. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Schoenmackers et al. available online (pdf)]
Schubert, L.K., 2000, “The situations we talk about”, in J. Minker (ed.), Logic-Based Artificial Intelligence, Dortrecht: Kluwer, 407–439.
–––, 2007, “Implicit Skolemization: efficient reference to dependent entities,” Research on Language and Computation 5, April, (special volume on Binding Theory, edited by A. Butler, E. Keenan, J. Mattausch and C.-C. Shan): 69-86.
Schubert, L.K. and F.J. Pelletier, 1982, “From English to logic: Context-free computation of ‘conventional’ logical translations”, American Journal Computational Linguistics, 8: 27–44; reprinted in B.J. Grosz, K. Sparck Jones, and B.L. Webber (eds.), 1986, Readings in Natural Language Processing, Los Altos, CA: Morgan Kaufmann, 293–311.
Schubert, L.K. and M. Tong, 2003, “Extracting and evaluating general world knowledge from the Brown Corpus,” in Proceedings of the HLT-NAACL Workshop on Text Meaning, Edmonton, Alberta, May 31. Stroudsburg, PA: Association for Computational Linguistics (ACL), 7–13. [Schubert and Tong 2003 available online (pdf)]
Searle, J., 1969, Speech Acts, Cambridge, UK: Cambridge University Press.
Sebestyen, G.S., 1962, Decision-Making Processes in Pattern Recognition, New York: Macmillan.
Sha, F. and F. Pereira, 2003, “Shallow parsing with conditional random fields,” Human Language Technology Conference (HLT-NAACL 2003), May 27 – June 1, Edmonton, Canada. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Sha and Pereira 2003 available online (pdf)]
Singh, P., T. Lin, E.T. Mueller, G. Lim, T. Perkins, and W.l. Zhu, 2002, “Open Mind Common Sense: Knowledge acquisition from the general public,” in Proceedings of the 1st International Conference on Ontologies, Databases, and Applications of Semantics for Large Scale Information Systems (ODBASE 2002), Irvine, California, October 29–31. Lecture Notes in Computer Science, Volume 2519, New York: Springer, pp. 1223–1237.
Smith, R.W., D.R. Hipp, and A.W. Biermann, 1995, “An architecture for voice dialogue systems based on Prolog-style theorem proving,” Computational Linguistics, 21: 281–320.
Smolensky, P., 1988, “On the proper treatment of connectionism,” The Behavioral and Brain Sciences, 11: 1–23.
Smolensky, P., G. Legendre, and Y. Miyata, 1992, “Principles for an integrated connectionist and symbolic theory of higher cognition,” Technical Report CU-CS-600-92, Computer Science Department, University of Colorado, Boulder, CO.
Snow, R., B. O'Connor, D. Jurafsky, and A.Y. Ng, 2008, “Cheap and fast—but is it good? Evaluating non-expert annotations for natural language tasks,” in Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP 2008), Waikiki, Honolulu, Oct. 25–27. Stroudsburg, PA: Association for Computational Linguistics (ACL), 254–263. [Snow et al. 2008 available online (pdf)]
Steedman, Mark, 2007, “Presidential Address to the 45th Annual Meeting of the ACL”, Prague, June 2007. Also printed in 2008, “On becoming a discipline”, Computational Linguistics, 34(1): 137–144. [Steedman 2007 [2008] available online]
Sun, R., 2001, “Hybrid systems and connectionist implementationalism” (also listed as 2006, “Connectionist implementationalism and hybrid systems,”), in L. Nadel (ed.) Encyclopedia of Cognitive Science, London, UK: MacMillan.
Tenenbaum, J. B., C. Kemp, T.L. Griffiths, and N.D. Goodman, 2011, “How to grow a mind: Statistics, structure, and abstraction,” Science, 331: 1279–1285.
Thompson, F.B., P.C. Lockermann, B.H. Dostert, and R. Deverill, 1969, “REL: A rapidly extensible language system,” in Proceedings of the 24th ACM National Conference, New York: ACM Digital Library, pp. 399–417.
Thompson, F.B. and B.H. Thompson, 1975, “Practical natural language processing: The REL system as prototype,” in M. Rubinoff and M.C. Yovits (eds.), Advances in Computers, vol. 13, New York: Academic Press, 109–168.
Turney, P.D., 2008, “The Latent Relation Mapping Engine: algorithm and experiments,” Journal of Artificial Intelligence Research, 33: 615–655.
Van Durme, B., P. Michalak, and L.K. Schubert, 2009, “Deriving generalized knowledge from corpora using WordNet abstraction”, 12th Conference of the European Chapter of the Association for Computational Linguistics (EACL-09), Athens, Greece, Mar. 30–Apr. 3. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Van Durme, Michalak and Schubert 2009 available online (pdf)]
Veale, T. and Y. Hao, 2008, “A fluid knowledge representation for understanding and generating creative metaphors,” The 22nd International Conference on Computational Linguistics (COLING 2008), Manchester, UK, Aug. 18–22. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 945–952. [Veale and Hao 2008 available online (pdf)]
Vijay-Shankar, K. and D.J. Weir, 1994, “Parsing some constrained grammar formalisms,” Computational Linguistics, 19(4): 591–636.
von Ahn, L., M. Kedia, and M. Blum, 2006, “Verbosity: A game for collecting common-sense knowledge,” in R. Grinter, T. Rodden, P. Aoki, E. Cutrell, R. Jeffries, and G. Olson (eds.), Proceedings of the SICHI Conference on Human Factors in Computing Systems (CHI 2006), Montreal, Canada, April 22–27. New York: ACM Digital Library, pp. 75–78.
Weischedel, R.M. and N.K. Sondheimer, 1983, “Meta-rules as a basis for processing ill-formed input,” American Journal of Computational Linguistics, 9(3–4): 161–177.
Widdows, D., 2004, Geometry and Meaning, Stanford, CA: CSLI Publications.
Wilks, Y., 1978, “Making preferences more active,” Artificial Intelligence, 11(3): 197–223; also in N.V. Findler (ed.), 1979, Associative Networks: Representation and Use of Knowledge, Orlando, FL: Academic Press, 239–266.
–––, 2010, “Is a companion a distinctive kind of relationship with a machine?” in Proceedings of the 2010 Workshop on Companionable Dialogue Systems, (CDS ‘10), Uppsala, Sweden. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 13–18. [Wilks 2010 available online (pdf)]
Winograd, T., 1972, Understanding Natural Language, New York: Academic Press.
Woods, W.A., R.M. Kaplan, B.L. Nash-Webber, 1972, “The Lunar Sciences Natural Language Information System: Final Report”, BBN Report No. 2378, Bolt Beranek and Newman Inc., Cambridge, MA. (Available from NTIS as N72-28984.)
Yarowsky, D., 1992, “Word-sense disambiguation using statistical models of Roget's categories trained on large corpora,” in Proceedings of the 14th International Conference on Computational Linguistics (COLING-92), Nantes, France. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 454–60. [Yarowsky 1992 available online (pdf)]
Younger, D.H., 1967, “Recognition and parsing of context-free languages in time _n_3,” Information and Control, 10(2): 189–208.
Zettlemoyer, L.S. and M. Collins, 2007, “On-line learning of relaxed CCG grammars for parsing to logical form,” in Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL 2007), Prague, June 28–30. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Zettlemoyer and Collins 2007 available online (pdf)]
Academic Tools
Other Internet Resources
Cognitive Assistant that Learns and Organizes (CALO), SRI International Artificial Intelligence Center.
Large-scale QA systems: A very readable and cogent comparison of the approaches to QA in Wolfram|Aplha and IBM's Watson, with suggestive architectural flowcharts, can be found at http://blog.stephenwolfram.com/2011/01/jeopardy-ibm-and-wolframalpha/.
Related Entries
anaphora | artificial intelligence | artificial intelligence: logic-based | cognitive science | connectionism | discourse representation theory | linguistics: philosophy of | logical form | semantics: dynamic | semantics: Montague | situations: in natural language semantics
Acknowledgments
The author and editors would like to thank an anonymous external referee for the time he spent and the advice he gave us for improving the presentation in this entry.
Copyright © 2014 by Lenhart Schubert <schubert@cs.rochester.edu>
最后更新于

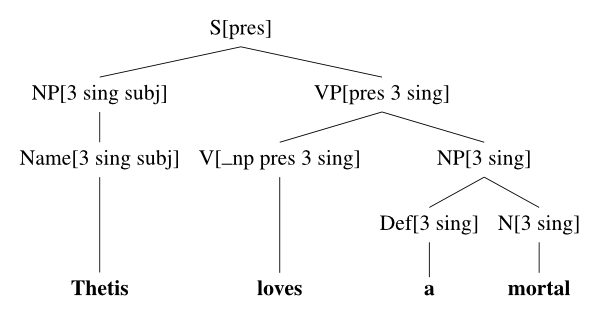{kind=link}
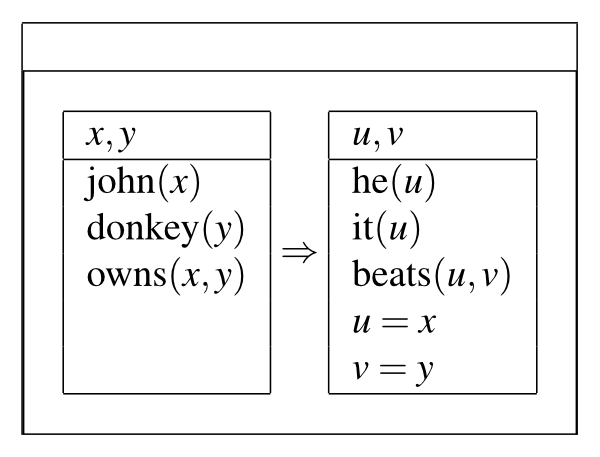{kind=link}
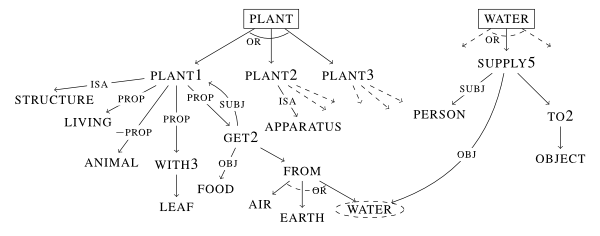{kind=link}
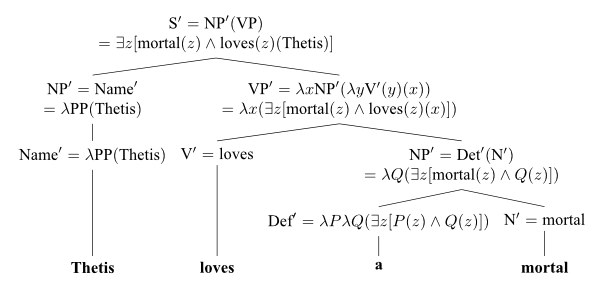{kind=link}